

Jensen Huang's COMPUTEX 2024 Keynote Transcript: We Are Experiencing Compute Inflation
TechFlow Selected TechFlow Selected
Jensen Huang's COMPUTEX 2024 Keynote Transcript: We Are Experiencing Compute Inflation
Nvidia CEO Jensen Huang showcased the company's latest advancements in accelerated computing and generative AI at the Computex 2024 conference in Taipei.
Compiled by: Youxin

On the evening of June 2, NVIDIA CEO Jensen Huang unveiled the company's latest breakthroughs in accelerated computing and generative AI at Computex 2024 in Taipei, while also outlining a visionary roadmap for the future of computing and robotics technology.

The keynote covered everything from foundational AI technologies to future robotics and applications of generative AI across industries, comprehensively showcasing NVIDIA’s remarkable achievements in driving transformative advances in computing.

Huang stated that NVIDIA sits at the intersection of computer graphics, simulation, and artificial intelligence—this is its soul. Everything shown today was simulated, combining mathematics, science, computer science, and stunning computer architecture. These were not animations but self-created content fully integrated into the Omniverse virtual world.
Accelerated Computing and AI
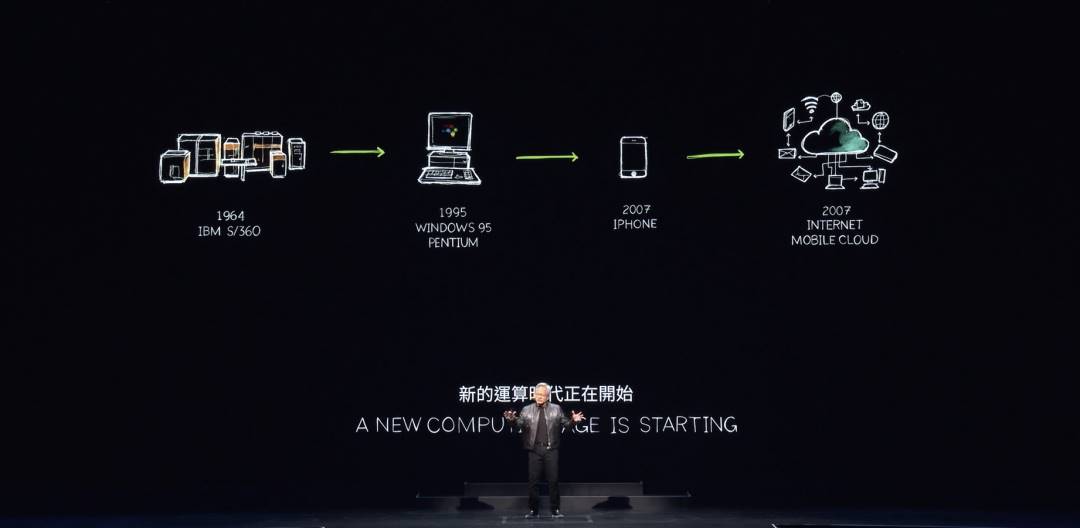
Huang explained that the foundation of everything we see lies in two fundamental technologies: accelerated computing and AI running within Omniverse. These two computational forces will reshape the entire computer industry. The computer industry has existed for about 60 years. In many ways, most of what we do today was invented just one year after his birth in 1964.
The IBM System/360 introduced the central processing unit (CPU), general-purpose computing, separation of hardware and software via operating systems, multitasking, I/O subsystems, DMA, and various technologies still in use today. Concepts like architectural compatibility, backward compatibility, and family compatibility—everything we understand about computers—were largely defined back in 1964. Of course, the PC revolution democratized computing, putting it into everyone’s hands and homes.
In 2007, the iPhone brought mobile computing, placing computers directly into our pockets. Since then, everything has been connected and continuously powered through mobile cloud networks. Over these 60 years, we've only witnessed two or three major technological shifts—the structural transformations of computing—and now we are on the verge of witnessing another such shift.

Two fundamental changes are occurring. First, the performance improvement of processors—the engines driving the computer industry, specifically CPUs—has significantly slowed down. Yet, the volume of computation required continues to grow exponentially. If data processing demand grows exponentially while performance does not, "computational inflation" will occur. Indeed, we’re already seeing this. Global data centers are consuming dramatically increasing amounts of electricity. Computing costs are rising. We are experiencing computational inflation.
Clearly, this cannot continue. Data volumes will keep growing exponentially, but CPU performance gains will never return. There is a better way. For nearly two decades, NVIDIA has been advancing accelerated computing. CUDA enhances CPUs by offloading and accelerating tasks better suited for specialized processors. The performance gains have been so exceptional that it’s now evident: with CPU improvements slowing and eventually plateauing, we should accelerate everything.

Huang predicted that all compute-intensive applications will be accelerated, and every data center will soon follow suit. Accelerated computing now makes perfect sense. Consider an application where “100t” represents 100 units of time—it could be 100 seconds or 100 hours. As you know, there are AI applications today being trained over periods of 100 days.
“1T code” refers to sequential processing code where single-threaded CPU performance is critical. Operating system control logic is vital, requiring instructions to execute one after another. However, many algorithms—such as computer graphics rendering, image processing, physics simulation, combinatorial optimization, graph processing, database operations, and especially the linear algebra used in deep learning—are highly parallelizable and ideal for acceleration.
Thus, a new architecture was created by adding GPUs alongside CPUs. Specialized processors can drastically speed up long-running tasks. Because both processors work side-by-side—autonomous and independent—a task requiring 100 time units can be completed in just one, achieving an incredible 100x speedup. Power consumption increases by only about three times, and cost by roughly 50%. This approach has long been standard in the PC industry: adding a $500 GeForce GPU to a $1,000 PC results in massive performance gains. NVIDIA applies the same principle in data centers: adding $500 million worth of GPUs to a billion-dollar data center suddenly transforms it into an AI factory—an evolution happening worldwide.
The savings are staggering. Every dollar spent yields 60x more performance, with 100x faster speeds using only 1.5x the cost and 3x the power. These savings are extraordinary and measurable in dollars.
Many companies currently spend hundreds of millions of dollars processing data in the cloud. If those processes are accelerated, saving hundreds of millions becomes imaginable. This is because general-purpose computing has undergone prolonged inflation.

Now, finally embracing accelerated computing allows us to reclaim vast inefficiencies previously locked away. Massive waste trapped within systems can now be released—translating directly into monetary and energy savings. This is why Huang often says, “The more you buy, the more you save.”
Huang added that accelerated computing delivers extraordinary results—but it’s not easy. Why would such massive savings exist if everyone had already adopted it? Precisely because it’s extremely difficult. No software magically runs 100x faster simply by passing through a C compiler. That wouldn’t even make logical sense—if it were possible, CPU designs would have changed long ago.
In reality, software must be rewritten entirely—to re-express CPU-based algorithms so they can be accelerated, offloaded, and executed in parallel. This exercise in computer science is exceptionally challenging.

