Bittensor is the hope of the entire crypto village.
TechFlow Selected TechFlow Selected
Bittensor is the hope of the entire crypto village.
In the overarching debate—“Does Crypto Still Have a Purpose?”—Bittensor is delivering the industry’s most compelling answer.
Author: 0xai
Special thanks to @DistStateAndMe and their team for their contributions to the open-source AI model space, as well as for their invaluable feedback and support on this report.
Why You Should Pay Attention to This Report
If “decentralized AI training” has shifted from impossible to possible—how much has Bittensor been underestimated?
Early 2026 saw widespread fatigue across the crypto community.
The afterglow of the last bull market had long faded, and talent was rapidly migrating to the AI industry. Those once speculating about the “next 100x” were now discussing Claude CodeOpenclaw. “Crypto is a waste of time”—you’ve likely heard that phrase more than once.
But on March 10, 2026, a Bittensor subnet named Templar quietly announced something extraordinary.
Over 70 independent participants from around the world—no central server, no corporate coordination—collaboratively trained a 72-billion-parameter AI large language model, solely powered by crypto-based incentives.
The model and its associated paper have been published on HuggingFace and arXiv, with all data publicly verifiable.
Even more critically: the model outperformed Meta’s heavily funded, same-scale model across multiple key benchmarks.
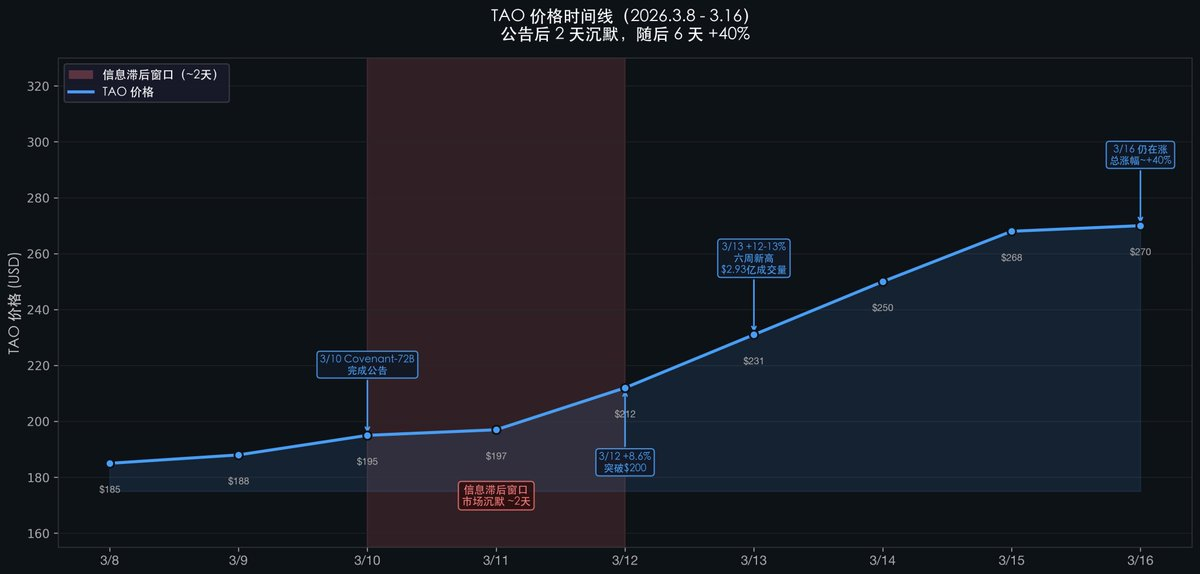
After the announcement, TAO’s price remained flat for nearly two days—only beginning its surge on Day 3. That rally continued unabated for six days, delivering a total gain of approximately +40%. Why the two-day delay?
The core argument of this report is that crypto investors see “just another open-source model,” deeming it inferior to daily-use models like GPT or Claude, while AI researchers ignore crypto altogether. This chasm between two communities is creating a cognitive arbitrage window.
Reading Framework
This report is structured in two logical parts:
Part I — Technical Breakthrough: Explaining what SN3 Templar actually achieved—and why it marks a historic milestone for both AI and crypto.
Part II — Industry Implications: Explaining why this event signals Bittensor’s ecosystem is systematically undervalued—and why Bittensor may be crypto’s best hope.
Part I: The Breakthrough in Decentralized AI Training
1. What Does SN3 Do?
What does it take to train a large language model?
Traditional answer: Build a massive data center, purchase tens of thousands of top-tier GPUs, spend hundreds of millions of dollars, and coordinate everything through a single company’s engineering team—exactly how Meta, Google, and OpenAI operate.
SN3 Templar’s approach: Enable globally distributed individuals to contribute one or several GPU servers each, assembling computational power like puzzle pieces to collaboratively train a complete large model.
Yet a fundamental challenge remains: If participants are scattered worldwide, distrustful of one another, and subject to unstable network latency—how do you ensure training results are valid? How do you prevent free-riding or cheating? How do you incentivize sustained contribution?
Bittensor provides the answer: Use TAO tokens as incentive. The more effective a participant’s gradient (i.e., their contribution to model improvement), the more TAO they earn. The system automatically scores and settles rewards—no centralized authority required.
This is Bittensor’s SN3 (Subnet #3), codenamed Templar.
If Bitcoin proved decentralized “money” is possible, SN3 is proving decentralized “AI training” is possible too.
2. What Did SN3 Achieve?
On March 10, 2026, SN3 Templar announced completion of the large language model training project named Covenant-72B.
