Moonshot MoBA Core Author's Account: A "Newcomer to Large Model Training" Enters Seclusion Cliff Three Times
TechFlow Selected TechFlow Selected
Moonshot MoBA Core Author's Account: A "Newcomer to Large Model Training" Enters Seclusion Cliff Three Times
"Starting from open-source papers and open-source code, we've now evolved to open-source thought chains!"
Author: Andrew Lu, LatePost Team

Image source: Generated by Wujie AI
On February 18, Kimi and DeepSeek simultaneously announced new advancements—MoBA and NSA, respectively—both improvements to the "Attention Mechanism."
Today, Andrew Lu, one of the key developers behind MoBA, shared his experience on Zhihu, recounting three major setbacks during development, which he humorously called "three entries into Siguoya." His Zhihu profile describes him as a "new LLM trainer."
A comment under this post reads: "From open-sourcing papers and code, we've now evolved to open-sourcing chains of thought."
The attention mechanism is crucial because it forms the core of current large language models (LLMs). Going back to June 2017, the seminal Transformer paper that launched the LLM revolution was titled "Attention Is All You Need," having since been cited 153,000 times.
The attention mechanism enables AI models to mimic human cognition by determining what information to "focus on" and what to "ignore," capturing the most critical parts of input data.
Attention operates in both the training and inference phases of large models. Its basic principle involves calculating relationships among tokens (words or subwords) within an input sequence like "I like eating apples" to understand semantic meaning.
However, as context length increases, the standard Transformer's initial Full Attention becomes prohibitively expensive in terms of computational resources. The original process requires computing importance scores for all input tokens before applying weighted aggregation to identify key words. This leads to quadratic (nonlinear) growth in computational complexity as text length increases. As stated in the abstract of the MoBA paper:
"The inherent quadratic increase in computational complexity in traditional attention mechanisms brings daunting computational overhead."
At the same time, researchers aim for longer contexts in large models—multi-turn dialogue, complex reasoning, memory capabilities—features envisioned for AGI require increasingly long context handling.
Finding an optimized attention mechanism that reduces computational and memory costs without sacrificing model performance has thus become a central challenge in LLM research.
This explains why multiple companies are converging on attention-related technologies.
Besides DeepSeek’s NSA and Kimi’s MoBA, in mid-January this year, another Chinese LLM startup MiniMax implemented a novel attention mechanism extensively in its first open-source model, MiniMax-01. MiniMax founder Yan Junjie told us at the time that this was one of the model’s primary innovations.
Liu Zhiyuan, co-founder of MindSpore Intelligence and associate professor at Tsinghua University’s Department of Computer Science, also published InfLLM in 2024, involving sparse attention improvements, which was cited by the NSA paper.
Among these developments, the attention mechanisms in NSA, MoBA, and InfLLM fall under "Sparse Attention," while MiniMax-01 primarily explores another direction: "Linear Attention."
Cao Shijie, senior researcher at Microsoft Asia Research Institute and one of the authors of SeerAttention, explained: "Overall, linear attention modifies standard attention more radically, aiming directly at solving the quadratic explosion problem (hence nonlinear) caused by increasing text length. One potential trade-off is reduced ability to capture complex dependencies over long contexts. Sparse attention, by contrast, leverages the inherent sparsity of attention to pursue a more stable optimization approach."
We also recommend Cao Shijie’s highly upvoted Zhihu answer on attention mechanisms: https://www.zhihu.com/people/cao-shi-jie-67/answers
(He answered the question: "What are the key takeaways from Liang Wenfeng's newly published DeepSeek paper on the NSA attention mechanism, and what impact might it have?")
Fu Tianyu, co-first author of MoA (Mixture of Sparse Attention) and PhD student at Tsinghua NICS-EFC Lab, said regarding the broader direction of sparse attention: "Both NSA and MoBA introduce dynamic attention methods—dynamically selecting KV Cache blocks requiring fine-grained attention computation. Compared to static sparse attention approaches, this enhances model performance. Both methods integrate sparse attention during training rather than only during inference, further boosting performance."
(Note: A KV Cache block stores previously computed Key tags and Value values. Key tags serve as identifiers for data features or positions in attention calculations, enabling matching and association with other data when computing attention weights. Value values correspond to Key tags and typically contain actual data content such as semantic vectors of words or phrases.)
In addition, Moonshot not only released a detailed MoBA technical paper but also published the MoBA engineering code on GitHub. This codebase has already been deployed in Moonshot’s Kimi product for over a year.
