蒸馏不是抄袭,而是技术演进的必要手段。
作者:邓咏仪,智能涌现

图片来源:由无界AI生成
2025年春节期间,最红的不止是哪吒2,还有一个名为DeepSeek的应用——这个励志故事被传颂多次:1月20日,位于杭州的AI初创公司DeepSeek(深度求索)发布了新模型R1,对标OpenAI如今最强的推理模型o1,真正意义上做到了引爆全球。
上线仅仅一周,DeepSeek App已经斩获超2000万的下载量,在超过140个国家排名第一。其增长速度超越了2022年时上线的ChatGPT,目前已是后者的约20%。
火到什么程度?截至2月8日,DeepSeek的用户数已经超过1亿,覆盖的人群远不止AI极客,而是已经从中国,延伸到全球。从老人、儿童到脱口秀演员、政客,人人都在谈论DeepSeek。
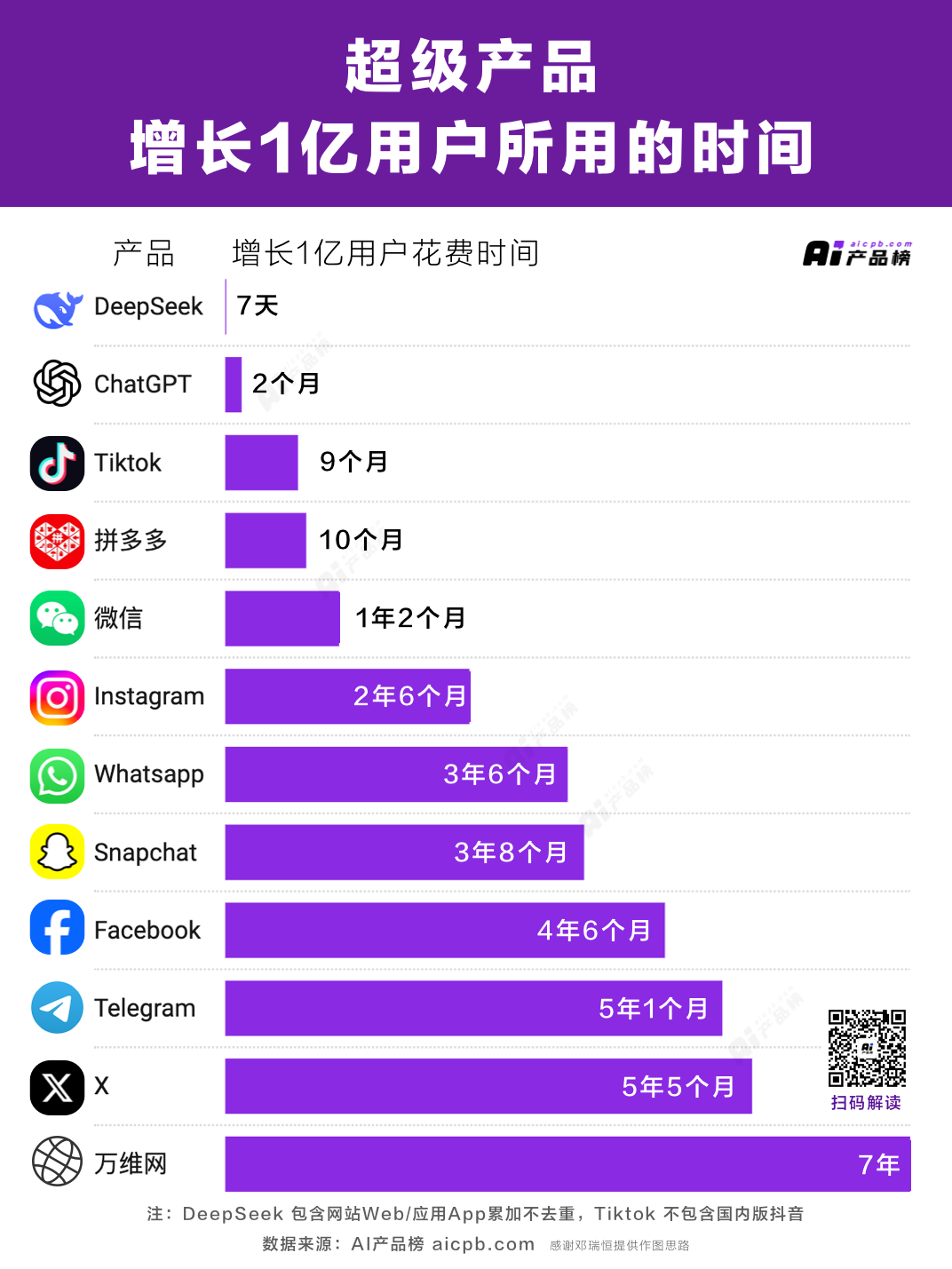
直到现在,DeepSeek带来的震动还在持续。过去两周,DeepSeek走马灯似地演完了TikTok的剧本——爆火和高速增长,打败美国诸多对手,甚至让DeepSeek迅速站到地缘政治的悬崖上:美国和欧洲开始讨论”影响国家安全”,许多地区迅速颁发禁止下载或安装的命令。
A16Z合伙人Marc Andreessen甚至惊叹:DeepSeek的出现,是又一个“斯普尼克时刻”(Sputnik Moment)。
(一个源于冷战时期的说法,苏联在1957年成功发射全球首颗人造卫星“斯普特尼克一号”,引起了美国社会的恐慌,意识到自身地位受到挑战,技术优势可能被倾覆)
但人红是非多,在技术圈内,DeepSeek同样也陷入“蒸馏”、“盗窃数据”等等争议中。
截至目前,DeepSeek没有任何公开回应,这些争论也随之落入两个极端:狂热的追捧者,将DeepSeek-R1上升至“国运级”创新;也有科技从业者,对DeepSeek的超低训练成本、以及蒸馏训练方式等等提出质疑,认为这些创新被过于追捧。
Deepseek“盗窃”OpenAI?更像是贼喊捉贼
几乎从DeepSeek爆火开始,包括OpenAI、微软等硅谷AI巨头就相继公开发声,控诉重点都落在DeepSeek的数据上。美国政府AI和加密主管大卫·萨克斯也公开表示,DeepSeek通过一种称为蒸馏的技术,“吸取”ChatGPT的知识。