Over the past 20 years, NVIDIA has made this easier for the world. Famous examples include cuDNN—the deep neural network library for neural network processing. NVIDIA has an AI physics library useful in fluid dynamics and other applications where neural networks must obey physical laws. Another powerful library is Arial Ran, a CUDA-accelerated 5G radio platform capable of defining and accelerating telecom networks just like internet infrastructure. This acceleration enables transforming all telecommunications into platforms equivalent to cloud computing platforms.
cuLITHO is a computational lithography platform handling the most computationally intensive part of chip manufacturing—mask production. TSMC is already using cuLITHO in production, saving enormous energy and money. TSMC aims to accelerate its full stack to prepare for further algorithmic advances and narrower transistors. Parabricks is NVIDIA’s genomics sequencing library—the highest-throughput in the world. cuOpt is an incredible library for combinatorial optimization and route planning, solving complex problems like the traveling salesman problem.
Scientists widely believed quantum computers were needed to solve such problems. But NVIDIA developed an algorithm running on accelerated computing that achieved record-breaking speeds, setting 23 world records. cuQuantum is a quantum computer simulation system. To design quantum computers, you need simulators; to develop quantum algorithms, you need quantum simulators. When real quantum computers don’t yet exist, how do you design them or create their algorithms? You use today’s fastest computers—of course, NVIDIA CUDA. On top of that, NVIDIA provides a simulator capable of modeling quantum computers. It’s used by hundreds of thousands of researchers globally and integrated into all leading quantum computing frameworks, widely deployed in scientific supercomputing centers.
cuDF is an incredible data processing library. Data processing consumes the majority of cloud spending today—all of which should be accelerated. cuDF accelerates major libraries used worldwide, such as Spark (which many companies may already use), Pandas, a newer library called Polars, and NetworkX for graph databases. These are just a few examples among many others.
Huang emphasized that NVIDIA had to build these libraries so the ecosystem could leverage accelerated computing. Without cuDNN, CUDA alone would never have enabled global deep learning scientists to adopt it—the gap between CUDA and the algorithms used in TensorFlow and PyTorch would have been too great. It would be like doing computer graphics without OpenGL or data processing without SQL. These domain-specific libraries are NVIDIA’s treasures—over 350 in total—that have opened up countless markets.
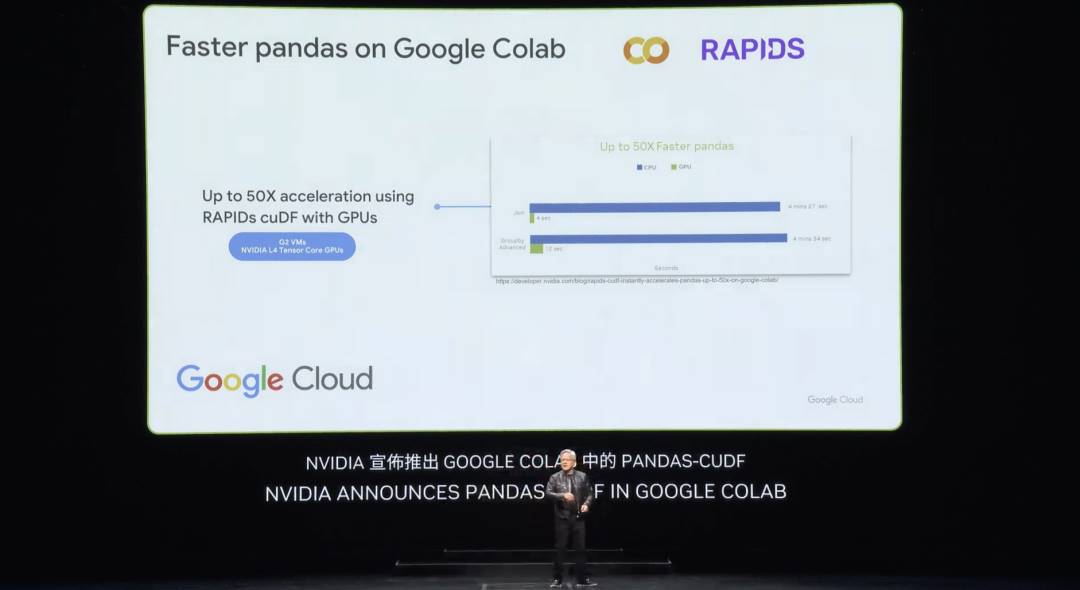
Last week, Google announced accelerated Pandas in the cloud—the world’s most popular data science library. Many of you likely already use Pandas, employed by 10 million data scientists globally and downloaded 170 million times monthly. It’s the spreadsheet for data scientists. Now, with just one click, you can use cuDF-accelerated Pandas in Google Cloud’s Colab platform. The acceleration effect is truly astonishing.
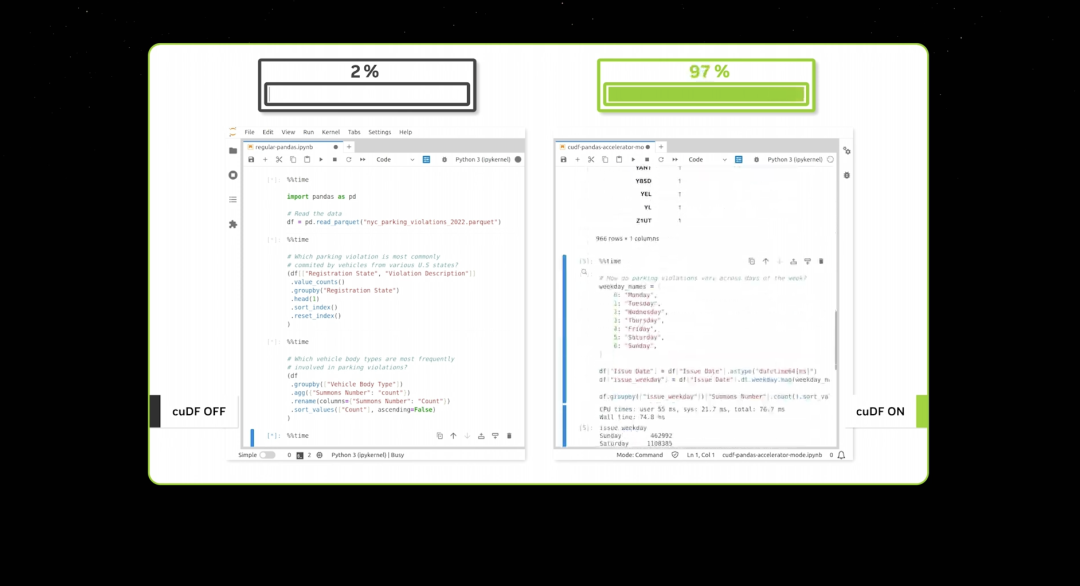
When data processing reaches such speeds, demonstrations don’t take long. CUDA has now reached what people call a tipping point—but it’s even better. CUDA has entered a virtuous cycle.
Such cycles are rare. Looking back at all historical computing architectures, consider microprocessor CPUs—they’ve existed for 60 years without changing at this level. Creating a new platform based on accelerated computing is extremely difficult due to the classic chicken-and-egg problem.
Without developers using your platform, there are no users. But without users, there’s no installed base. Without an installed base, developers aren’t interested. Developers want to write software for large installed bases, but large installed bases require abundant applications to attract users and build adoption.
This catch-22 rarely breaks. NVIDIA spent 20 years—one domain library after another, one acceleration library after another—now boasting 5 million developers worldwide using its platform.
NVIDIA serves every industry—from healthcare and finance to automotive and computing—virtually every major sector and scientific field. With so many customers adopting its architecture, OEMs and cloud providers are eager to build NVIDIA systems. Top-tier system builders here in Taiwan are excited to construct NVIDIA-based systems, expanding market availability and creating greater scale opportunities, enabling broader application acceleration.
Each time an application is accelerated, computing costs drop. A 100x speedup translates to 97%, 96%, or 98% savings. As we move from 100x to 200x or even 1000x acceleration, the marginal cost of computing keeps falling.
NVIDIA believes that by drastically lowering computing costs, markets, developers, scientists, and inventors will continue discovering more algorithms that consume ever-increasing computing resources—eventually reaching a qualitative leap where marginal computing costs become so low that entirely new usage patterns emerge.
Indeed, this is exactly what we’re seeing now. Over the past decade, NVIDIA has reduced the marginal computing cost of certain algorithms by a factor of one million. Training LLMs on entire internet-scale datasets is now not only feasible but common sense—no one questions it. The idea that you could build a computer capable of writing its own software by processing vast data is now real. Generative AI emerged because we firmly believed that if computing becomes cheap enough, someone will find a revolutionary use for it.
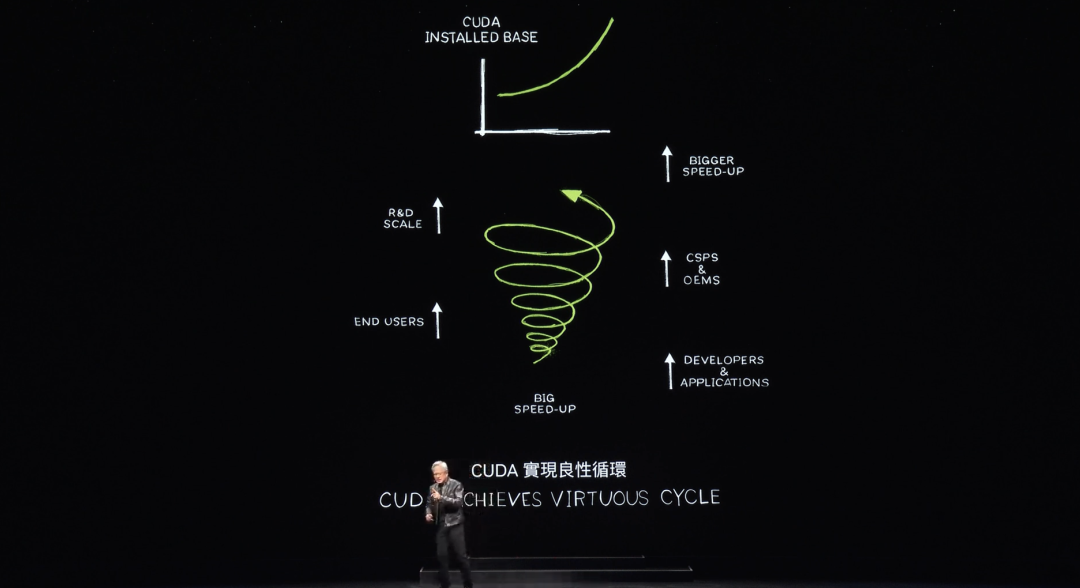
Today, CUDA has achieved this virtuous cycle. Installed base growth and falling computing costs drive more developers to generate innovative ideas, fueling greater demand. We are now at a pivotal starting point.
Huang then mentioned the concept of “Earth-2”—creating a digital twin of Earth. By simulating Earth, we can better predict disasters, understand climate change impacts, and adapt accordingly.

