BitTorrent Enters the AI Computing Space: BTTInferGrid Builds a Decentralized AI Inference Computing Network
TechFlow Selected TechFlow Selected
BitTorrent Enters the AI Computing Space: BTTInferGrid Builds a Decentralized AI Inference Computing Network
BTTInferGrid aims to build a decentralized computing power network for AI inference scenarios, connecting global idle GPU computing resources with the market demand for AI inference computing power.
As AI agents are increasingly deployed in enterprise workflows, automated production, and autonomous execution across diverse complex scenarios, the global AI industry has officially transitioned from “passive response” to a new era of “autonomous execution.” The core of industry competition has long moved beyond mere comparisons of large-model parameter counts and shifted toward a contest of real-world implementation capabilities—where robust logical reasoning serves as the foundational pillar enabling this transformation.
This paradigm shift in application scenarios is also driving a fundamental change in upstream computing infrastructure demand: computational consumption is steadily shifting from model training to inference—and this trend is now irreversible. However, today’s mainstream centralized computing systems face mounting challenges when confronted with massive, high-frequency, and highly volatile inference requests—exhibiting high operational costs, weak elastic scalability, and insufficient service stability. The entire AI industry is now encountering a critical bottleneck in computing supply.
On June 17, BitTorrent—the veteran decentralized transmission ecosystem—launched its strategic flagship product, BTTInferGrid, targeting the AI inference sector and building a decentralized computing network. Leveraging a decentralized, distributed architecture, BTTInferGrid efficiently aggregates fragmented, underutilized GPU resources worldwide, bridging the gap between resource suppliers and AI developers. It delivers open, easy-to-integrate AI inference services—with results verifiable on-chain and flexible pay-per-use pricing.

By capitalizing on its decentralized technical advantages, BTTInferGrid not only addresses key weaknesses of traditional centralized computing systems—including poor performance under high concurrency and fluctuating workloads—but also achieves a quantum leap on the supply side, fundamentally reshaping how computing resources are allocated and circulated across the entire ecosystem.
Meanwhile, BTTInferGrid is a strategic upgrade built upon BitTorrent’s existing BTFS service—a pivotal extension of BitTorrent’s deep expertise in decentralized resource orchestration from the storage domain into the computing space, and a decisive move into the decentralized AI landscape.
Computing Demand Shifts from “Training” to “Inference”: BTTInferGrid Redefines AI Inference Supply via Decentralization
BTTInferGrid aims to reconstruct the computing supply system using a decentralized model, tackling issues such as prohibitively high inference costs and supply shortages. By reducing costs while boosting efficiency—and simultaneously enhancing large-model inference speed—it delivers high-performance, resilient, and cost-effective computing infrastructure for the industry.

If 2024–2025 marked the AI industry’s “thousand-model race” and GPU-cluster-driven arms race over parameters, then 2026—amid the large-scale deployment of AI agents—ushers in the “inference era,” characterized by explosive, mass-market AI adoption. AI inference is the critical link where model value becomes tangible: it transforms “pre-trained models” into real-world applications, commercial value, and everyday services. Put simply, training is “teaching AI to learn,” while inference is “enabling AI to act”—for example, an autonomous vehicle recognizing a stop sign on an unfamiliar road is a classic inference task. Inference capability directly determines user experience, operational costs, and commercial viability of AI products.
An industry consensus holds that over 70% of future computing resources will be dedicated to inference. Oracle once projected that the inference computing market will ultimately surpass training in scale. Academician Wei-Min Zheng of the Chinese Academy of Engineering similarly noted that most current computing resources are consumed in daily interactions between users and large models. From a cost-structure perspective, inference expenses for large models allocate just 3% to labor, 2% to data, and a staggering 95% to computing power. Top-tier applications bear significant compute costs: ChatGPT incurs roughly $700,000 daily in inference expenses, while DeepSeek V3 reaches $87,000.