OpenAI在英国《金融时报》的报道中表示,已经发现了DeepSeek“蒸馏”ChatGPT的迹象,并表示这违反了OpenAI的模型使用条约。不过,OpenAI并没有给出具体的证据。
事实上,这是一则站不住脚的指控。
蒸馏是正常的大模型训练技术手段。这常发生在模型的训练阶段——通过使用更大、更强大的模型(教师模型)的输出,来让较小模型(学生模型)学习更好的性能。在特定任务上,较小的模型能够以更低的成本,获得类似的结果。
蒸馏也并不是抄袭。用通俗的话解释,蒸馏更像是让一位老师刷完所有难题,整理出完美的解题笔记——这本笔记里不是仅有答案,而是写着各种最优解法;普通学生(小模型)只需要直接学习这些笔记,然后输出自己的答案,对照笔记看看是否符合老师笔记中的阶梯思路。
而DeepSeek最突出的贡献在于,在这个过程中更多地使用了无监督学习——就是让机器自我反馈,减少人类反馈(RLHF)。最直接的结果就是,模型的训练成本大大下降——这也是不少质疑声的由来。
DeepSeek-V3论文曾提及其V3模型的具体训练集群规模(2048块H800芯片)。不少人按市场价格估算,这个金额大约在550万美元左右,相当于Meta、Google等模型训练成本的数十分之一。
但需要注意的是,DeepSeek早已在论文中注明,这仅是最后一次训练的单次运行成本,没有将前期的设备、人员、训练耗损包括在内。
在AI领域,蒸馏不也是新鲜事,不少模型厂商都曾披露过自家的蒸馏工作。比如,Meta就曾公布过自家模型是怎么蒸馏出来的——Llama 2就用更大、更聪明的模型生成包含思考过程、思考方法的数据,然后放到自家更小规模的推理模型中,进行微调。
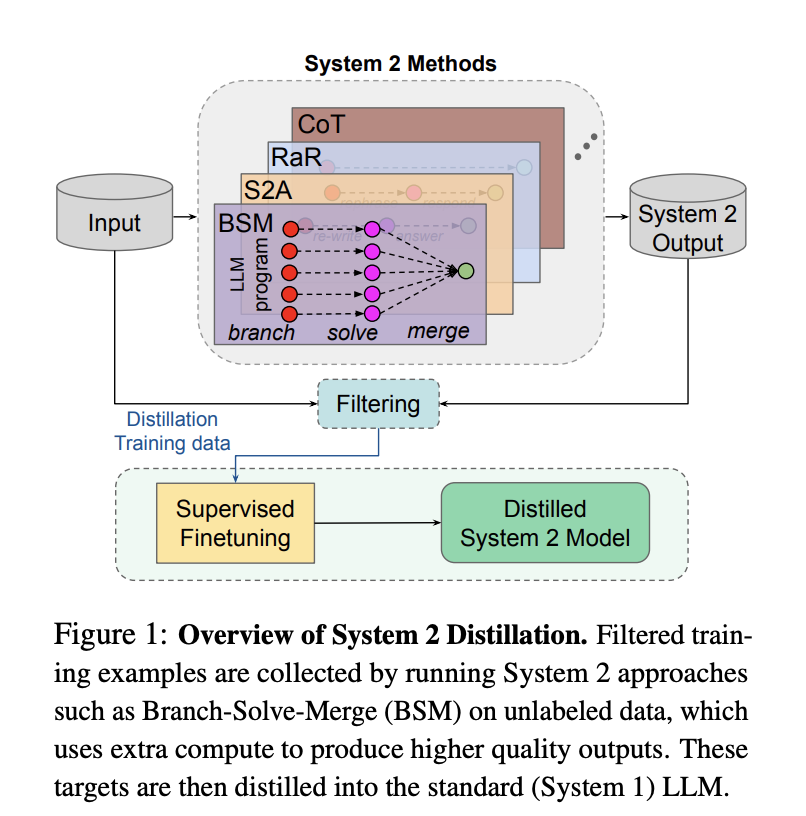
△来源:Meta FAIR
但蒸馏也有其弊端。
一位大厂AI应用从业者告诉《智能涌现》,蒸馏能够快速让模型能力快速上升,但其弊端是在于“教师模型”生成的数据过于干净,缺乏多样性。学习这类数据,模型会更像一道中规中矩的“预制菜”,其能力也没有办法超过教师模型。
数据质量很大程度上决定了模型训练的效果。如果选择用蒸馏完成大部分的模型训练,反而会让模型显得过于同质化。如今全球的大模型已经琳琅满目,各家的模型也都会提供自己模型的“精华版”,蒸馏一个一模一样的模型,并无太大意义。
更致命的问题在于,幻觉问题或许会更加严重。这是因为小模型某种程度上只模仿大模型的“皮”,难以深入理解背后的逻辑,容易导致在新任务上表现下降。