* Below is Andrew Lu’s self-narrative from Zhihu, republished with permission. Original post contains numerous AI terms; explanatory notes in gray parentheses were added by editors. Original link: https://www.zhihu.com/people/deer-andrew
Andrew Lu's Development Journey
Invited by Professor Zhang Mingxing (Assistant Professor at Tsinghua University), I’ll share my rollercoaster experience developing MoBA—a journey I call "three entries into Siguoya." (Andrew Lu was answering: "How do you evaluate Kimi’s open-sourced sparse attention framework MoBA? What are its strengths compared to DeepSeek’s NSA?")
Origin of MoBA
The MoBA project started very early—right after Moonshot’s founding in late May 2023. On my first day joining, Tim (Zhou Xinyu, co-founder of Moonshot) pulled me into a small room with Qiu Jiezhong (from Zhejiang University / Zhejiang Lab, proposer of the MoBA idea) and Dylan (Moonshot researcher) to begin work on Long Context Training. First, I’d like to thank Tim for his patience and mentorship, placing great trust in an LLM novice like me. Among those developing production models and related technologies, many of us—including myself—started with virtually no prior LLM knowledge.
At the time, industry standards weren’t high—most were doing 4K pre-training (models handling input/output sequences of about 4,000 tokens, several thousand Chinese characters). The initial project name was 16K on 16B, meaning pre-train a 16-billion-parameter model on 16K-length sequences. Later in August, this requirement quickly escalated to supporting 128K-length pre-training. This became MoBA’s first design goal: rapidly train a model from scratch capable of handling 128K-length contexts, without relying on continued training from existing models.
This raises an interesting point: In May–June 2023, the prevailing belief was that end-to-end training on long texts outperformed training shorter models and then extending them. This view shifted only in late 2023 with the emergence of Long Llama (Meta’s long-context-capable model). We conducted rigorous validation ourselves and found that short-text training plus length extension actually achieved better token efficiency (higher effective information per token, meaning models complete high-quality tasks with fewer tokens). Thus, MoBA’s original design goal became obsolete.
During this phase, MoBA’s architecture was far more "radical." Compared to today’s minimalist version, the initial proposal was a two-layer serial attention scheme incorporating cross-attention (for modeling relationships between different text segments), with a parameter-free gate (no trainable parameters). However, to better learn historical tokens, we added inter-machine cross-attention and corresponding parameters at each Transformer layer (to better retain historical information). This MoBA design already incorporated what later became known as Context Parallelism—where the full context sequence is distributed across nodes and gathered only when needed. We spread the entire context sequence across data-parallel nodes, treating each node’s internal context as an expert in a Mixture of Experts (MoE) system. Tokens needing attention would be sent to the relevant expert for cross-attention computation, with results communicated back. We integrated fastmoe (an early MoE training framework) into Megatron-LM (NVIDIA’s widely used large model training framework) to support communication between experts.
We called this approach MoBA v0.5.
(Editor’s note: MoBA drew inspiration from mainstream MoE structures in large models. MoE activates only a subset of experts per computation instead of all, saving compute; MoBA’s core idea is “only attending to the most relevant context, not all context,” thus reducing computation and cost.)
By early August 2023, the main model had already processed vast amounts of tokens, making retraining costly. With significant structural changes and additional parameters, MoBA entered Siguoya for the first time.
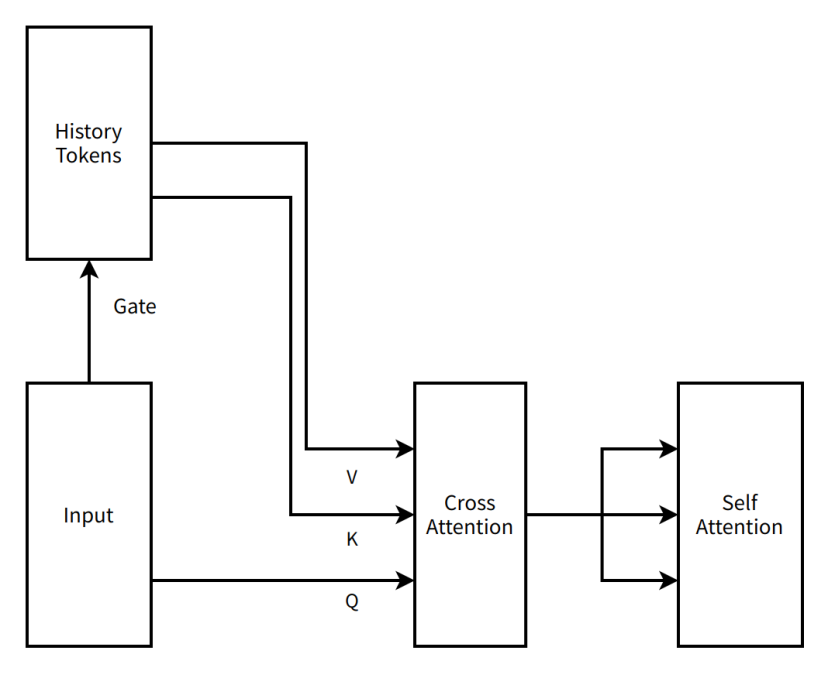
A simple illustration of MoBA v0.5
Editor’s note:
History Tokens — In NLP scenarios, represents a collection of previously processed text units.