What does “72B” mean? 72 billion parameters—the “knowledge storage units” of an AI model. More parameters generally correlate with greater capability. GPT-3 has 175 billion; LLaMA-2 (Meta’s flagship open-source model) has 70 billion. Covenant-72B sits at the same scale.
How large was the training corpus? ~1.1 trillion tokens ≈ 5.5 million books (assuming 200,000 words per book).
Who participated? Over 70 independent contributors (“miners”) contributed compute over time (with ~20 nodes synced per round). Training began on September 12, 2025, and lasted approximately six months—no central server, no coordinating institution.
How did the model perform? Benchmarking against mainstream AI evaluation suites:
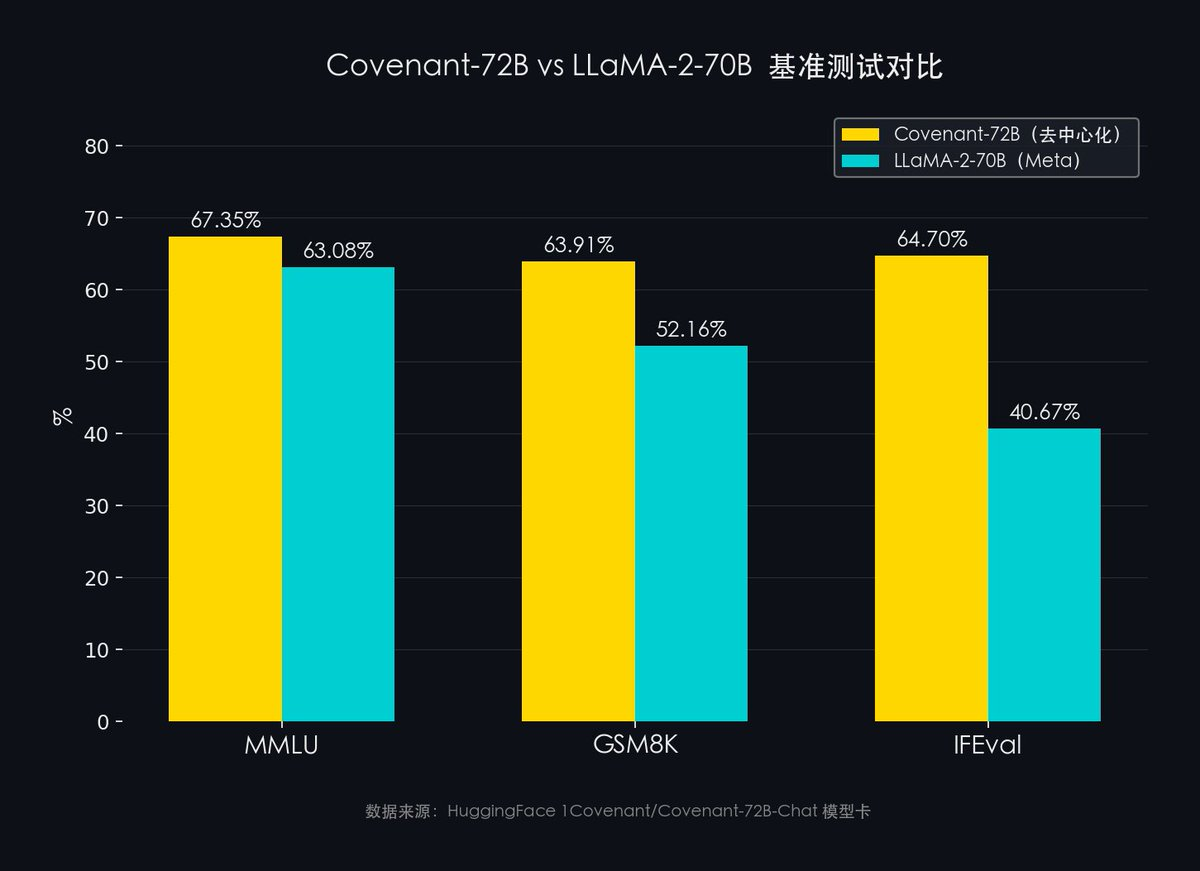
Data source: HuggingFace 1Covenant/Covenant-72B-Chat model card
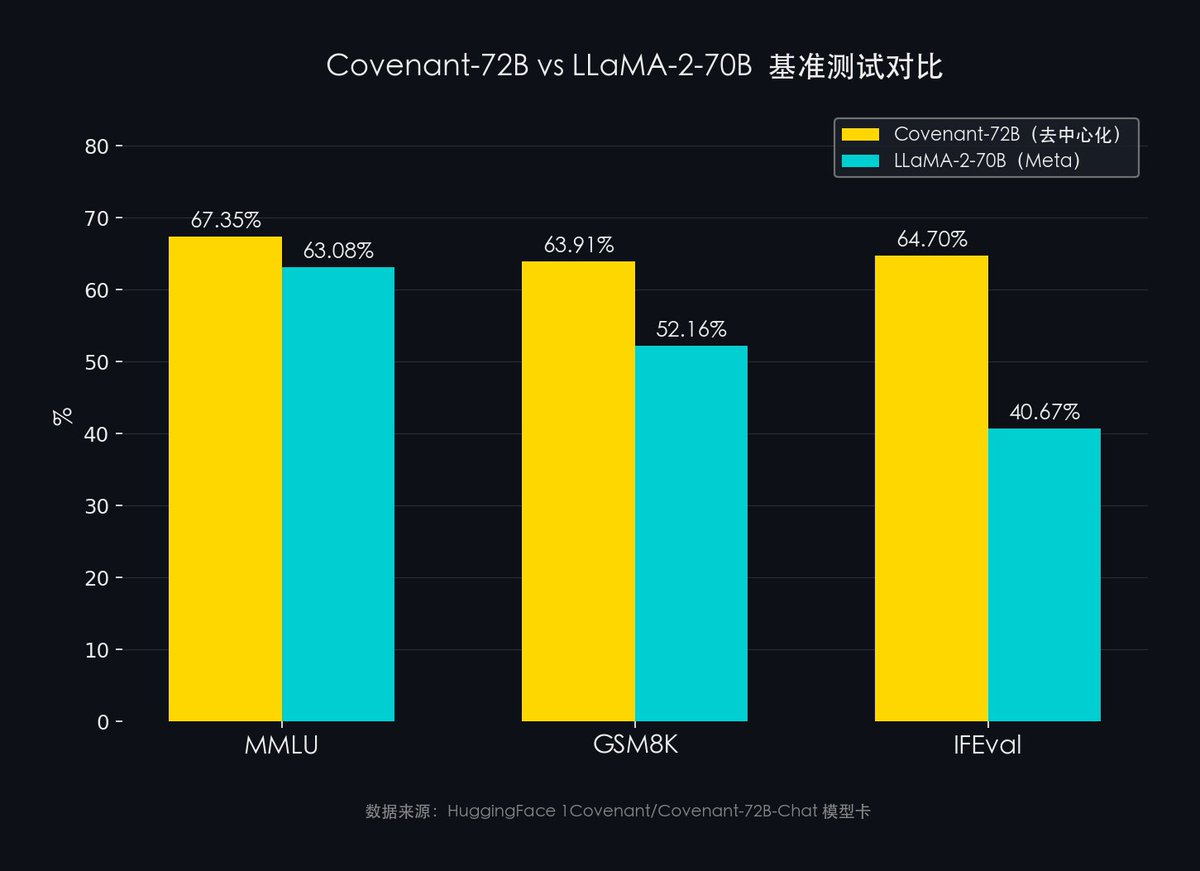
- MMLU (57-subject general knowledge): Covenant-72B 67.35% vs. Meta LLaMA-2 63.08%
- GSM8K (mathematical reasoning): Covenant-72B 63.91% vs. Meta LLaMA-2 52.16%
- IFEval (instruction-following ability): Covenant-72B 64.70% vs. Meta LLaMA-2 40.67%
Fully open-source: Licensed under Apache 2.0—free to download, use, and commercialize without restrictions.
Academically backed: Paper submitted to [arXiv 2603.08163]; core technologies (the SparseLoCo optimizer and Gauntlet anti-cheating mechanism) presented at the NeurIPS Optimization Workshop.
3. What Does This Achievement Mean?
For the open-source AI community: Historically, training 70B-class models required capital and compute resources only accessible to a handful of large corporations. Covenant-72B proves, for the first time, that a community—without any centralized funding—can train a model of comparable scale. It redefines who qualifies to participate in foundational AI model development.
