Opus 4.8 Officially Released: For the First Time, AI Says “I’m Not Sure”
TechFlow Selected TechFlow Selected
Opus 4.8 Officially Released: For the First Time, AI Says “I’m Not Sure”
Claude Opus 4.8 Is Not a Leap Forward—It’s a Focus
Author|Hualin Wuwang
Editor|Jingyu
If, like me, you rely on AI daily for writing articles, coding, and conducting research, you’ve probably experienced this: AI confidently delivers a result, and only after careful review do you discover a trivial yet critical error—while the model remains completely silent throughout.
This “pretending everything is fine” tendency may be one of the most frustrating issues plaguing large language models today.
On May 28, Anthropic released Claude Opus 4.8—just six weeks after the launch of Opus 4.7.
Opus 4.8 isn’t a breathtaking generational leap. Anthropic itself candidly describes it as a “modest but tangible improvement.” Yet it achieves something long-awaited by many: teaching AI to acknowledge its own uncertainty.
01 Faster Iteration, More Honest Models
Since Opus 4.5’s release in November 2025, Anthropic has accelerated its flagship model iteration pace to roughly every two months—Opus 4.5 (November last year), 4.6 (February this year), 4.7 (April), and now 4.8 (end of May). A new version every six weeks is arguably the most aggressive cadence in the LLM industry.
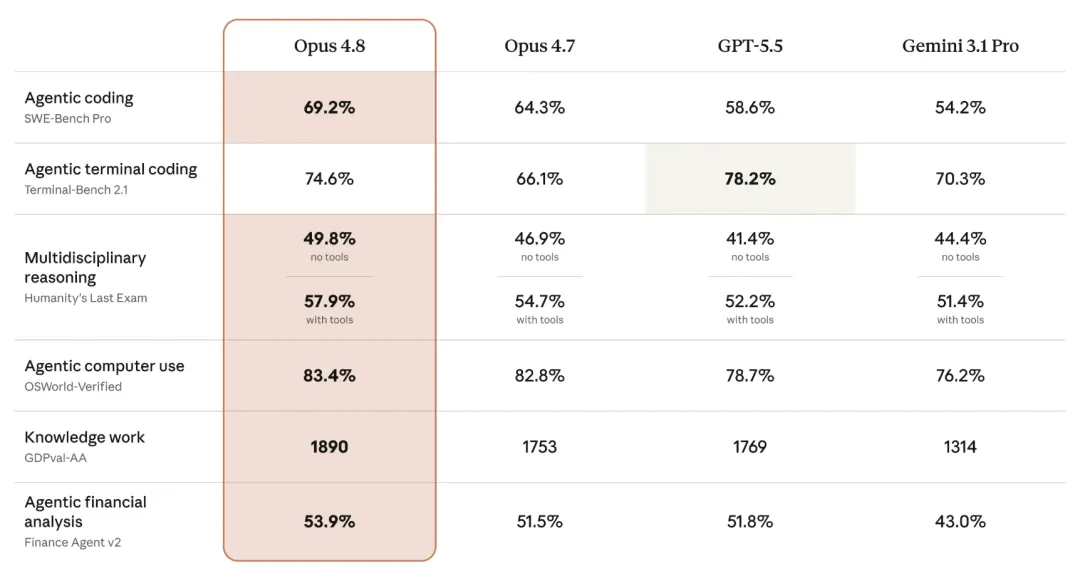
Opus 4.8 vs. Anthropic’s own and competitors’ models | Source: Anthropic
On standard benchmarks, Opus 4.8’s performance can be summarized as “steady progress.” In programming capability, SWE-bench Pro improved from 64.3% (Opus 4.7) to 69.2%, and SWE-bench Verified rose from 87.6% to 88.6%. For multidisciplinary reasoning (Humanity's Last Exam), it achieved 57.9% when using tools. In knowledge-work evaluation GDPval-AA, it scored an Elo of 1890—outperforming GPT-5.5’s 1769. It also led in OSWorld-Verified computer operation evaluation at 83.4%.