Gate — In neural networks, a structure controlling information flow.
Input — Data or information received by the model.
V (Value) — In attention mechanisms, contains actual data/content to be processed or attended to, such as semantic vectors.
K (Key) — In attention mechanisms, labels identifying data features or positions, facilitating matching and association with other data.
Q (Query) — In attention mechanisms, a vector used to retrieve relevant information from key-value pairs.
Cross Attention — An attention mechanism focusing on inputs from different sources, e.g., linking input with historical information.
Self Attention — An attention mechanism where the model attends to its own input, capturing internal dependencies.
First Entry into Siguoya
"Entering Siguoya" is of course a playful metaphor—an interval dedicated to seeking improvements and deeper understanding. The first entry was brief. Tim, Moonshot’s idea generator, proposed a new direction: changing MoBA from a two-layer serial attention to a single-layer parallel attention. MoBA would no longer add extra model parameters but reuse existing attention parameters to synchronously learn all information within a sequence, minimizing disruption to current structures and enabling continued training.
We called this MoBA v1.
MoBA v1 was essentially a product of Sparse Attention and Context Parallelism. At the time, Context Parallelism wasn't widespread, yet MoBA v1 demonstrated exceptional end-to-end acceleration. After validating effectiveness on 3B and 7B models, we hit a wall scaling up—large training runs exhibited severe loss spikes (abnormal phenomena during training). Our initial method of merging block attention outputs was too simplistic—merely summing them—which made debugging against Full Attention impossible due to lack of ground truth (standard reference output from Full Attention). Without ground truth, debugging was extremely difficult. Despite exhausting all available stabilization techniques, we couldn’t resolve the issue. With larger models failing to train properly, MoBA entered Siguoya for the second time.
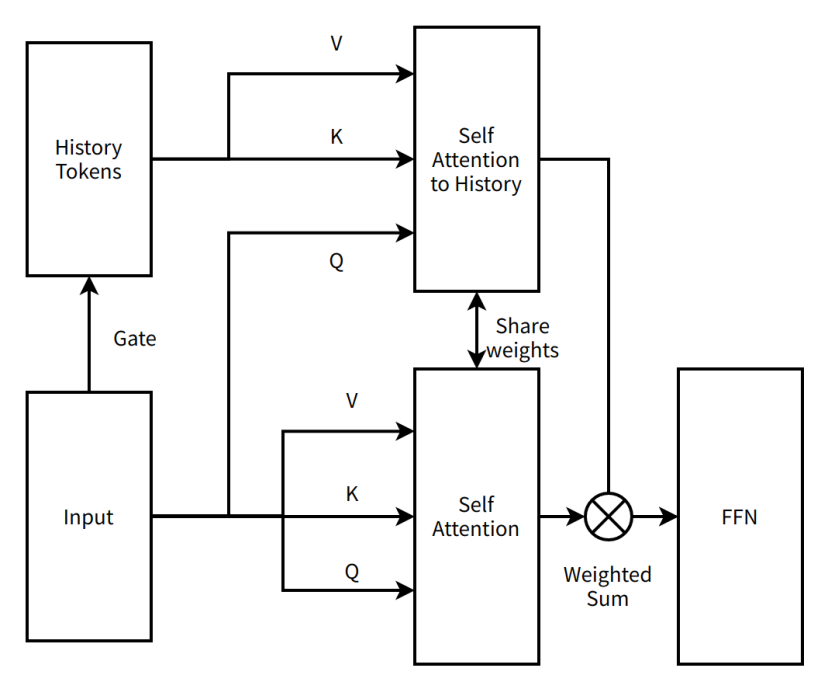
A simple illustration of MoBA v1
Editor’s note:
Self Attention to History — An attention mechanism where the model focuses on historical tokens, capturing dependencies between current input and past information.