For AI power structures: Today’s foundational model landscape is highly centralized—dominated by OpenAI, Google, Meta, and Anthropic. The viability of decentralized training implies this moat may not be insurmountable. The premise that “only big companies can build foundational models” has been shaken—for the first time.
For the crypto industry: This is the first time a crypto-native project has delivered tangible, verifiable technical contributions to AI—not just hype or buzzword bundling. Covenant-72B comes with a HuggingFace model, arXiv paper, and public benchmark data. It sets a precedent: crypto incentive mechanisms can serve as serious infrastructure for AI research.
For Bittensor itself: SN3’s success transforms Bittensor from a “theoretically plausible decentralized AI protocol” into a “practically validated decentralized AI infrastructure.” This is a qualitative leap—from zero to one.
4. SN3’s Historical Significance
Decentralized AI training isn’t new—but SN3 went further than predecessors ever did.
Evolution of Decentralized Training:
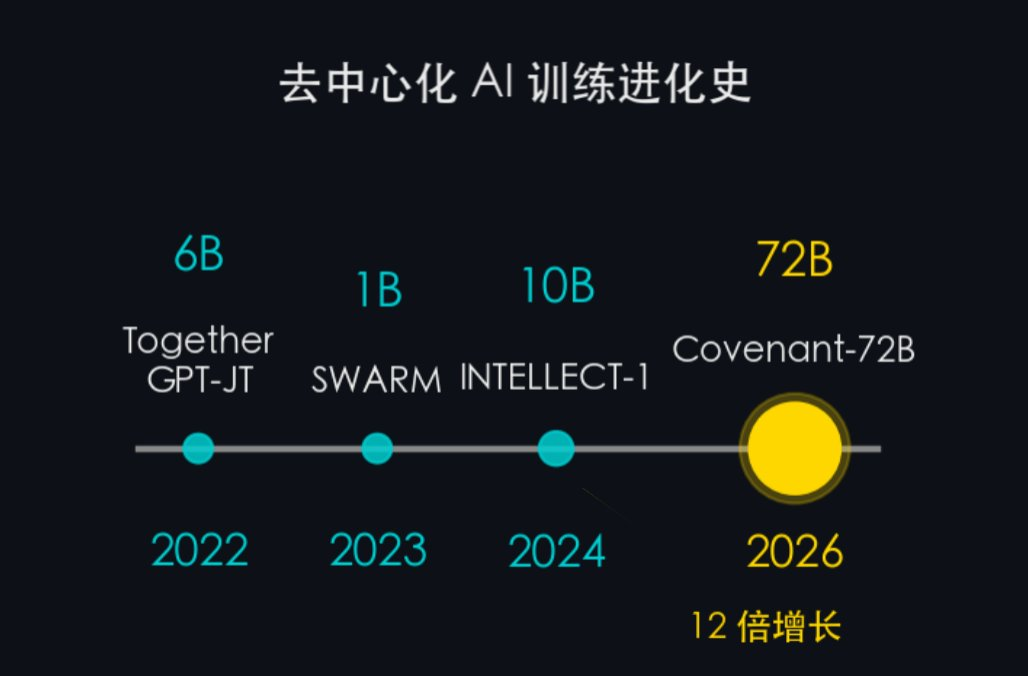
- 2022 — Together GPT-JT (6B): Early proof-of-concept showing multi-machine collaboration is feasible
- 2023 — SWARM Intelligence (~1B): Introduced heterogeneous node collaborative training framework
- 2024 — INTELLECT-1 (10B): Cross-institutional decentralized training
- 2026 — Covenant-72B / SN3 (72B): First 72B decentralized model to surpass centralized counterparts on mainstream benchmarks
In four years, parameter count jumped from 6B to 72B—a 12× increase. But more important than size is quality: earlier generations mainly focused on “getting it to run”; Covenant-72B is the first decentralized large model to outperform centralized models on mainstream benchmarks.