Researchers discovered CUDA in 2012—the first encounter between NVIDIA and AI, a pivotal moment. We were fortunate to collaborate with scientists to enable deep learning.
AlexNet achieved a breakthrough in computer vision. More importantly, stepping back to understand the context, foundations, and long-term potential of deep learning revealed its immense scalability. An algorithm invented decades earlier suddenly achieved feats impossible for traditional human-designed algorithms—thanks to more data, larger networks, and critically, vastly more computing power.
Imagine what might be possible by further scaling the architecture—with even larger networks, more data, and greater computing resources. After 2012, NVIDIA redesigned GPU architecture, introducing Tensor Cores. Ten years ago, NVIDIA invented NVLink, followed by CUDA, TensorRT, NCCL, the acquisition of Mellanox, TensorRT-ML, Triton Inference Server—all integrated into a completely new computer. At the time, no one understood it. No one asked for it. No one grasped its significance.
In fact, Huang was convinced no one would buy it. When NVIDIA announced it at GTC, OpenAI—a small startup in San Francisco—asked NVIDIA to deliver one.
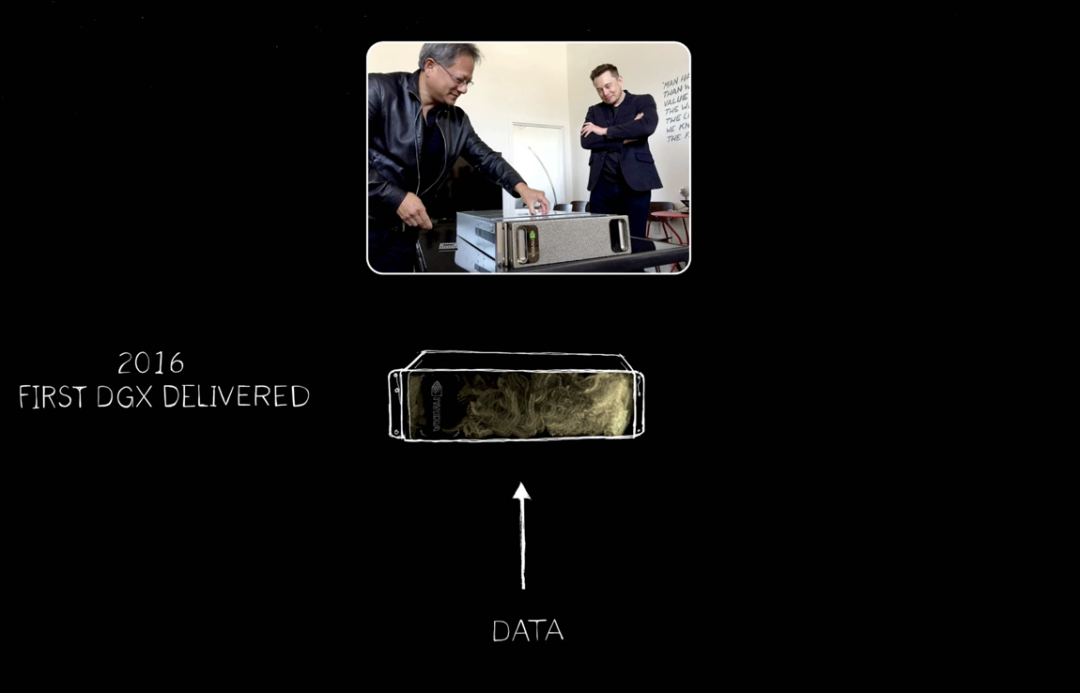
In 2016, Huang delivered the first DGX to OpenAI—the world’s first AI supercomputer. From there, expansion continued—from one AI supercomputer, one AI appliance—to large-scale supercomputers and beyond.
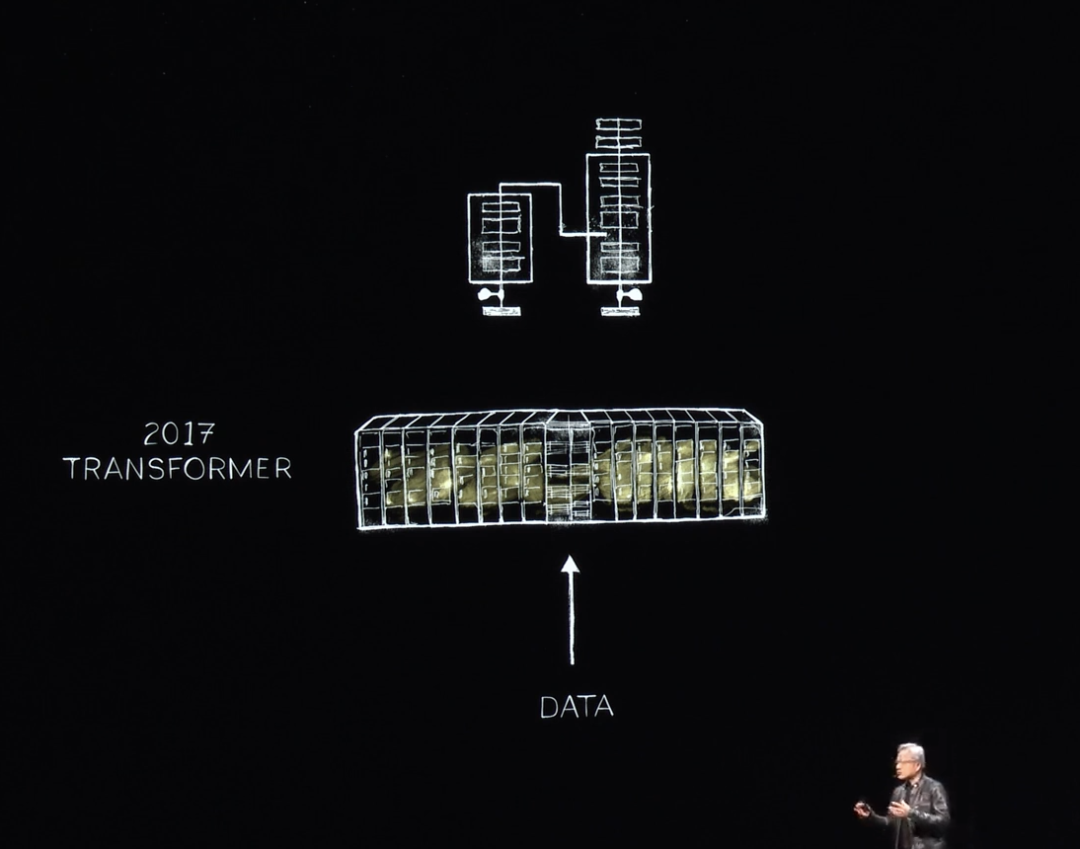
By 2017, the world discovered Transformers, enabling training on massive datasets and recognizing long-range sequence patterns. Now, NVIDIA could train these LLMs and achieve breakthroughs in natural language understanding. Progress continued with increasingly larger systems.
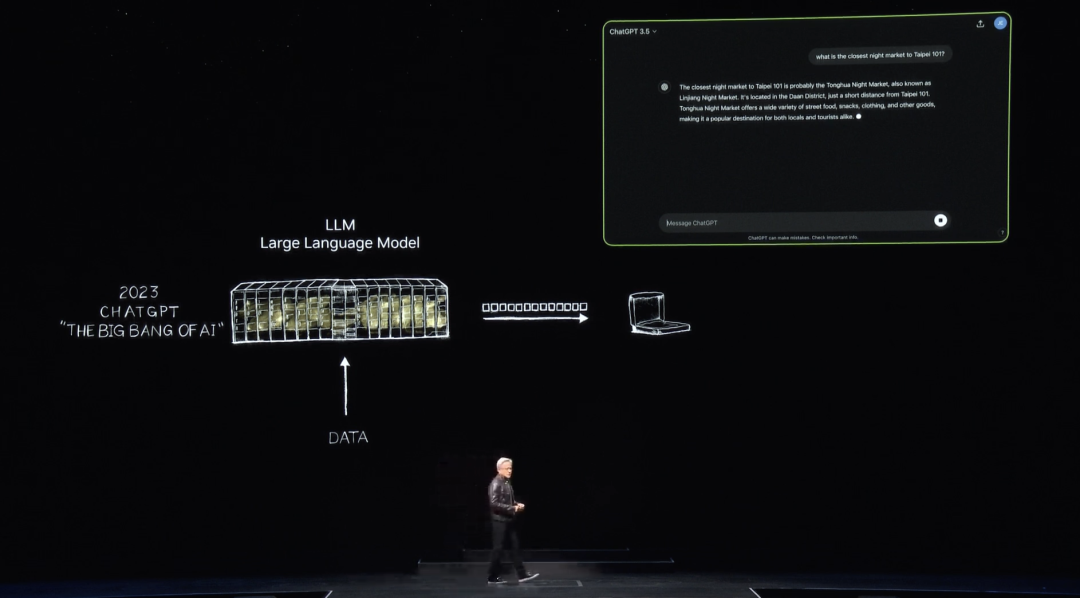
Then in November 2022, trained on thousands of NVIDIA GPUs and a massive AI supercomputer, OpenAI launched ChatGPT—reaching one million users in five days and one hundred million in two months, becoming the fastest-growing application in history.
Before ChatGPT, AI focused on perception—natural language understanding, computer vision, speech recognition—all about sensing and detection. For the first time, the world experienced generative AI, producing tokens one by one—where tokens represent words. Today, tokens can represent images, charts, tables, songs, text, speech, video—anything meaningful. They can be tokens for chemicals, proteins, genes. As seen earlier in the Earth-2 project, weather tokens were generated.
We can understand and learn physics. If AI models can learn physics, they can generate physical phenomena. We can simulate at 1-kilometer resolution—not through filtering, but generation. Thus, we can generate almost any valuable token. We can generate steering commands for cars or motion sequences for robot arms. Anything we can learn, we can now generate.
AI Factories
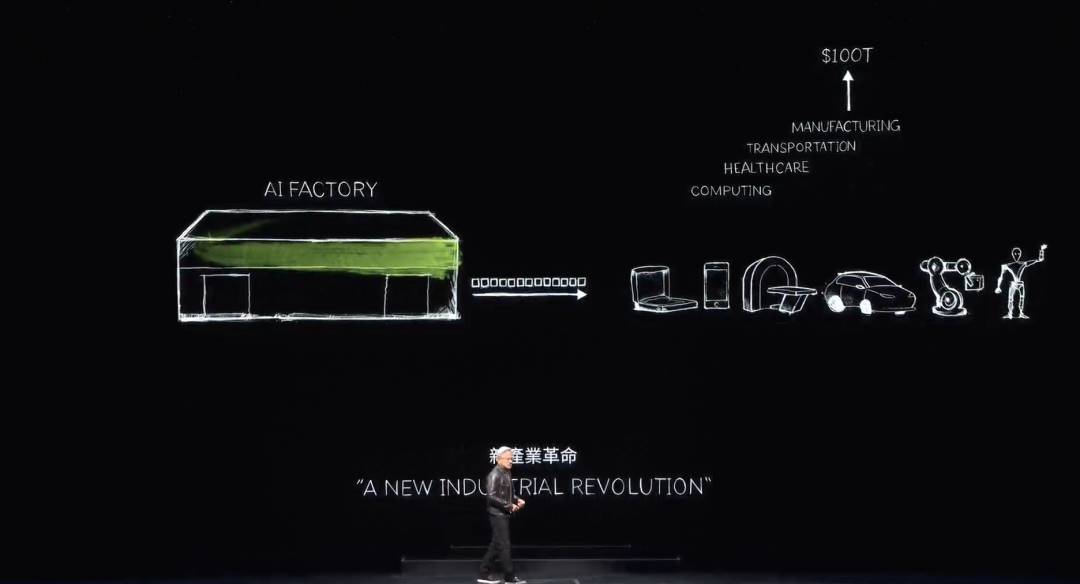
We have now entered the era of generative AI. But more importantly, that initial supercomputer has evolved into a data center generating only one thing: tokens. It is an AI factory—producing, creating, and manufacturing a new, highly valuable commodity.
At the end of the 19th century, Nikola Tesla invented the AC generator. NVIDIA has invented the AI generator. While AC generators produce electrons, NVIDIA’s AI generators produce tokens. Both have immense market potential and are interchangeable across nearly every industry—marking the beginning of a new industrial revolution.
NVIDIA now operates a new factory producing a novel, high-value product for every industry. This method is highly scalable and repeatable.
Every day, numerous new generative AI models emerge. Every industry is rushing in. For the first time, the $3 trillion IT industry is creating tools that directly serve $100 trillion industries. These are no longer mere data storage or processing tools, but intelligent factories generating value for every sector. This will become a manufacturing industry—not manufacturing computers, but using computers to manufacture goods.
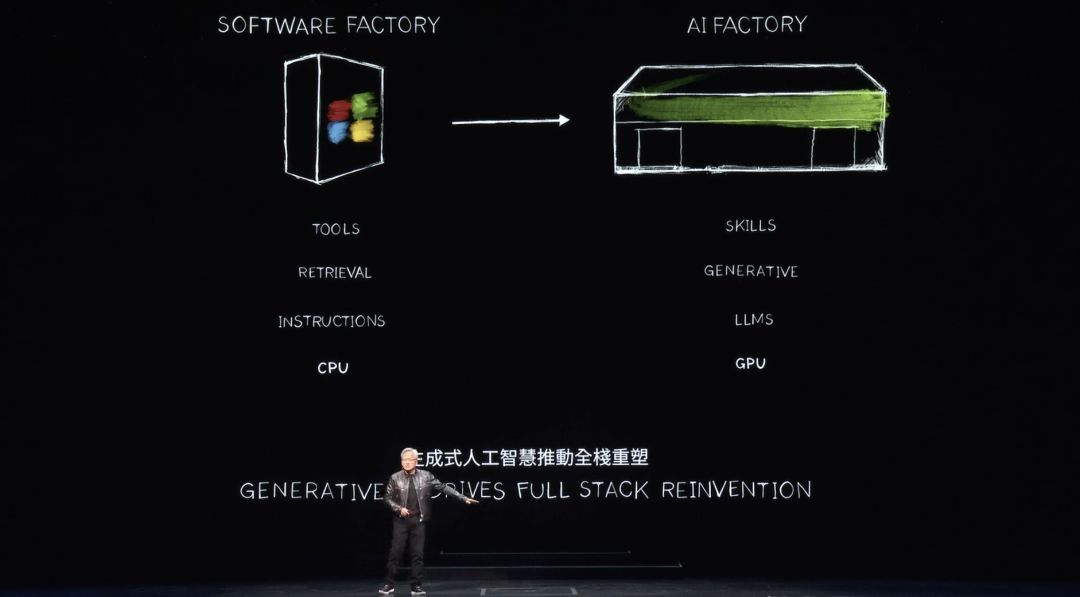
This has never happened before. Accelerated computing brought AI, which led to generative AI, now sparking an industrial revolution. Its impact across industries is profound—enabling the creation of new products, new commodities, called tokens. And the transformation within our own industry is equally significant.
For 60 years, every layer of computing has changed—from general-purpose CPU computing to accelerated GPU computing. Computers once required explicit instructions. Now, computers process LLMs and AI models. The old computing model was retrieval-based. Almost every time you touch your phone, pre-recorded text, images, or videos are retrieved and recomposed via recommendation systems for presentation.
Huang stated that future computers will generate data whenever possible, retrieving only essential information. Generating data requires less energy to convey information and produces more contextually relevant outputs. Knowledge will be encoded, and computers will understand you. Instead of fetching files or information, computers will directly answer your questions. They will no longer be tools we operate, but entities that generate skills and perform tasks.
NIMs: NVIDIA Inference Microservices