Share weights — Using identical weight parameters across different parts of a neural network to reduce parameter count and improve generalization.
FFN (Feed-Forward Neural Network) — A basic neural network structure where data flows unidirectionally from input through hidden layers to output.
Weighted Sum — An operation summing multiple values according to their respective weights.
Second Entry into Siguoya
The second stay in Siguoya lasted much longer—from September 2023 until early 2024. But being in Siguoya didn’t mean abandonment. I experienced Moonshot’s second hallmark: saturation rescue.
Beyond Tim and Professor Qiu’s consistent contributions, Su Shen (Su Jianlin, Moonshot researcher), Yuan Ge (Jingyuan Liu, Moonshot researcher), and various experts joined intense discussions to dissect and fix MoBA. The first correction targeted the naive Weighted Sum fusion. After experimenting with various ways of combining via Gate Matrix multiplication/addition, Tim unearthed Online Softmax (computable incrementally without seeing all data) from old literature, suggesting it might work. The biggest advantage: with Online Softmax, we could lower sparsity to zero (selecting all blocks) and strictly compare/debug against mathematically equivalent Full Attention, resolving most implementation issues. However, splitting context across data-parallel nodes still caused imbalance—one data sample evenly distributed across ranks meant the first few tokens on the initial data-parallel rank would receive massive Q requests for attention computation, creating severe bottlenecks and degrading acceleration efficiency. This phenomenon is better known as Attention Sink.
Then Professor Zhang visited. After hearing our ideas, he proposed decoupling Context Parallelism from MoBA. Context Parallelism should remain separate from MoBA. MoBA should revert to being purely a Sparse Attention mechanism—not a distributed training framework. As long as GPU memory allows, full context can be handled on a single machine using MoBA for computational acceleration, while Context Parallelism manages cross-machine context organization and transmission. Thus, we reimplemented MoBA v2, essentially arriving at the MoBA structure seen today.
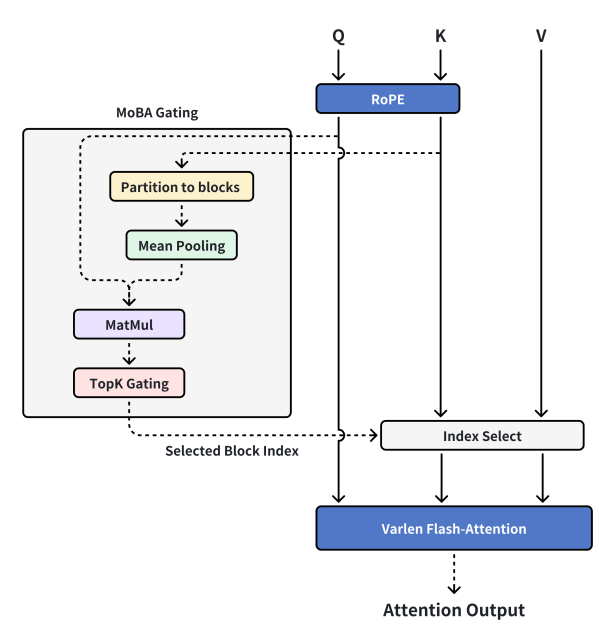
Current MoBA design
Editor’s note:
MoBA Gating — Specific gating mechanism in MoBA.
RoPE (Rotary Position Embedding) — A technique adding positional information to sequences.
Partition to blocks — Dividing data into distinct blocks.
Mean Pooling — A deep learning downsampling operation computing average values within regions.
MatMul (Matrix Multiply) — A mathematical operation computing the product of two matrices.
TopK Gating — A gating mechanism selecting the top K important elements.
Selected Block Index — Indicates indices of selected blocks.
Index Select — Selecting corresponding elements from data based on indices.
Varlen Flash-Attention — An efficient attention mechanism suitable for variable-length sequences.
Attention Output — Output result from attention computation.
MoBA v2 proved stable and trainable. Short-text outputs perfectly aligned with Full Attention. Scaling laws appeared reliable, and deployment onto production models proceeded smoothly. We allocated more resources, debugged extensively, and—after costing countless infra team members’ hair—we achieved fully green needle-in-haystack tests (indicating successful long-context processing capability). At this point, we felt confident and began deployment.