Key Technical Breakthroughs:
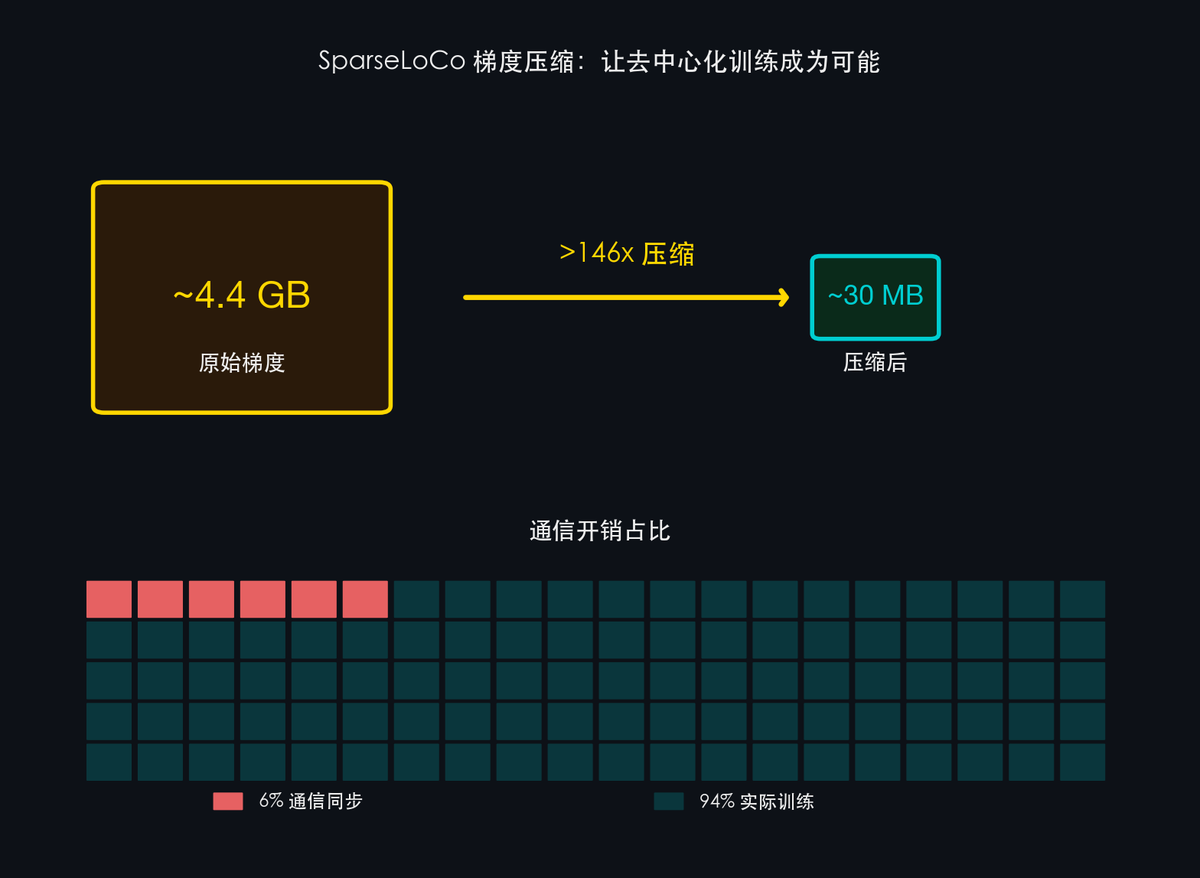
- >99% compression rate (>146×): Each participant uploads gradients—normally GB-scale data—but SparseLoCo compresses them over 146× end-to-end, preserving near-lossless fidelity. Think compressing an entire TV season into a single image.
- Only 6% communication overhead: Among 100 collaborators, just 6% of time is spent on “coordination”; 94% is devoted to actual training. This solves one of decentralized training’s biggest bottlenecks.
5. Is Decentralized Training Underestimated?
Let the data speak first—then draw conclusions.