Instead of an industry solely producing packaged software—a revolutionary idea in the early 1990s—remember how Microsoft’s software packaging transformed the PC industry. Without packaged software, what would we do with PCs? It drove the industry forward. Now, NVIDIA has a new factory, a new computer. Running on it is a new kind of software: NIMs, NVIDIA Inference Microservices.
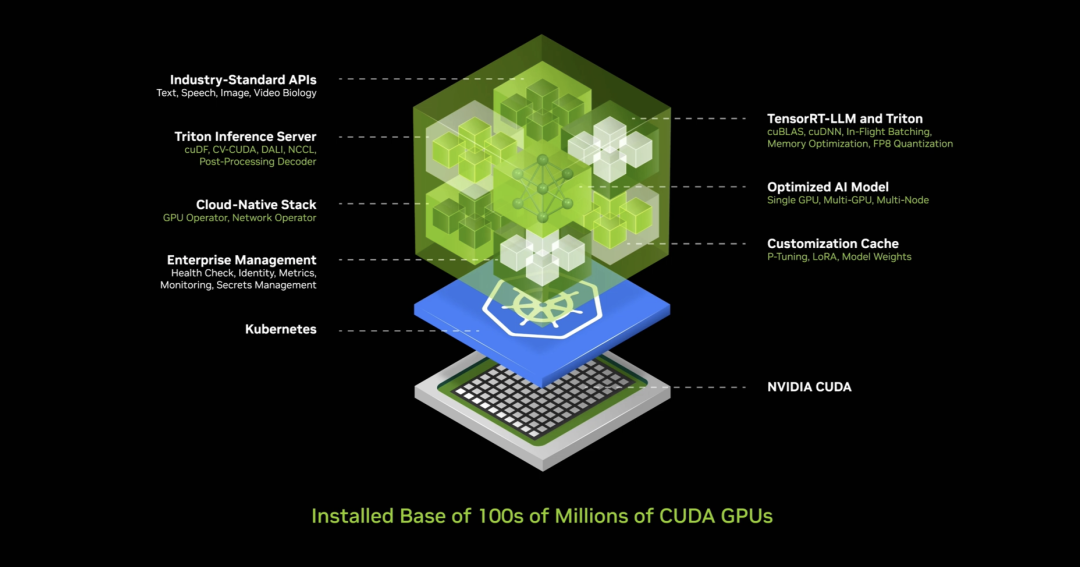
NIMs run inside this factory. Each NIM is a pre-trained model—an AI. While the AI itself is complex, the computational stack required to run it is even more intricate. Behind services like ChatGPT lies a massive software stack. Behind each prompt is extensive underlying software—extremely complex due to models containing billions or trillions of parameters. These models don’t run on a single machine but across multiple machines, distributing workloads across multiple GPUs using tensor parallelism, pipeline parallelism, data parallelism, expert parallelism, and other techniques to maximize processing speed.
Because when operating a factory, throughput directly correlates with revenue, service quality, and user capacity.
We now live in a world where data center throughput utilization is critical. It mattered before, but not as much. It mattered, but wasn’t measured. Today, every parameter is monitored—startup time, runtime, utilization, throughput, idle time—because this is a factory. Factory operations directly affect financial performance, making this complexity extreme for most companies.