As AI computing demand expands—from concentrated training by a few tech giants—to commercial inference use cases across millions of developers in every industry—the evaluation criteria for underlying infrastructure have also changed. In the training era, developers prioritized centralized scale and efficiency. In the inference era, AI services serve vast end-user bases—generating trillions of daily interactions and enormous compute loads—shifting developer focus to per-call cost, response latency, and service reliability. Today, computing supply, invocation cost, and service availability have become core metrics for evaluating AI infrastructure—and decisive factors determining whether AI applications can successfully go to market.
Yet, against exponentially rising inference demand, the shortcomings of mainstream centralized computing systems are becoming increasingly acute: GPU rental prices keep climbing, platform outages occur frequently, and many AI applications are forced to shut down due to unsustainable compute costs. These problems manifest in three key areas:
First, inflexible compute scheduling fails to adapt to traffic peaks and troughs—trapping operators in a trade-off between cost and stability: While leading AI companies and cloud providers continue ramping up infrastructure investment, inference demand grows rapidly and exhibits pronounced peak-valley patterns—requests may surge dozens of times during daytime office or marketing hours, then plummet overnight. Centralized data centers lack elastic scheduling capabilities to match this dynamism: provisioning for peak demand leads to costly underutilization during off-peak periods; provisioning for average demand causes service outages during peaks—creating a vicious cycle of “high cost” and “low stability.” Moreover, centralized compute stacks multiple layers of cost—including data center construction, electricity, operations, and commercial margins—driving final compute costs skyward and severely constraining experimentation space for smaller innovators. The market urgently needs new solutions combining cost efficiency with elastic scheduling.
Second, soaring GPU rental prices hinder innovation by SMEs and developers: Open-source large models (e.g., Qwen, DeepSeek) have lowered entry barriers into AI, yet deploying and running them still relies on stable, affordable, and easily accessible inference computing. Reality paints a different picture: GPU rental fees keep rising. For instance, the hourly rate for a mainstream H100 GPU climbed from $1.70 in October 2025 to $2.35 in March 2026—a near 40% increase in six months. Such high costs deter many individual developers and SMEs holding promising solutions, trapping them in a “models without compute” dilemma and severely stifling AI innovation vitality and scalable growth.
Third, globally abundant idle GPU resources remain underutilized—causing severe supply-demand mismatches: Contrasting sharply with the market’s “compute shortage” is the existence of massive volumes of idle, high-performance GPU resources scattered across personal devices, university labs, small data centers, and legacy crypto-mining facilities. Lacking standardized access channels and efficient scheduling engines, these resources cannot enter mainstream inference markets—resulting in a paradoxical coexistence of “GPU scarcity on the demand side” and “dormant compute on the supply side.” Resource utilization potential remains enormous, and this mismatch urgently requires resolution.
In summary, today’s AI inference computing market faces three structural bottlenecks: centralized supply struggles to balance cost and elasticity; escalating compute rents suppress AI innovation; and vast quantities of idle GPUs lie dormant and unactivated. Confronting these industry-wide challenges, BTTInferGrid leverages decentralization to deliver a novel solution to the supply-demand mismatch.
BTTInferGrid aims to connect globally dispersed idle GPU resources with the massive pool of AI developers through decentralization—fundamentally breaking centralized computing monopolies and bottlenecks. On one hand, it aggregates fragmented idle GPU resources to build an open, shared computing infrastructure. On the other, it bridges the gap between supply and demand—eliminating the access barriers and opaque pricing inherent in centralized models. Furthermore, powered by DePIN’s incentive and coordination mechanisms, BTTInferGrid continuously delivers high-value-for-money inference computing—directly resolving the twin pain points of exorbitant costs and supply shortages, thereby unlocking the full inference performance and commercial potential of large models.
