

Can Vana, soon to launch its mainnet, become the infrastructure for the AI Agent data era?
TechFlow Selected TechFlow Selected
Can Vana, soon to launch its mainnet, become the infrastructure for the AI Agent data era?
Your own influence is actually greater than you imagine.
Author: TechFlow
As BTC breaks through $100,000, more capital is searching for new projects and opportunities amid bullish expectations.
But if you were to ask which sector currently holds the most potential, AI Agents must be on that list. However, with a large number of AI Agents launching every day, the narrative around this space is gradually stratifying:
One category focuses on applications built around AI Agents, where corresponding tokens represent either memes or utility for that Agent; the other concentrates on infrastructure providing capabilities to empower these AI Agents, enabling better applications.
The former, being more visible at the application layer, has started to become crowded and competitive; the latter, by contrast, offers relatively greater room for breakthroughs.
What capabilities do AI Agents still urgently need?
Perhaps we can find answers from the recently popular "AI KOL," aixbt:
Research shows that what aixbt says isn't always correct—it cannot distinguish truth from falsehood, lacks expert validation for its hypotheses, and cannot question itself.
At its core, aixbt is essentially a large language model that only scrapes and summarizes publicly available data, making it more like a repeater aggregating public information.

Therefore, if you could provide such AI agents with more diverse, personalized, and private data, they might perform significantly better.
For example, sharing your insights on trading low-market-cap altcoins or investment strategies discussed only in paid groups—these kinds of valuable data aren’t publicly accessible, so aixbt and similar agents simply can't access them.
Crucially, the world doesn’t lack sufficient data—high-quality data is just hard to obtain.
In the current crypto-driven AI agent boom, data infrastructure remains missing.
Here lies a narrative gap and informational asymmetry: if a project can collect more private and personalized data and feed it to AI agents or organizations in need, it may carve out a unique ecological niche during this trend.
Two months ago, we wrote about a project called Vana, which uses a DAO model to gather various types of data not available on public markets, while leveraging tokenization to incentivize data contributions and guide purchasing and usage of such data.
Back then, AI Agents weren’t yet this hot, so the project’s use cases seemed less clear. But now, amid this wave of AI Agent enthusiasm, Vana clearly has far greater applicability and a more coherent environment.
Just as Vana is preparing to launch its mainnet and release its native token $VANA, it has also updated its whitepaper and tokenomics, offering deeper explanations regarding current data challenges and its positioning.
In the crypto market, timing matters. What new developments and changes should we pay attention to in Vana today? Does the token hold stronger upside potential?
We’ve read the newly released whitepaper—we’ll help you quickly understand what Vana is all about now.

Data “Double-Spending”: The Blind Spot When Seeking Returns
Undoubtedly, everyone is chasing returns from the AI Agent craze.
Anyone can easily create an AI Agent, and assets tied to AI Agents can be readily tokenized... But beyond buying tokens linked to an AI Agent, what else can you earn?
This question represents new opportunities for individuals—and new narrative space for projects.
Don’t forget: AI Agents may already be using data you contributed, yet you haven’t earned a single cent from it. For instance, aixbt mentioned earlier analyzes trending crypto topics—some of which might originate from an article you wrote on your own Twitter account.
Hence, opening Vana’s new whitepaper, one concept caught our attention immediately in the first few pages: the “double-spending” dilemma of data.