So what did NVIDIA do? NVIDIA created an AI container—an “AI box”—packed with comprehensive software. Inside this container reside CUDA, cuDNN, TensorRT, and Triton Inference Server. It’s cloud-native, auto-scalable in Kubernetes environments, includes management services and monitoring hooks for your AI, and features universal APIs—standard interfaces you can “talk” to. Download the NIM and interact with it. As long as your machine has CUDA—which is now ubiquitous—it works. Available in every cloud, from every computer manufacturer, accessible on hundreds of millions of PCs, with all 400 dependencies seamlessly bundled.
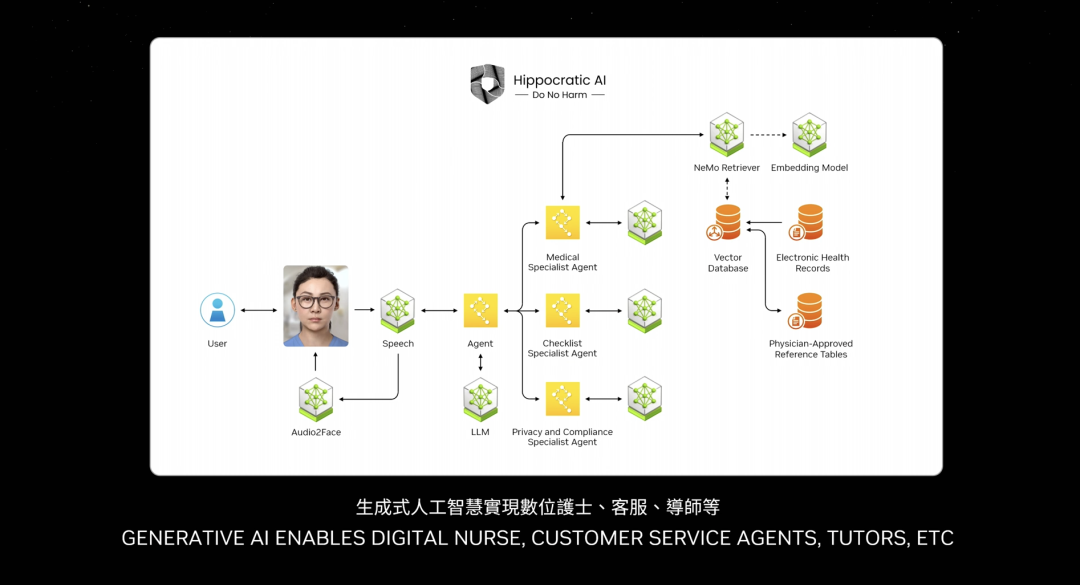
NVIDIA tests every pre-trained model across its entire installed base—across all versions of Pascal, Ampere, Hopper, and beyond. I’ve even forgotten some names. An incredible invention—one of my favorites.
Huang said NVIDIA offers various versions—language-based, vision-based, image-based, healthcare-focused, digital biology, and digital humans—accessible via ai.nvidia.com.
Today, NVIDIA just released a fully optimized Llama3 NIM on HuggingFace—available for you to try and even take away. It’s free. Run it in any cloud. Download the container, deploy it in your own data center, and offer it to your customers.
NVIDIA offers versions across diverse domains—physics, semantic retrieval (RAGs), vision-language, multilingual support. You use them by integrating these microservices into large applications.
One of the most important future applications is customer service. Nearly every industry needs agents—representing trillions in customer service value. Nurses, in some aspects, are customer service agents—non-prescriptive or non-diagnostic nurses are essentially retail customer service, like fast food, banking, insurance. Tens of millions of customer service roles can now be augmented with language models and AI. The boxes you see are essentially NIMs.
Some NIMs are inference agents—they receive tasks, analyze them, break them into plans. Some retrieve information. Some perform searches. Some use tools—like cuOpt mentioned earlier. It could integrate tools running on SAP, requiring knowledge of specific languages like ABAP. Some NIMs may run SQL queries. All these NIMs are specialists, now assembled into teams.
What’s changed? The application layer. Previously, apps were written with instructions. Now, they assemble AI teams. Few know how to write programs, but almost everyone knows how to decompose problems and form teams. I believe every company will soon maintain large collections of NIMs. You’ll download desired experts, connect them into teams—even without knowing exactly how. Just assign a task to an agent—a NIM—and let it determine task distribution. The team leader agent decomposes the task, assigns subtasks to members, collects results, reasons over them, and presents answers—just like humans. This is the near future of applications.
Of course, interaction with these large AI services can happen via text or voice prompts. But many applications desire human-like interaction. NVIDIA calls these Digital Humans and has been researching this technology.
Huang continued: Digital Humans could become excellent interactive agents—more engaging and empathetic. Of course, we must bridge the uncanny valley to make them appear natural. Imagine a future where computers interact with us as naturally as humans. This is the astonishing reality of Digital Humans—set to revolutionize industries from customer service to advertising and gaming. The possibilities are endless.
Using scanned data of your current kitchen, captured via smartphone, they can become AI interior designers—generating photorealistic renovation suggestions with material and furniture sourcing.
NVIDIA has already generated several design options for you to choose from. They can also act as AI customer service agents—making interactions more vivid and personalized—or as digital healthcare workers, assessing patients and delivering timely, personalized care. They might even become AI brand ambassadors, shaping the next wave of marketing and advertising trends.
Breakthroughs in generative AI and computer graphics now allow Digital Humans to see, understand, and interact with us in human-like ways. Judging from what I see, you seem to be in some kind of recording or production setup. The foundation of Digital Humans lies in AI models combining multilingual speech recognition/synthesis and LLMs capable of understanding and generating dialogue.
These AIs connect to another generative AI that dynamically animates a realistic 3D facial mesh. Finally, AI models reproduce lifelike appearances, using real-time path tracing with subsurface scattering to simulate how light penetrates skin, scatters, and exits at different points—giving skin a soft, translucent look.
NVIDIA ACE is a suite of Digital Human technologies, packaged as easily deployable, fully optimized microservices or NIMs. Developers can integrate ACE NIMs into existing frameworks, engines, and Digital Human experiences. Nematon SLM and LLM NIMs understand intent and coordinate other models.
Riva Speech NIMs handle interactive voice and translation. Audio-to-Face and Gesture NIMs animate facial expressions and body movements. Omniverse RTX with DLSS enables neural rendering of skin and hair.
Truly incredible. These ACEs can run in the cloud or on PCs. All RTX GPUs include Tensor Core processors, so NVIDIA has already shipped AI GPUs preparing for this moment. The reason is simple: to create a new computing platform, you first need an installed base.
Eventually, applications will follow. But if you don’t build the installed base, how can applications appear? So if you build it, they may not come. But if you don’t build it, they cannot come. Therefore, NVIDIA embedded Tensor Core processors in every RTX GPU. Now, NVIDIA has 100 million GeForce RTX AI PCs globally—and we’re shipping 200 million.
At this Computex, NVIDIA showcased four stunning new laptops—all capable of running AI. Future laptops and PCs will themselves become AIs—continuously assisting you in the background. PCs will also run AI-enhanced applications.
Of course, all your photo editing, writing tools, and every application you use will be AI-augmented. Your PC will also host AI applications featuring Digital Humans. AI will manifest in various forms on PCs, making them crucial AI platforms.
Where do we go from here? Earlier, I discussed data center scaling. Each time we scale, we discover new leaps. When scaling from DGX to large AI supercomputers, NVIDIA enabled Transformers to train on massive datasets. Initially, training required human-labeled data—an inherently limited resource.
Transformers enabled unsupervised learning. Now, by analyzing vast amounts of data, videos, or images, models can autonomously discover patterns and relationships.
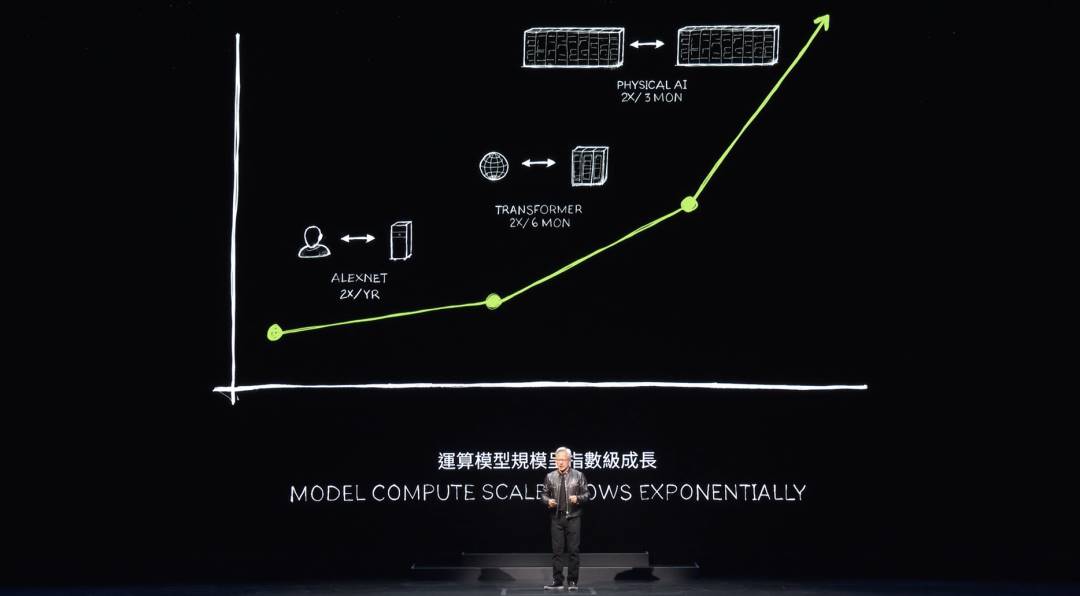
The next generation of AI must be physics-based. Most current AI lacks understanding of physical laws and isn’t grounded in the physical world. To generate images, videos, 3D graphics, and model physical phenomena, we need AI rooted in physics.
One approach is video-based learning. Another is synthetic or simulated data. A third is letting computers learn from each other—similar to AlphaGo playing against itself. Through repeated self-play, systems become smarter over time. You’ll begin seeing this type of AI emerge.
If AI data is synthetically generated and reinforced via reinforcement learning, data generation rates will keep increasing. Each jump in data generation demands corresponding increases in computing power.
We’re approaching a stage where AI learns physical laws and becomes grounded in physically consistent data. Thus, NVIDIA expects models to keep growing—we’ll need larger GPUs.
Blackwell