BTTInferGrid: Building a Decentralized Compute Network for AI Inference—Three Advantages Redefining Compute Allocation
BTTInferGrid has a clear and precise positioning: it focuses exclusively on building a decentralized compute network tailored for AI inference—connecting global idle GPU supply with AI inference demand—and delivering a global AI compute service ecosystem characterized by open access, on-chain verifiability, and pay-per-use pricing.
Specifically, BTTInferGrid leverages DePIN’s underlying network mechanisms to precisely match compute supply with the explosive growth in AI inference demand—delivering bidirectional value creation for both supply and demand sides:
- On the supply side, it efficiently aggregates fragmented, idle GPU resources worldwide to build an open, shared compute foundation. Simultaneously, DePIN’s incentive and intelligent scheduling mechanisms open low-barrier, sustainable monetization pathways for compute holders—transforming globally idle “dormant GPUs” into “liquid assets.” This also ensures compute stability and elastic scalability, establishing a globally distributed, high-value-for-money, highly extensible, secure, and reliable inference service capability.
- On the demand side, it offers global AI developers convenient access, on-chain verifiable results, and flexible pay-per-use inference services. Compared to premium-priced offerings from centralized cloud vendors, BTTInferGrid delivers extreme cost advantages and elastic scaling capacity—helping SMEs and independent developers reduce trial-and-error costs, accelerate product validation, and iterate business models more efficiently, while reciprocally empowering upstream compute supply ecosystems.
Thus, BTTInferGrid not only meets AI developers’ urgent need for low-cost, highly elastic computing during the “application battleground” phase—but also unlocks sustainable monetization avenues for the world’s vast pool of idle hardware resources.
More importantly, BTTInferGrid successfully establishes a self-sustaining, positive-feedback growth flywheel: expanding idle GPU nodes continuously lower inference costs, attracting more developers; rising demand further incentivizes global compute suppliers to join the ecosystem. By restructuring compute supply through decentralization, BTTInferGrid transforms scarce, expensive, specialized AI compute into inclusive, on-demand public infrastructure—the foundational layer of AI.
From a product performance standpoint, most existing decentralized GPU platforms suffer from high compute-access barriers, insufficient service trustworthiness, and unsustainable economic models. BTTInferGrid, however, optimizes at the architectural level—achieving comprehensive breakthroughs across three dimensions: compute aggregation, service verification, and economic sustainability—forming unique competitive advantages:
1. An openly accessible compute supply network rapidly aggregates global idle GPU resources: Traditional cloud compute imposes high entry barriers (e.g., compliant data centers, fixed public IP addresses, expensive switches). BTTInferGrid builds a truly open-access compute supply network—any entity or individual possessing idle GPU or other compute resources can seamlessly join, provided they meet basic performance requirements (e.g., VRAM capacity, compute benchmarks) and network stability standards. This design dramatically lowers participation thresholds on the supply side—enabling ultra-rapid, networked, matrix-style aggregation of idle global GPU resources.
2. Verifiable service quality and node behavior—solving decentralized trust challenges: The biggest pain point of decentralized computing lies in trustworthiness—how to prevent miners from masquerading low-end GPUs as high-performance ones? How to ensure inference results are genuinely credible? BTTInferGrid constructs a cross-verifiable closed loop through task scheduling (intelligent distribution), challenge verification (cryptographic spot-checks), consensus scoring (dynamic reputation scores), and on-chain coordination (smart-contract-based rewards and penalties)—significantly enhancing inference service trustworthiness.
3. A demand-driven economic model fostering sustainable ecology: Early DePIN projects often fell into a “death spiral”: excessive token emissions attracted nodes to mine recklessly, but lacking real demand led to token inflation, price crashes, and node exits. BTTInferGrid established from inception a demand-driven economic ecosystem—grounding incentives firmly on actual inference calls and node performance. Only when AI developers pay to invoke models do compute providers earn core revenue shares and reputation boosts. This design strongly promotes healthy, mutually reinforcing growth between supply scale and market demand—ensuring long-term ecological health and sustainability.