所以,如果要让模型有自己的特点,AI工程师需要从数据阶段就开始介入——选择什么样的数据、数据配比,以及训练方法,都会让最终训练出来的的模型非常不一样。
典型例子是如今的OpenAI和Anthropic。OpenAI和Anthropic是最早做大模型的一批硅谷公司,双方都没有现成的模型可供蒸馏,而是直接从公开网络和数据集爬取、学习。
不同的学习路径,也导致两个模型现在的风格有显著不同——如今,ChatGPT更像是一个板正的理工生,擅长解决生活工作中的各类问题;而Claude则更擅长于文科,在写作任务上是公认的口碑王,但代码任务也并不逊色。
OpenAI指控的另一讽刺之处在于,用一个边界模糊的条款来指控DeepSeek,即使自己也做了类似的事情。
成立之初,OpenAI一直是一个开源为导向的组织,但在GPT-4之后转向闭源。OpenAI的训练几乎爬遍了全球公开互联网的数据。因此在选择闭源后,OpenAI也一直深陷于和新闻媒体、出版商的版权纠纷中。
OpenAI对DeepSeek的“蒸馏”指控,被讽刺为“贼喊捉贼”就在于,无论是OpenAI o1还是DeepSeek R1,在论文中都没有披露自己在数据准备上的细节,这个问题还是罗生门一样的存在。
更何况,DeepSeek-R1发布时甚至是选择了MIT开源协议——几乎是最宽松的开源协议。DeepSeek-R1允许商用、允许蒸馏,还为公众提供了六个蒸馏好的小模型,用户可以直接部署到手机、PC中,是极有诚意的回馈开源社区的行为。
2月5日,原Stability AI研究主管Tanishq Mathew Abraham也专门撰文,指出这个指控踩在了灰色地带:首先,OpenAI并没有拿出证据,显示DeepSeek直接利用GPT蒸馏。他所猜测的一种可能的情况是,DeepSeek找到了利用ChatGPT生成的数据集(市面上已有很多),而这种情况并没有被OpenAI明令禁止。
蒸馏是判断做不做AGI的标准吗?
在舆论场上,如今不少人用“是否蒸馏”这一步来划定是否抄袭、是否做AGI,这未免过于武断。
DeepSeek的工作重新带火了“蒸馏”这个概念,事实上这是在近十年前就已经出现的技术。