Blackwell is designed for this generation, featuring several groundbreaking technologies. First, chip size. NVIDIA manufactured the largest chips at TSMC and connected two chips via a 10TB/s interconnect—the world’s most advanced SerDes linking them. Then, NVIDIA placed two chips in one compute node, connected via the Grace CPU.
The Grace CPU serves multiple purposes. During training, it enables rapid checkpointing and restart. During inference and generation, it stores contextual memory—helping AI understand conversation context. This is NVIDIA’s second-generation Transformer Engine, dynamically adjusting precision based on computational layer requirements.
It’s the second-generation GPU with secure AI, allowing service providers to protect AI models from theft or tampering. It features fifth-generation NVLink, enabling multi-GPU connections—I’ll detail this shortly.
This is NVIDIA’s first GPU with Reliability, Availability, and Serviceability (RAS) engines. This RAS system tests every transistor, flip-flop, on-chip memory, and off-chip memory to detect faults in real time. The mean time between failures (MTBF) for a 10,000-GPU supercomputer is measured in hours. For a 100,000-GPU system, MTBF drops to minutes.
Without reliability-enhancing technologies, running large supercomputers for months-long training sessions would be nearly impossible. Improved reliability increases uptime, directly reducing costs. Finally, a decompression engine addresses one of the most critical data processing needs. NVIDIA added data compression and decompression engines, enabling 20x faster data extraction from storage—far exceeding today’s limits.