In summary, from dismantling traditional access barriers to enable seamless integration of any globally idle GPU meeting performance standards, to constructing a full-lifecycle verifiable trust framework via four interlocking layers—task scheduling, challenge verification, consensus scoring, and on-chain reward/penalty enforcement—to abandoning speculative bubbles entirely and anchoring incentives squarely on authentic AI inference usage—BTTInferGrid is redefining compute resource allocation across three dimensions: resource aggregation, service trustworthiness, and value distribution.
BTTInferGrid Phased Rollout of a Demand-Driven Compute Ecosystem
BTTInferGrid is far more than simple “compute aggregation.” It is a sophisticated, decentralized compute network integrating AI inference task scheduling and execution, intelligent matching and connection between compute supply and demand, and on-chain resource coordination and settlement.
Within BTTInferGrid’s decentralized compute ecosystem, all participants form three core roles centered around compute “supply, usage, and verification”:
- Compute Suppliers (Miners): Provide idle GPU resources to accept and execute AI inference tasks. The system automatically allocates rewards based on verified workload, task completion quality, and dynamic performance scoring.
- Compute Consumers (AI Developers): BTTInferGrid provides standardized, unified API interfaces enabling developers to access globally distributed GPU resources.
- Network Guardians (Verifiers): Participate in the decentralized verification and scoring system—auditing and randomly challenging miner nodes’ computational performance, identifying anomalies, and maintaining service quality. Verifiers receive rewards for upholding network integrity, jointly ensuring fairness and trustworthiness.
In summary, for AI developers, BTTInferGrid delivers AI inference services with superior cost-efficiency, high scalability, and strong security—effectively mitigating product disruptions and customer attrition caused by compute shortages. For GPU providers, it activates globally distributed edge and idle hardware resources—establishing a sustainable revenue channel for GPU owners and ensuring every unit of compute realizes its full value in the inference era.
For concrete product rollout, unlike traditional centralized cloud vendors’ “build-first, wait-for-demand” capital-intensive model, DePIN networks inherently face two-way coordination challenges at launch—oversupply risks idle nodes and token-economy collapse, while undersupply harms developer experience and system efficiency. To address this, BTTInferGrid adopts a clear, robust, demand-oriented phased launch strategy—rejecting chaotic, indiscriminate growth in favor of steady expansion focused on resource utilization, economic sustainability, and technological architecture resilience.
- Short-term goal (2026): Cold-start the network—complete onboarding of core underlying nodes and validate distributed inference services—gradually scaling GPU node count.
- Mid-term goal (2027): Diversify the ecosystem—enhance network service stability and privacy security; broaden compatibility with more AI model formats and inference frameworks; progressively extend into application scenarios like model fine-tuning.
- Long-term goal (2028 and beyond): Become native AI infrastructure—establish itself as the preferred compute layer for AI agents and automation applications, delivering elastic compute support for large-scale AI deployments, ultimately enabling coordinated operation of compute, decentralized storage, and on-chain smart contracts within a unified architecture.
In execution, BTTInferGrid likewise follows a phased evolution strategy. At initial launch, the network primarily supports professional-grade GPUs, with miner onboarding subject to review, while demand-side users access inference services via the platform. Going forward, it will evolve into a fully open super-compute grid—supporting consumer-grade, professional-grade, and data-center-grade GPUs alike, with tiered access and pricing based on performance; opening miner onboarding while introducing staking mechanisms to guarantee service quality; and offering demand-side developers a unified API interface compatible with multiple AI model formats and inference frameworks—providing flexible deployment options.