2015年,由几位AI大牛Hinton、Oriol Vinyals、Jeff Dean联合发布的论文《Distilling the Knowledge in a Neural Network》里,就正式提出了大模型里的“知识蒸馏”技术,这也成为了后续大模型领域的标配。
对于钻研特定领域、任务的模型厂商而言,蒸馏是其实一条更加现实主义的路径。
一名AI从业者告诉智能涌现,国内几乎没有多少大模型厂商不做蒸馏,这几乎是公开的秘密。“现在公开网络的数据已经几乎消耗殆尽,从0到1做预训练、数据标注的成本,即使是大厂,也很难说可以轻松承担。”
一个例外是字节跳动。在近期发布的豆包1.5 pro版本中,字节明确表示“在训练过程中从未使用过任何其他模型生成的数据,坚决不走蒸馏捷径”,表示其追求AGI的决心。
大厂选择不蒸馏有其现实考虑,比如可以规避许多后续的合规纷争。在闭源的前提下,这也会为模型能力建造一定壁垒。据《智能涌现》了解,字节如今的数据标注成本,已经是对标硅谷的水平——最高可达200美金一条,这种高质量数据,就需要各个特定领域的专家,比如硕士、博士以上级别的人才,进行标注。
对AI领域中更多的参与方而言,无论是用蒸馏还是其他工程手段,本质上都是一种对Scaling Law(规模效应法则)边界的探索。这是探索AGI的必要条件,而非充分条件。
大模型爆火的前两年,Scaling Law通常被粗暴地理解为“大力出奇迹”,即堆算力、参数,就能让智能涌现,这更多是在预训练阶段。
如今“蒸馏”被火热讨论的背后,暗线其实是大模型发展范式发生演变:Scaling Law依然存在,但从预训练阶段,真正转移到了后训练和推理阶段。
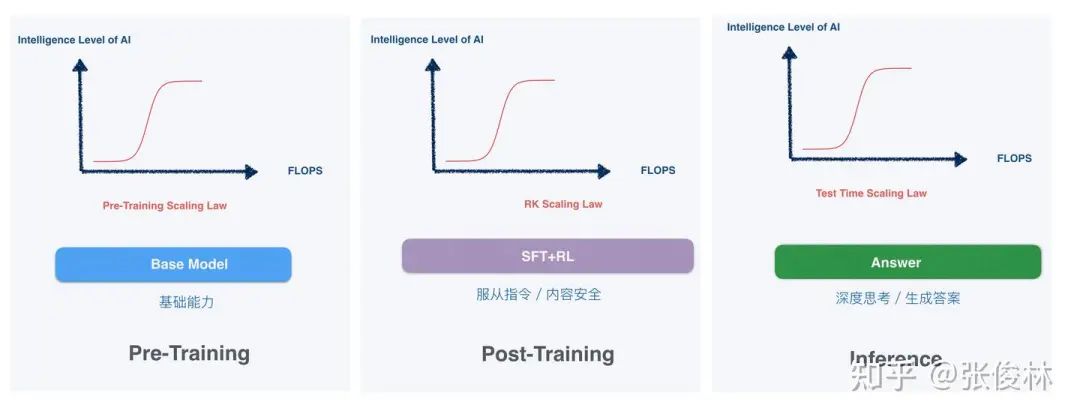
△来源:中科院软件所博士张俊林专栏文章
OpenAI的o1在2024年9月发布,被认为是Scaling Law转向后训练和推理的标志,目前仍是全球最领先的推理模型。但问题在于,OpenAI从未对外公开其训练方法和细节,应用成本还持续停留在高位:o1 pro的成本高达200美元/月,而且推理速度还慢,这也被认为是AI应用开发的一大桎梏。
这段时间AI圈内的工作,大部分都是在复现o1的效果,同时还需要将推理成本降低,这才能在更多场景中进行应用。DeepSeek的里程碑意义,不仅来自于大大缩短了开源模型追赶顶尖闭源模型的时间——仅仅用了三个月左右,就几乎追赶上o1的多个指标;更重要的是在找到了o1的能力跃升关键诀窍,并将其开源。