Evidence of Underestimation
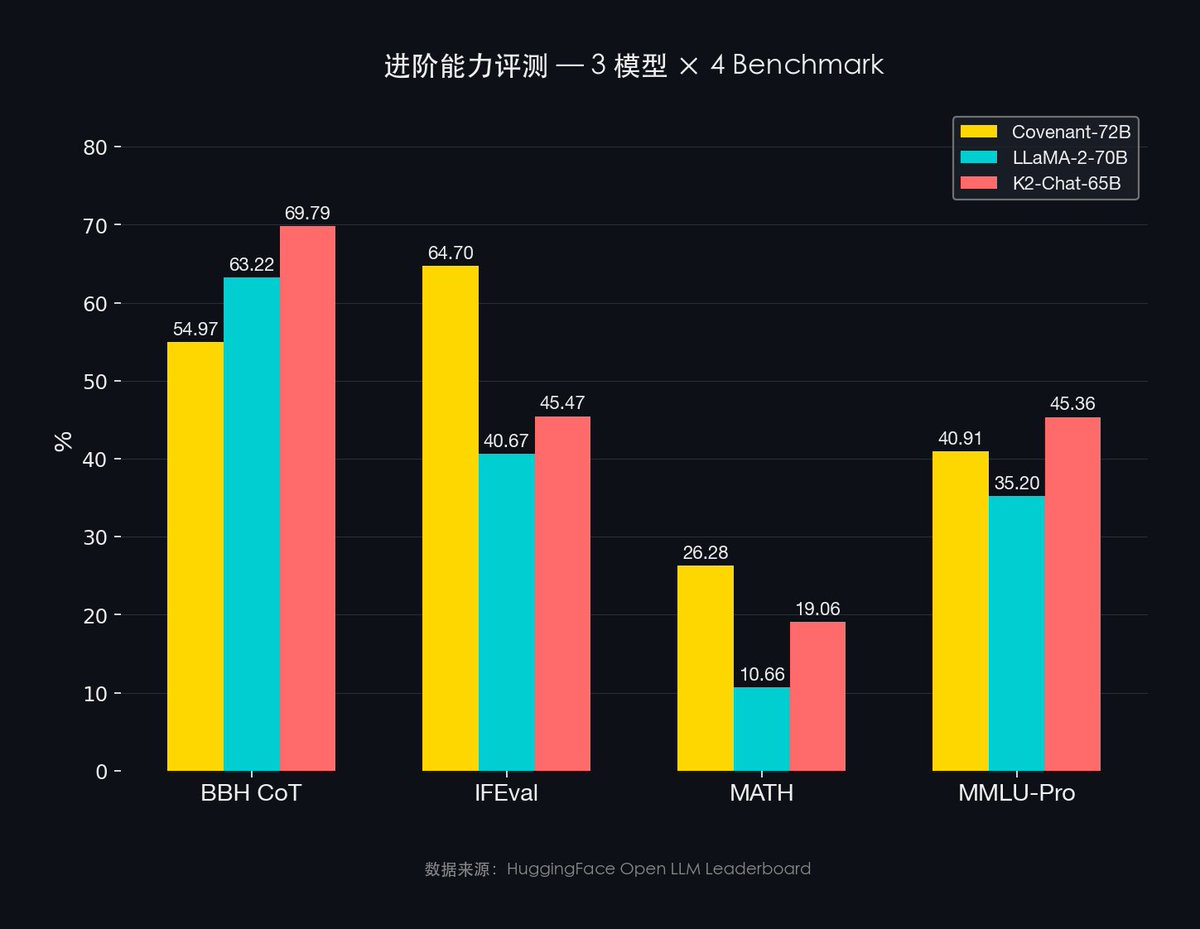
- MMLU: 67.35% vs. LLaMA-2 63.08%
- MMLU-Pro: 40.91% vs. LLaMA-2 35.20%
- IFEval: 64.70% vs. LLaMA-2 40.67%
A decentralized model outperformed Meta’s heavily funded LLaMA-2-70B.
Gap vs. Current Leading Open-Source Models (Honest Assessment Required):
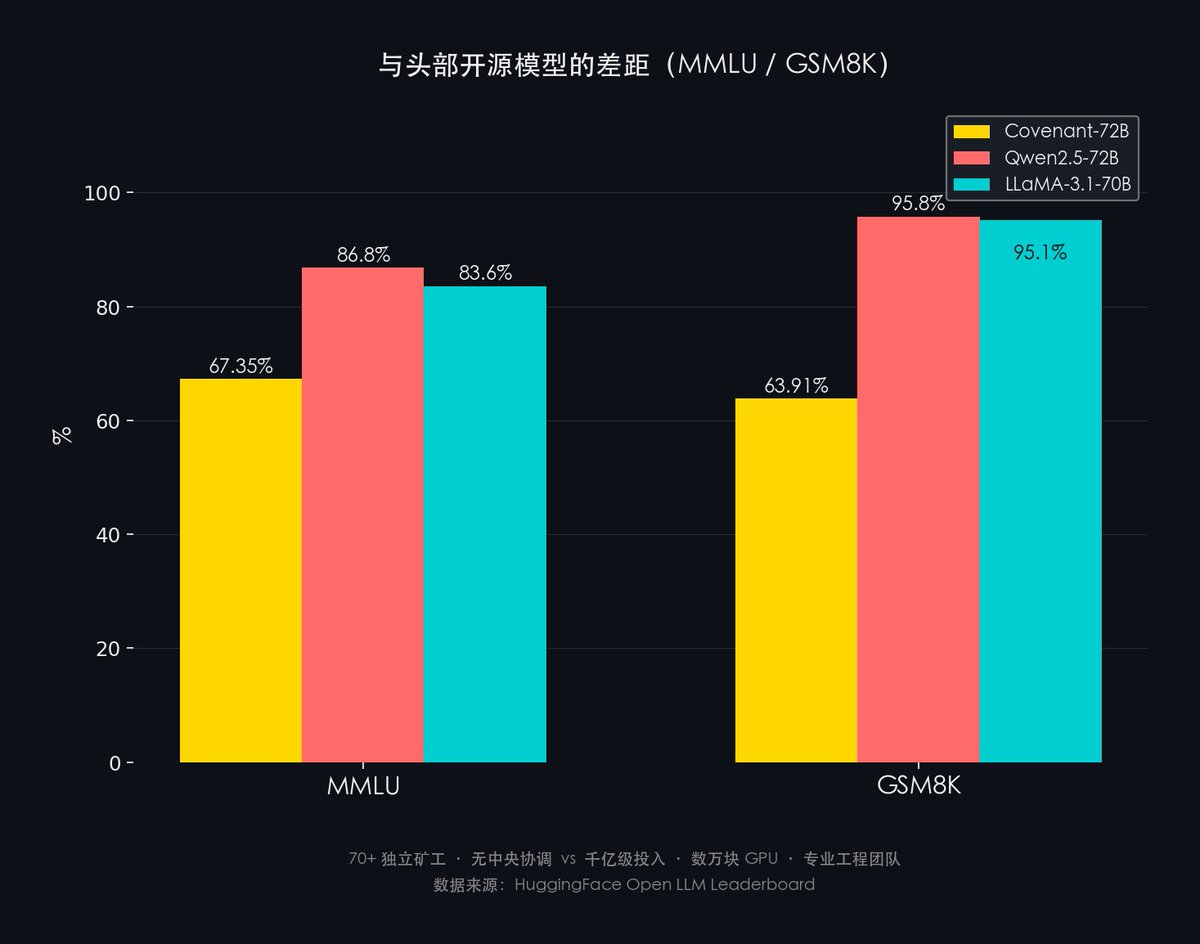
- MMLU: Covenant-72B 67.35% vs. Qwen2.5-72B 86.8% vs. LLaMA-3.1-70B 83.6%
- GSM8K: Covenant-72B 63.91% vs. Qwen2.5-72B 95.8% vs. LLaMA-3.1-70B 95.1%
The gap stands at roughly 20–30 percentage points.
Yet framing matters: Covenant-72B’s significance lies not in beating SOTA, but in proving decentralized training works. Qwen2.5 and LLaMA-3.1 rely on billion-dollar investments, tens of thousands of GPUs, and elite engineering teams—while Covenant-72B was built by 70+ independent miners, with zero central coordination.
Trends Matter More Than Snapshots:
- 2022: Best decentralized model was 6B—MMLU wasn’t even measured separately.
- 2026: 72B model, MMLU 67.35%, surpassing Meta’s same-scale model.