But nothing is more predictable than surprise. During SFT (Supervised Fine-Tuning—further training pre-trained models on specific tasks to enhance task-specific performance), certain datasets came with extremely sparse loss masks (only 1% or fewer tokens contributing gradients). While MoBA performed well across most SFT tasks, especially poor performance emerged on long-document summarization tasks where loss masks were sparsest, reflected in low learning efficiency. MoBA was paused just before full deployment—entering Siguoya for the third time.
Third Entry into Siguoya
The third entry was the most nerve-wracking. By now, the project had incurred massive sunk costs—substantial investment in computing and human resources. If end-to-end long-context applications ultimately failed, earlier efforts would be nearly wasted. Fortunately, thanks to MoBA’s strong mathematical properties, ablation studies (experiments removing/modifying parts of a model to assess impact) during another round of saturation rescue revealed clear patterns: performance was excellent without loss mask, but deteriorated sharply with it. We realized the root cause: gradient-carrying tokens during SFT were too sparse, leading to inefficient learning. To address this, we modified the final few layers to use Full Attention, increasing gradient token density during backpropagation and improving learning efficiency on specific tasks. Subsequent experiments confirmed this switch did not significantly affect the performance of subsequent Sparse Attention layers—achieving parity with Full Attention across metrics even at 1M-length contexts. MoBA emerged once again from Siguoya and successfully went live serving users.
Finally, heartfelt thanks to all the experts who pitched in, to the company for unwavering support and massive GPU resources. What we’re releasing now is exactly the code running in production—long-validated, stripped of unnecessary designs due to practical needs, maintaining a minimalist structure while delivering sufficient performance. We hope MoBA—and the CoT (Chain of Thought) behind its creation—can offer some help and value to others.
FAQ
Take this opportunity to answer frequently asked questions over the past few days. I’ve basically been making Professor Zhang and Su Shen act as customer support—felt terrible about it—so here are some common questions compiled together.
1. Is MoBA ineffective for Decoding (text generation during model inference)?
MoBA is effective for decoding—very effective for MHA (Multi-Head Attention), less so for GQA (Grouped Query Attention), and least effective for MQA (Multi-Query Attention). The reason is straightforward: Under MHA, each Q has its own corresponding KV cache. Ideally, MoBA’s gate can amortize computation during prefill (initial input processing stage) to determine and store representative tokens for each block, which remain unchanged afterward. Thus, all IO operations can originate almost entirely from index-selected KV caches, meaning the degree of sparsity directly determines IO reduction.
But for GQA and MQA, since a group of Q heads shares the same KV cache, if each Q head freely selects its preferred block, any IO gains from sparsity may be negated. Consider this scenario: 16 Q heads in MQA, MoBA divides the sequence into 16 parts. In the worst case, each Q head prefers a different context block numbered 1 through 16, completely eliminating IO savings. The more Q heads able to freely select KV blocks, the worse the effect.
Given this "freely selecting Q heads" phenomenon, a natural improvement idea is merging—if all heads chose the same block, we’d gain pure IO benefits. Yes—but our testing shows that especially for pre-trained models that have already incurred high costs, each Q head develops unique "preferences," and forcing merges performs worse than retraining from scratch.
2. MoBA defaults to mandatory self-attention (self-attention mechanism). Does this mean neighboring chunks must also be selected?
No, not necessarily. This is a known source of confusion. We ultimately trusted SGD (Stochastic Gradient Descent). Current MoBA gate implementation is very direct. Interested readers can easily modify the gate to force selection of the previous chunk, but our own tests show marginal benefit.
3. Does MoBA have a Triton (framework for writing high-performance GPU code, developed by OpenAI) implementation?
We implemented one version achieving over 10% end-to-end performance gain. However, maintaining and keeping up with the mainline development in Triton proves costly, so after several iterations, we’ve postponed further optimization.
* Project links for the aforementioned works mentioned at the beginning of the article (GitHub pages include technical paper links; DeepSeek has not yet launched NSA’s GitHub page):
MoBA GitHub page: https://github.com/MoonshotAI/MoBA
NSA technical paper: https://arxiv.org/abs/2502.11089
MiniMax-01 GitHub page: https://github.com/MiniMax-AI/MiniMax-01
InfLLM GitHub page: https://github.com/thunlp/InfLLM?tab=readme-ov-file
SeerAttention GitHub page: https://github.com/microsoft/SeerAttention
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News