不可忽视的一个大前提是,DeepSeek是站在巨人的肩膀之上完成的这次创新。仅仅将“蒸馏”等工程手段视作抄近路就过于狭隘了,这更多是开源文化的胜利。
DeepSeek所带来的生态共荣和开源效应,已经迅速显现。在其爆火后不久,“AI教母”李飞飞的一项新工作也迅速刷屏:让谷歌旗下的Gemini作为“教师模型”,微调后的阿里Qwen2.5作为“学生模型”,通过蒸馏等方式,用不到50美元的费用,训练出了推理模型s1,复现了DeepSeek-R1和OpenAI-o1的模型能力。
英伟达也是典型案例。在DeepSeek-R1发布后,虽然英伟达市值一夜之间爆跌约6000亿美元,创造了史上最大单日蒸发规模,但在第二天很快就强势反弹,上涨了约9%——市场普遍对R1带来的强大推理需求依然抱有期待。
可以预见,大模型领域上的各方吸收R1能力之后,一波AI应用创新热潮也会随之而来。




 个人中心
个人中心 退出登录
退出登录 TRUMP12.18 17.50%
TRUMP12.18 17.50%
 SUI2.35 8.78%
SUI2.35 8.78%
 TON2.87 5.67%
TON2.87 5.67%
 TRX0.22 -0.95%
TRX0.22 -0.95%
 DOGE0.17 4.70%
DOGE0.17 4.70%
 XRP2.36 5.01%
XRP2.36 5.01%
 SOL132.97 8.57%
SOL132.97 8.57%
 BNB584.82 0.97%
BNB584.82 0.97%
 ETH1929.81 4.52%
ETH1929.81 4.52%
 BTC84480.67 5.24%
BTC84480.67 5.24%




 首页
首页 深潮精选
深潮精选 Research
Research 项目发现
项目发现 7x24h︎快讯
7x24h︎快讯 最新活动
最新活动
 分享至微信
分享至微信
 原文链接
原文链接 添加收藏
添加收藏 分享社交媒体
分享社交媒体 精选解读
精选解读

 今日链上资金流向:以太坊净流入1450万美元,Arbitrum净流出1760万美元
今日链上资金流向:以太坊净流入1450万美元,Arbitrum净流出1760万美元





 扫码关注公众号
扫码关注公众号