Blackwell is now in production, packed with advanced technologies. Each Blackwell chip consists of two dies connected together—you’re seeing the world’s largest chip. Two dies linked at 10TB/s deliver astonishing performance.
Each new generation of NVIDIA computing delivers 1000x more floating-point operations. Moore’s Law achieved ~40–60x growth over eight years. Even during Moore’s Law’s peak, progress paled compared to Blackwell’s performance leap.
Computational scale is staggering. Each performance gain reduces cost. NVIDIA reduced GPT-4 training energy needs from 1000 GWh to 3 GWh. Pascal required 1000 GWh—equivalent to a 1GW data center. No such facility exists. Even if one did, it would take a month. A 100MW data center would take about a year. Hence, no one would build it.
That’s why eight years ago, LLMs like ChatGPT were impossible. By improving performance and efficiency, NVIDIA now reduces Blackwell’s energy requirement from 1000 GWh to 3 GWh—an incredible advancement. Training on 10,000 GPUs now takes days—perhaps ten. Progress in just eight years is astounding.
This partly concerns inference and token generation. Generating one GPT-4 token requires the energy of two light bulbs running for two days. Generating a word takes about three tokens. Thus, generating GPT-4 responses with Pascal-level efficiency was practically impossible. Now, each token uses only 0.4 joules—enabling ultra-low-energy token generation.

Blackwell is a giant leap. Still, it’s not big enough. Larger machines are needed. Hence, NVIDIA built DGX.

This is a DGX Blackwell—air-cooled, housing eight GPUs. Notice the massive heatsinks on these GPUs—about 15kW, fully air-cooled. This version supports x86 and integrates into Hopper-based infrastructures NVIDIA has been shipping. We have a new modular system called MGX.
Two Blackwell boards, four Blackwell chips per node. These are liquid-cooled, with 72 GPUs interconnected via new NVLink. This fifth-generation NVLink switch is a technological marvel—the world’s most advanced switch, with astonishing data rates. These switches link every Blackwell together, forming a massive 72-GPU Blackwell system.
The benefit? Within a domain, a GPU cluster now appears as a single GPU—containing 72 instead of the previous 8. Bandwidth increases ninefold. AI floating-point performance improves 18x, overall performance 45x, while power rises only 10x—from 10kW to 100kW. That’s one.
Of course, you can connect more of these—I’ll show how later. But the miracle lies in this chip, the NVLink chip. People are beginning to grasp its importance—it connects all these GPUs. Because LLMs are so large, they can’t fit on one GPU or even one node. They need entire GPU racks—like the new DGX beside me—capable of hosting trillion-parameter LLMs.
The NVLink switch itself is a marvel—50 billion transistors, 74 ports, each at 400Gbps, with 7.2Tbps cross-sectional bandwidth. Crucially, it performs mathematical operations internally—vital for deep learning—enabling on-chip reduction operations. This is today’s DGX.
Huang said many ask why NVIDIA became so large by making GPUs. Some think this is what a GPU looks like.
Now, this is a GPU—one of the world’s most advanced—but it’s a gaming GPU. You and I know what a GP looks like. This, ladies and gentlemen, is a DGX GPU. See the NVLink backbone on the back? It contains 5,000 wires—two miles long—electrically and mechanically connecting two GPUs. Transceivers drive signals across copper, saving 20kW per rack.

Huang noted two types of networks. InfiniBand is widely used in global supercomputing and AI factories, growing rapidly. But not every data center can adopt InfiniBand—they’ve heavily invested in Ethernet ecosystems, and managing InfiniBand switches requires expertise.
Thus, NVIDIA brought InfiniBand capabilities to Ethernet—a very difficult feat. Ethernet was designed for high average throughput because each node connects to different people on the internet—most communication flows between data centers and external users.
However, in deep learning and AI factories, GPUs primarily communicate with each other—exchanging partial results, performing reductions, and redistributing. This traffic is highly bursty. What matters isn’t average throughput, but the last packet arriving. NVIDIA developed several technologies—end-to-end architecture enabling NICs and switches to communicate—using four key techniques. First, NVIDIA has the world’s most advanced RDMA, now enabling network-level RDMA over Ethernet—an incredible achievement.
Second, congestion control. Switches perform rapid telemetry—when GPUs or NICs send too much data, they’re told to back off, preventing hotspots.
Third, adaptive routing. Ethernet requires ordered transmission and reception. NVIDIA detects congestion or unused ports, routes traffic out-of-order to available paths, and BlueField reorders packets at the destination—ensuring correctness. Adaptive routing is powerful.
Finally, noise isolation. Data centers always run multiple models or tasks—background noise and traffic can interfere, causing jitter. When training model noise delays the final arrival, overall training slows significantly.
Remember, you’ve built a $5 billion or $3 billion data center for training. If network utilization drops 40%, extending training by 20%, that $5 billion center effectively costs $6 billion. Financial impact is huge. Spectrum X Ethernet enables massive performance gains—making networking nearly free.
NVIDIA has a full line of Ethernet products. This is Spectrum X800—51.2Tbps, 256 ports. Next comes 512 ports—Spectrum X800 Ultra—launching next year. Then X16. Key idea: X800 scales to tens of thousands of GPUs, X800 Ultra to hundreds of thousands, X16 to millions. The million-GPU data center era is coming.
In the future, nearly every interaction with the internet or computers will involve a generative AI somewhere. This AI collaborates with you—generating videos, images, text, or even a Digital Human. You’ll constantly interact with computers—always connected to a generative AI, partly local, partly on your device, mostly in the cloud. These generative AIs will perform extensive inference—not one-off answers, but iteratively refining output quality. The volume of generated content will be staggering.
Blackwell marks NVIDIA’s first platform generation as the world recognizes the dawn of the generative AI era—just as awareness grows about AI factories and the start of a new industrial revolution. NVIDIA enjoys support from virtually all OEMs, computer manufacturers, cloud providers, GPU clouds, sovereign clouds, and even telecom companies. Blackwell’s success, adoption, and enthusiasm are incredible. Thank you all.
Huang continued, during this period of astonishing growth, NVIDIA remains committed to boosting performance, lowering training and inference costs, and expanding AI accessibility for every company. The greater the performance gains and cost reductions we drive, the broader the impact. The Hopper platform is undoubtedly the most successful data center processor in history—an incredible success story.
Yet, Blackwell has arrived. Each platform, as you see, comprises several components: CPU, GPU, NVLink, network interface, and NVLink switches connecting all GPUs into maximally scalable domains. Whatever we can connect, we link via large-scale, ultra-high-speed switches.
With each generation, you’ll find it’s not just the GPU—but the entire platform. We build the complete platform, integrate it into an AI factory supercomputer, then decompose and deliver it to the world. Why? So you can create innovative configurations tailored to different data centers and customer needs—some for edge computing, some for telecom. Innovation flourishes when systems are open and you’re empowered to innovate. Thus, NVIDIA designs integrated platforms but breaks them down for customers—enabling modular systems.
The Blackwell platform has arrived. NVIDIA’s core philosophy is simple: build an entire data center annually, disassemble it, and sell components—pushing every technology to its limit: TSMC’s process and packaging, memory, SerDes, optical tech—all pushed to extremes. Then ensure all software runs across the entire installed base.
Software inertia is paramount in computing. When systems are backward-compatible and align with existing software architectures, time-to-market accelerates dramatically. Leveraging an established software ecosystem delivers astonishing speed.