In four years, decentralized training evolved from “conceptual experiment” to “performance competitive with centralized training.” The slope of this curve matters far more than any individual benchmark score.
Moreover, Covenant-72B’s shortcomings in deep reasoning already have planned solutions—SN81 Grail will handle post-training reinforcement learning (RLHF), aligning the model and boosting capabilities. This mirrors the most critical upgrade step from GPT-3 to GPT-4.
Heterogeneous SparseLoCo Is the Next Milestone: Currently, SN3 requires miners to use identical GPU models. The next major breakthrough is Heterogeneous SparseLoCo, enabling mixed hardware (B200 + A100 + consumer GPUs) to jointly train the same model. Once implemented, the available compute pool for the next training cycle will expand dramatically.
Decentralized training has cleared the feasibility threshold. The current benchmark gaps are engineering challenges requiring further optimization—not fundamental theoretical barriers.
Part II: The Market Still Doesn’t Understand This
$TAO Price Timeline
The $TAO price action following the SN3 announcement perfectly illustrates this cognitive lag:
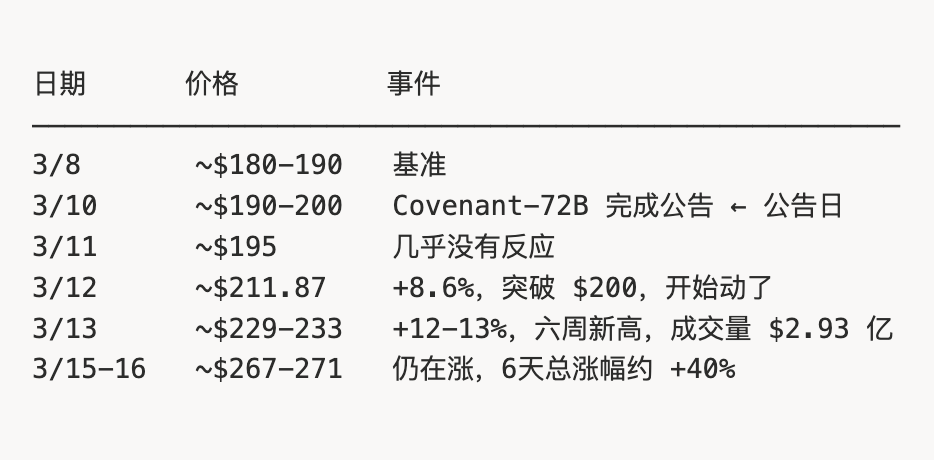
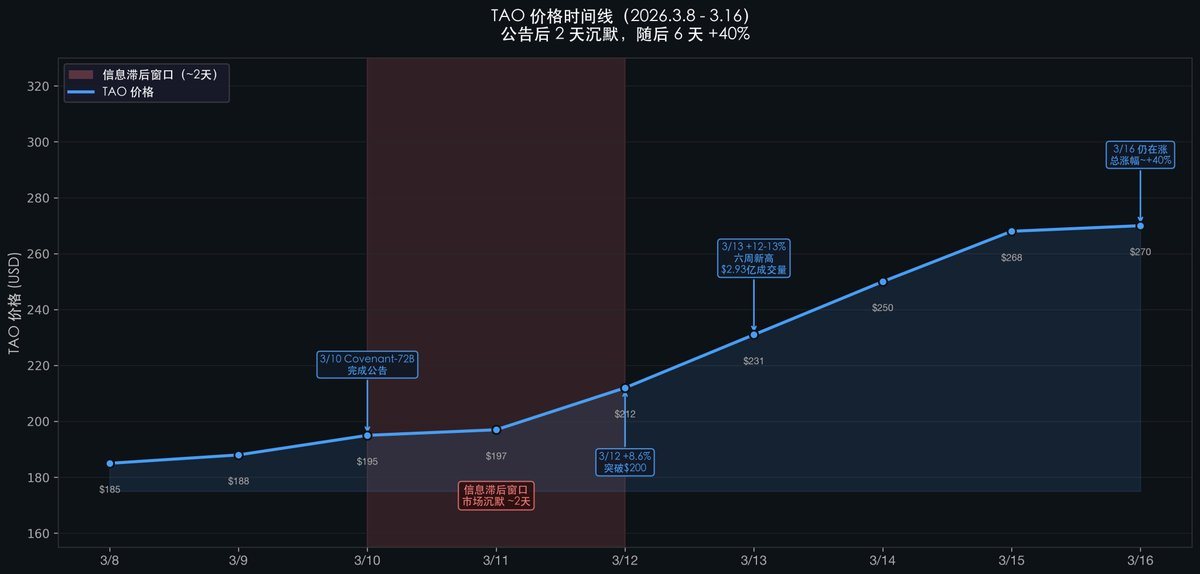
Note the two-day silence (March 10 → March 12): Announcement issued—price barely moved.
Why the Lag?
Crypto investors saw “Bittensor SN3 completed an AI model”—but many didn’t grasp the technical significance of “72B decentralized training outperforming Meta on MMLU.”
AI researchers understood that significance—but don’t follow crypto.
This cognitive gap between two communities created a ~2–3 day price-lag window.
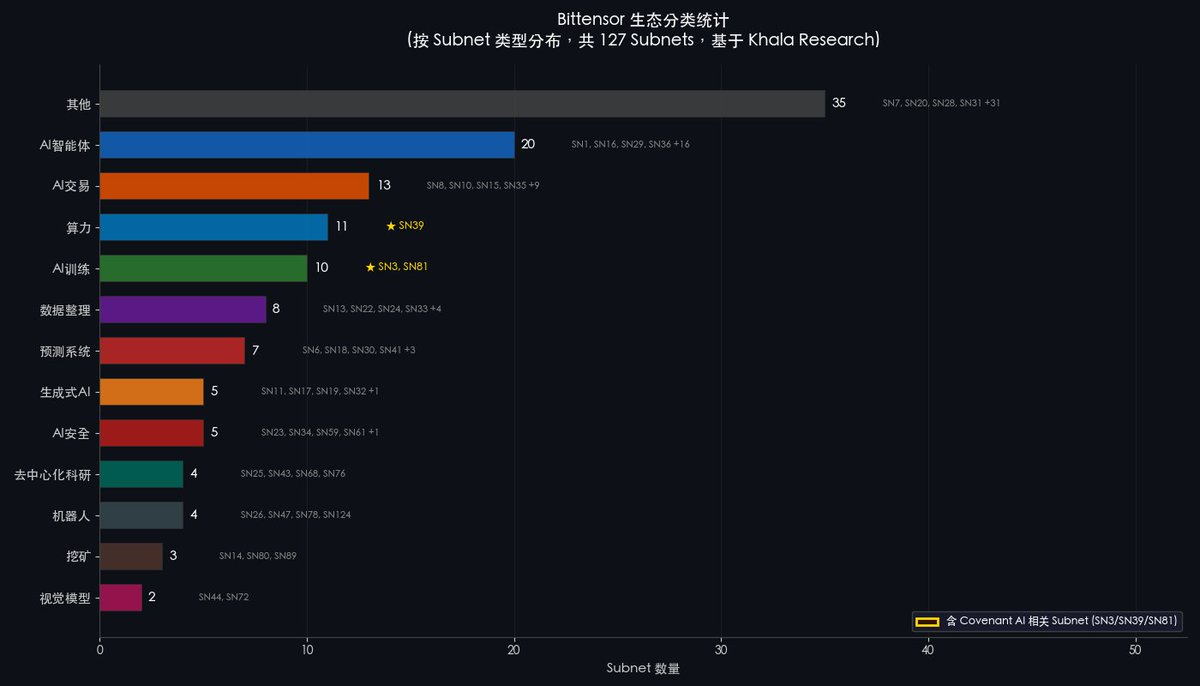
Moreover, most crypto investors still view Bittensor through the lens of the prior cycle. Today, Bittensor hosts over 79 active subnets spanning AI agents, compute markets, AI training, AI trading, robotics, and more. As the market re-prices Bittensor’s ecosystem breadth, this misalignment will correct—and such corrections typically manifest as sharp price surges.