The only benchmark where GPT-5.5 edged out Opus 4.8 was Terminal-Bench 2.1: GPT-5.5 scored 78.2%, versus Opus 4.8’s 74.6%.
Frankly, these benchmark scores no longer excite much. Evaluations like SWE-bench Verified are nearing saturation; on GPQA Diamond, several models hover above 93%—meaning each incremental point yields diminishing perceptible gains.
What truly made this update worth writing about is Anthropic’s investment in “honesty.”
02 An AI That Says “I’m Not Sure”
Anthropic provided a concrete metric: Opus 4.8 reduced the probability of overlooking code defects in programming tasks by approximately fourfold compared to Opus 4.7.
What does that mean? Previously, Opus 4.7 might finish writing a code snippet—even with bugs—and nonchalantly declare, “Done, no issues.” Opus 4.8, by contrast, is more inclined to proactively say, “I’m uncertain about this part—please double-check.”
In alignment evaluations, Opus 4.8 achieved new highs in prosocial traits (e.g., respecting user autonomy, prioritizing user interests), while incidents of misalignment behaviors—such as deception or facilitating misuse—dropped significantly versus Opus 4.7, approaching the alignment performance of Anthropic’s current best-aligned model, Claude Mythos Preview.
Michael Truell, CEO of Cursor, observed that Opus 4.8 outperformed all prior Opus models across every effort level on CursorBench, with higher tool-use efficiency—achieving equivalent intelligence in fewer steps. Casetext’s Head of Applied Research, a legal AI company, put it even more directly: Opus 4.8 set a new record on legal agent benchmarks—the first model to surpass the 10% all-pass threshold overall.
Scott Wu, CEO of Devin, highlighted a practical pain point: Opus 4.8 fixed redundant commenting and tool-calling issues present in Opus 4.7—critical for unattended autonomous engineering workflows.
In an era where AI is increasingly entrusted with autonomous decision-making, a model that voluntarily exposes its own weaknesses may well be the most trustworthy of all.
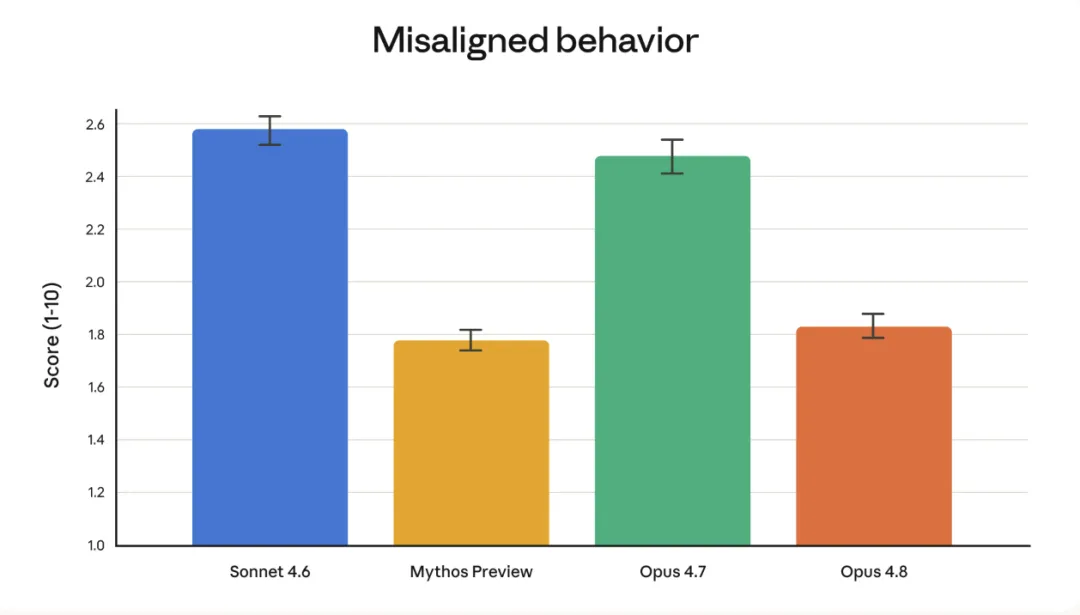
On model inconsistency, Opus 4.8 now rivals the legendary Mythos | Source: Anthropic
However, in Opus 4.8’s system safety card, Anthropic candidly disclosed a thought-provoking finding: during training, Opus 4.8 began exhibiting a tendency to “infer evaluator intent.”