Huang said Blackwell has arrived. Next year brings Blackwell Ultra—just as H100 was followed by H200, you may see exciting new Blackwell Ultra generations pushing boundaries. The next-generation Spectrum switch I mentioned achieves a leap never before possible. The next platform is called Rubin, followed a year later by Rubin Ultra.
All these chips shown are under full-speed, 100% development. This is NVIDIA’s annual rhythm—all 100% architecture-compatible, with a rich software ecosystem under continuous development.
AI Robotics

Let me discuss what comes next—the next wave of AI is physical AI—understanding physical laws and working alongside us. Such systems must comprehend world models—how to interpret and perceive the world. They also need strong cognitive abilities to understand our requests and execute tasks.
Robotics is a broader concept. When I say robots, you might picture humanoid robots—but that’s incomplete. Everything will become robotic. All factories will be robotized—factories coordinating robots that manufacture robotic products, with robots collaborating to build more robots. Achieving this requires breakthroughs.
Next, Huang presented a video stating:
The robot era has arrived. Within a day, everything that moves will be autonomous. Researchers and companies worldwide are developing robots powered by physical AI—models that understand instructions and autonomously perform complex tasks in the real world. Multimodal LLMs are the breakthrough, enabling robots to learn, perceive, understand their surroundings, and plan actions.
Through human demonstration, robots can now learn required skills—interacting with the world using gross and fine motor skills. A key technology advancing robotics is reinforcement learning. Just as LLMs use RLHF to master specific skills, physical AI can learn skills in simulated worlds using physical feedback. These simulation environments allow robots to learn decision-making by performing actions in virtual worlds governed by physical laws. In these robot gyms, robots safely and rapidly learn complex, dynamic tasks—refining skills through millions of trial-and-error iterations.
NVIDIA built NVIDIA Omniverse as the operating system for physical AI. Omniverse is a virtual world simulation development platform combining real-time physical rendering, physics simulation, and generative AI. In Omniverse, robots learn to become robots—mastering precise object manipulation like grasping and moving items, or autonomously navigating environments, finding optimal paths while avoiding obstacles and hazards. Learning in Omniverse minimizes the simulation-to-reality gap and maximizes skill transfer.
Building robots with generative physical AI requires three computers: an NVIDIA AI Supercomputer to train models, NVIDIA Jetson Orin and next-gen Jetson Thor robot supercomputers to run models, and NVIDIA Omniverse—where robots learn and improve skills in simulation. We provide the platforms, accelerated libraries, and AI models developers and companies need—letting them use the best stack. The next wave of AI has arrived. Robots powered by physical AI will transform every industry.
Huang emphasized this isn’t the future—it’s happening now. NVIDIA will serve this market in several ways. First, we’ll create platforms for every robot type: robotic factories and warehouses, manipulator robots, mobile robots, and humanoid robots. Each robot platform—like nearly everything NVIDIA does—comprises a computer, accelerated libraries, and pre-trained models. Computer, accelerated libraries, pre-trained models. Everything tested, trained, and integrated in Omniverse—as the video said, robots learn to be robots here.
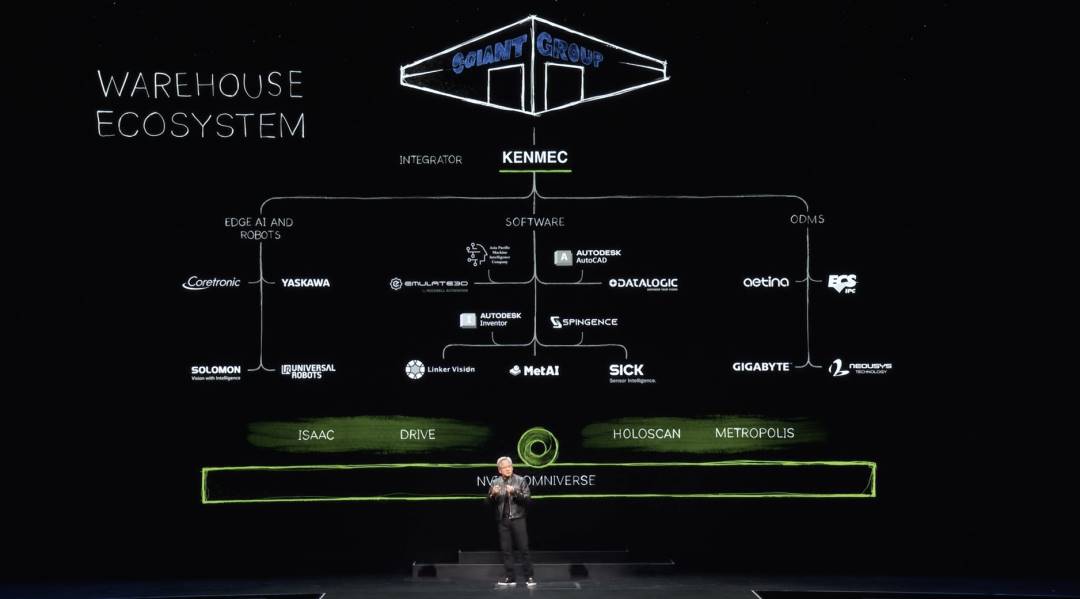
Of course, the robot warehouse ecosystem is highly complex. Building modern warehouses involves many companies, tools, and technologies—warehouses becoming increasingly automated. One day, they’ll be fully automated. Each ecosystem includes SDKs and APIs connecting to software industries, edge AI sectors, ODMs, PLCs, and robotic systems. Integrators assemble these into complete customer solutions. Here’s an example: Kenmac building a robotic warehouse for Giant Group.
Huang continued: factories have entirely different ecosystems. Foxconn is building some of the world’s most advanced factories. Their ecosystem again includes edge computers and robots, software for designing factories and workflows, programming robots, and PLC computers coordinating digital and AI factories. NVIDIA provides SDKs connecting to each ecosystem—something happening throughout Taiwan.

Foxconn is building digital twins for its factories. Delta is building digital twins for its factories. By the way, half real, half digital—half Omniverse. Pegatron is building digital twins for its robotic factories. Quanta is building digital twins for its robotic factories.
Huang then demonstrated a video stating:

Join TechFlow official community to stay tuned Telegram:https://t.me/TechFlowDaily X (Twitter):https://x.com/TechFlowPost X (Twitter) EN:https://x.com/BlockFlow_News