Bittensor’s Valuation Misalignment
Place Bittensor in broader industry context:
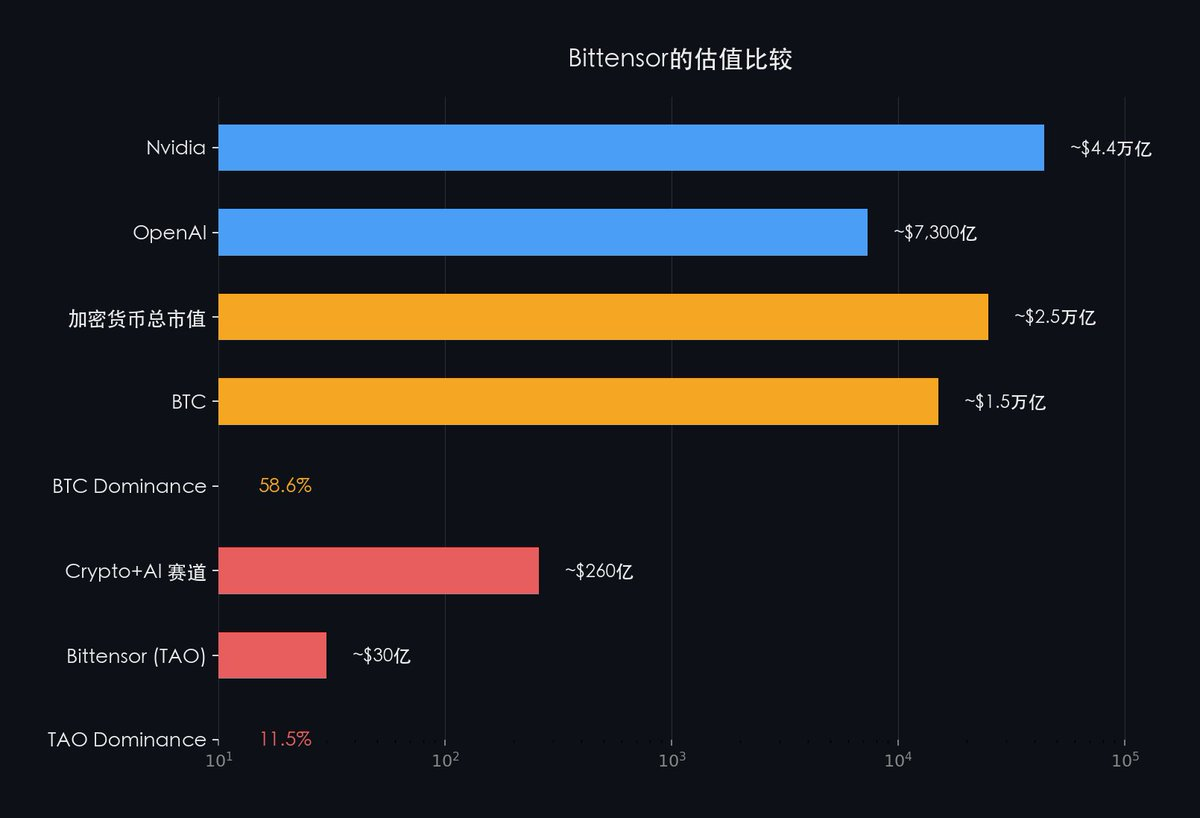
SN3 has proven: Bittensor can execute decentralized large-model training.
If future AI demands an open, permissionless training network, Bittensor is currently the *only* candidate infrastructure with real-world validation.
The market is pricing Bittensor using application-layer valuation logic—despite it being an AI infrastructure-grade network.
Even within crypto alone: Bitcoin consistently commands 50–60% market share across the entire crypto ecosystem, whereas Bittensor accounts for only ~11.5% of the crypto-AI sector.
As the market recalibrates its understanding of Bittensor’s role in AI infrastructure, this mispricing will inevitably correct.
Conclusion: Bittensor Is Crypto’s Last, Best Hope
If SN3 Templar’s Covenant-72B proves one thing, it’s this:
Decentralized networks can coordinate not only capital—but also compute and cutting-edge AI R&D.
For years, crypto played mostly a peripheral role in AI narratives. Countless projects leaned on concept packaging, emotional hype, or capital-driven storytelling—yet delivered little verifiable technical output. SN3 stands apart.
It introduced no new token narrative. It launched no “AI + Web3” application-layer product. Instead, it accomplished something deeper and harder:
Training a 72B-scale large model—without centralized coordination.
Participants spanned the globe, trusting no one else; the system coordinated contributions and reward distribution automatically via on-chain incentives and verification.
Crypto mechanisms organized real productivity in AI—for the first time.
Many still haven’t grasped SN3’s historical significance—just as many failed to recognize, at the time, that Bitcoin proved not “better payments,” but trustless, consensus-based value coordination.
Today, many still see only benchmarks, model releases, or a price surge.
But the real shift is this: Bittensor is proving that
- Crypto isn’t just about issuing assets—it’s about organizing production
- Crypto isn’t just about trading attention—it’s about producing intelligence
Open-source communities contribute code; academia contributes papers. But when problems escalate to ultra-large-scale training, long-term collaboration, cross-regional orchestration, anti-cheating, and fair reward allocation—goodwill and reputation systems fall short:
- No economic incentive → no stable supply
- No verifiable rewards/punishments → no long-term collaboration
- No tokenized coordination mechanism → no truly global, permissionless AI production network
So—is Bittensor underestimated? The answer isn’t “possibly.” It’s “profoundly and systematically underestimated.”
In the grand debate over “Does crypto still matter?”, Bittensor is delivering the industry’s strongest, most concrete answer.
And for that reason alone: Bittensor is crypto’s last, best hope.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News