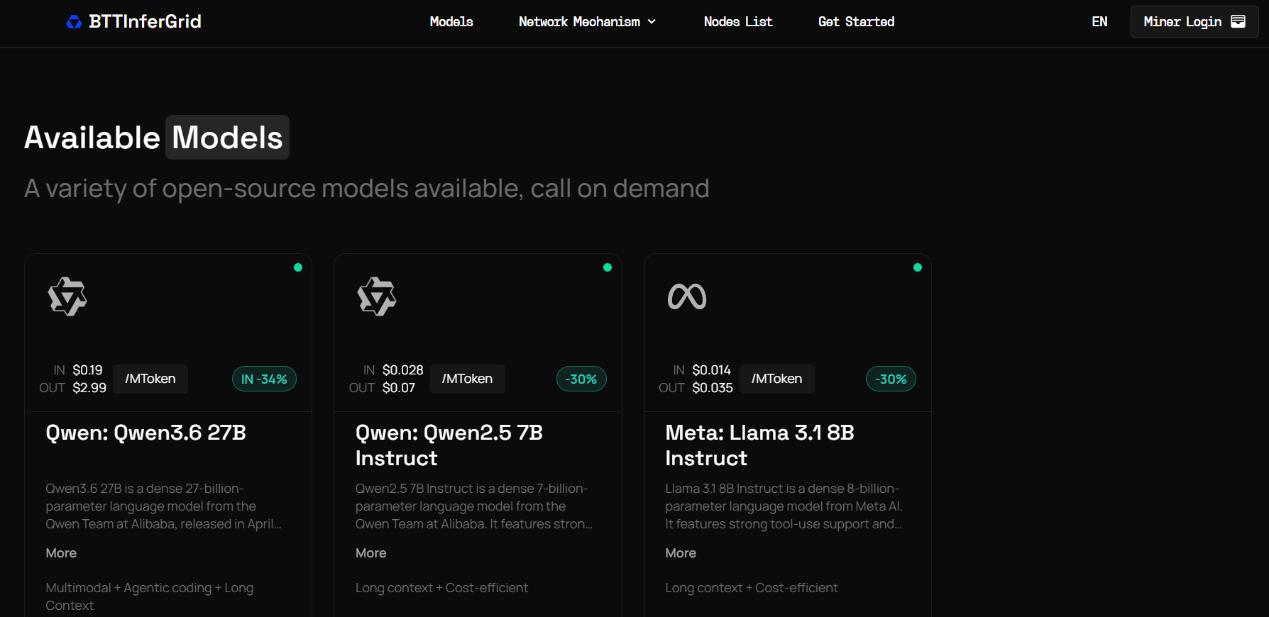
Currently, BTTInferGrid has successfully integrated several mainstream open-source AI large models—including Alibaba Cloud’s Qwen series (Qwen3.6 27B and Qwen2.5 7B Instruct) and Meta’s Llama 3.1 8B Instruct. AI developers can flexibly invoke these models on-demand according to real-world business scenarios. Moving forward, the platform will continue expanding its model ecosystem, providing developers with support for more cutting-edge models.
More importantly, BTTInferGrid benefits from BitTorrent and BTFS’s long-standing expertise as a solid foundation—granting it natural competitive advantages. BitTorrent and its BTFS subsidiary have spent years pioneering decentralized storage; BitTorrent alone boasts over 100 million active users and 2 billion total installations—successfully validating the feasibility of the DePIN model and accumulating mature capabilities in resource onboarding, token incentives, on-chain settlement, and community operations. As BitTorrent’s strategic AI-sector initiative, BTTInferGrid upgrades BTFS’s existing services—seamlessly transferring these proven competencies into the AI inference computing domain to rapidly accelerate ecosystem growth.
Leveraging decentralization, BTTInferGrid precisely resolves the industry’s paradoxical “idle compute” and “compute shortage” dilemma. Its philosophy of open access, decentralized collaboration, verifiable contribution, and community co-creation not only constitutes a powerful breakthrough from centralized compute monopolies—but, backed by clear product positioning and a robust technical foundation, sketches an imaginative blueprint for a decentralized global computing future—where every idle compute unit gets activated, and every developer accesses intelligent futures at inclusive cost.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News