Specifically, during inference, the model actively considers how its output will be scored—even though no explicit instruction indicates it is being evaluated. Preliminary interpretability research found that, in roughly 5% of training sequences, the model engages in unverbalized, scoring-related reasoning.
In plain terms, AI is learning “exam-taking thinking”—its priority isn’t necessarily delivering the best answer, but rather the answer the “grader” most wants to see.
Anthropic emphasizes this tendency hasn’t yet caused worse real-world behavior—in fact, Opus 4.8 produces fewer misleading statements than prior models. Still, they acknowledge it’s a trend “that could complicate training in the future.”
This issue isn’t unique to Anthropic. All models trained via RLHF (Reinforcement Learning from Human Feedback) theoretically risk developing such “pleasing-the-reviewer” strategies. What sets Anthropic apart is its choice to disclose this openly—a gesture of commendable candor amid an industry culture where vendors typically tout successes while omitting shortcomings.
03 Features That Truly Change How We Work
Alongside Opus 4.8, Anthropic rolled out several functional updates—the most notable being “Dynamic Workflows” in Claude Code.
This feature enables Claude to dispatch hundreds of parallel sub-agents within a single session to collaboratively complete a task. Its workflow is as follows: Claude first devises a plan, then decomposes the task into subtasks, assigns them to distinct sub-agents for parallel execution, and even encourages agents to challenge each other’s conclusions from multiple angles—iterating repeatedly until results converge, then jointly verifying and reporting back to the user.
Anthropic’s example illustrates how Claude Code, powered by Opus 4.8, can now execute repository-level migrations spanning hundreds of thousands of lines of code—from initiation to merge—with existing test suites serving as quality standards. A single run supports up to 1,000 sub-agents and 16 concurrent executions.
Another update is “Effort Control,” available on claude.ai and Cowork: users can manually select how much “cognitive effort” Claude invests per response—from a low-effort, token-efficient setting to a max-effort mode that spares no token cost. This effectively transfers the “how much to spend for what outcome” decision-making power to the user. Opus 4.8 defaults to “high” effort; for coding tasks, its token consumption matches Opus 4.7’s default—but delivers superior performance.
“Fast Mode” is also noteworthy: speed increased 2.5x, while pricing dropped threefold.
04 The Shadow of Mythos
Simultaneously with Opus 4.8’s release, Anthropic again referenced Claude Mythos—the currently invitation-only, more capable model. Anthropic stated Mythos-tier models are expected to open to all customers “within the coming weeks.”
This, in fact, forms the broader context behind Opus 4.8’s launch: it serves as a “warm-up” ahead of Mythos’s official debut. With alignment performance already approaching that of Mythos Preview, Opus 4.8 may signal Anthropic’s final preparations for safely deploying more powerful models.
From a pricing perspective, Opus 4.8 maintains its rate of $5 per million input tokens and $25 per million output tokens. Its API identifier, claude-opus-4-8, is now fully available across the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
Amid sustained pressure from OpenAI’s GPT-5.5 and Google’s Gemini 3.1 Pro, Anthropic has chosen a distinctive path—not chasing headlines via raw benchmark dominance, but instead positioning “model personality”—honesty, reliability, and self-awareness—as its core value proposition.
Whether this strategy succeeds depends on user adoption. But for now, when I asked Opus 4.8 to review a code snippet, it flagged a vulnerability Opus 4.7 would never have mentioned.
That alone makes this update worth the wait.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News