Does “double-spending” sound familiar yet strange?
This term originates from Bitcoin's solution to the double-spending problem—preventing the same bitcoin from being spent twice.
Bitcoin solved this by recording transaction histories on a public blockchain—a tamper-proof ledger where everyone knows the full history of each coin, ensuring it can only be spent once.
However, in the realm of data, the issue becomes far more complex.
Unlike Bitcoin, data is inherently replicable, creating an overlooked economic challenge in the AI boom: when data is directly sold, buyers can easily copy and redistribute it, causing the same data to be used multiple times without generating additional income for the original contributor.
For example, once your tweet is used and learned by an AI Agent, it could be shared limitlessly with other AI Agents, ultimately eroding the data’s scarcity and economic value.
Could you solve this double-spending issue by creating a Bitcoin-like ledger, logging data usage on-chain?
First, data often contains privacy elements, making public logging inappropriate—and you may not want to share it. Second, even if usage is recorded on-chain, nothing stops the data from being copied and resold off-chain. Third, everyone wants to benefit from your data for free—who would willingly join your “self-serving but not mutually beneficial” ledger system?
So, is there any way to solve data’s “double-spending problem”?
As stated in Vana’s whitepaper: "Data sovereignty and collective data creation are not mutually exclusive."
We skimmed through the document. A TL;DR version would be:
The Vana protocol proposes an innovative solution by cleverly combining privacy protection, programmable access rights, and economic incentives into a completely new data economy model.
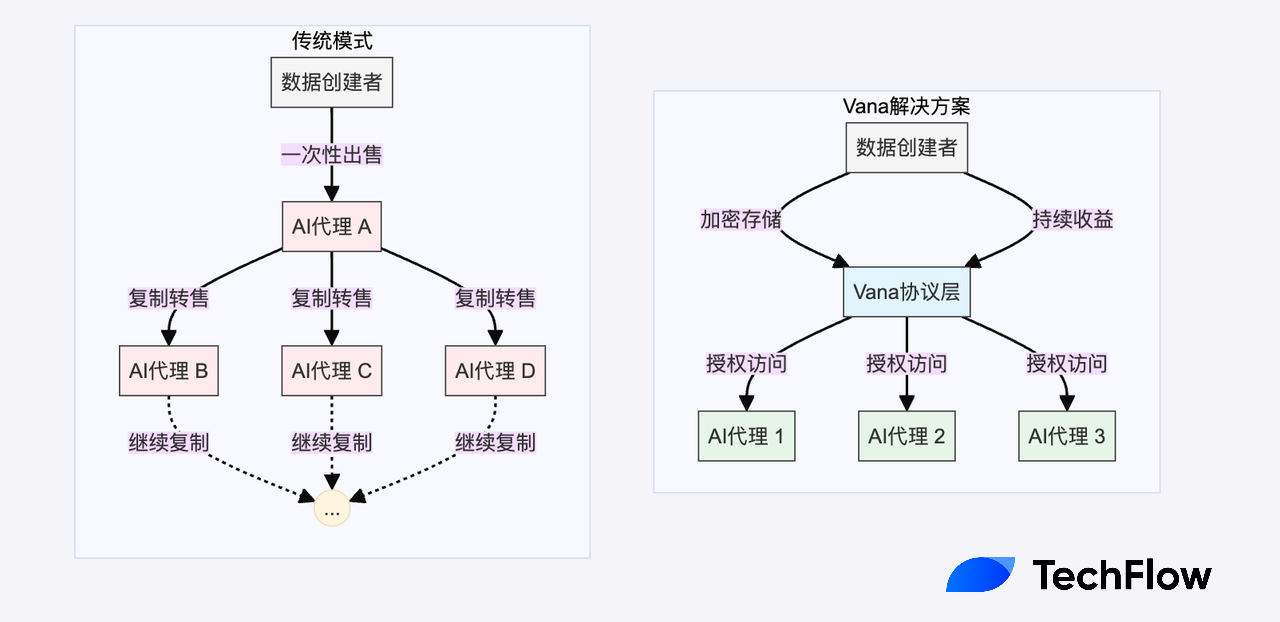
In this model, data remains encrypted at all times, and only authorized entities can access it under specific conditions. Through smart contracts, data owners can precisely control who accesses their data and under what conditions. More importantly, these access rights can themselves be tokenized and traded, while the underlying raw data stays protected.
A simpler analogy is the modern music industry’s streaming model:
Instead of selling music files outright (which leads to infinite copying), services like Spotify generate revenue every time a song is played.
Data owners don’t sell their data once and for all—they retain control and earn continuously from each use. This ensures data can be fully utilized (e.g., for AI training) while solving the problem of devaluation caused by one-time sales and unauthorized reuse. Meanwhile, data owners maintain complete control over their data.
Using DAOs as Pools: Building a “Data Cooperative”
Specifically, how does Vana work?
We can broadly divide participants in the AI market into two groups: companies/AI agents needing data; and individuals or organizations (actively or passively) contributing data.
To build higher-quality AI agents, the needs beyond public data are clear:
-
Access to private data (e.g., health records for medical diagnosis AI)
-
Access to paywalled data (e.g., premium articles and insights for business analysis AI)
-
Access to closed platform data (e.g., more user posts from X for sentiment analysis AI)
On the other side, those contributing data—intentionally or unintentionally—have several key demands:
-
You can access it, but ownership remains mine;
-
You can access it, but it must be stored securely;
-
You can access it, but I should benefit—payment per use.
Traditional data usage models often leave users in a passive position. For example, when AI companies need training data, they either buy it directly from social platforms (with no benefit to users), or negotiate individually with tens of thousands of users (extremely inefficient).
Vana’s solution is called a Data Liquidity Pool (DLP). You can think of it more simply as a “data cooperative”:
Users pool their data access rights together, forming a virtual organization similar to a cooperative—giving the group collective bargaining power while maintaining encrypted control over the original data.
Imagine a DLP formed by 100,000 Twitter users: when an AI company wants to use this data, they negotiate directly with the DLP, and revenues are automatically and fairly distributed among all contributors.
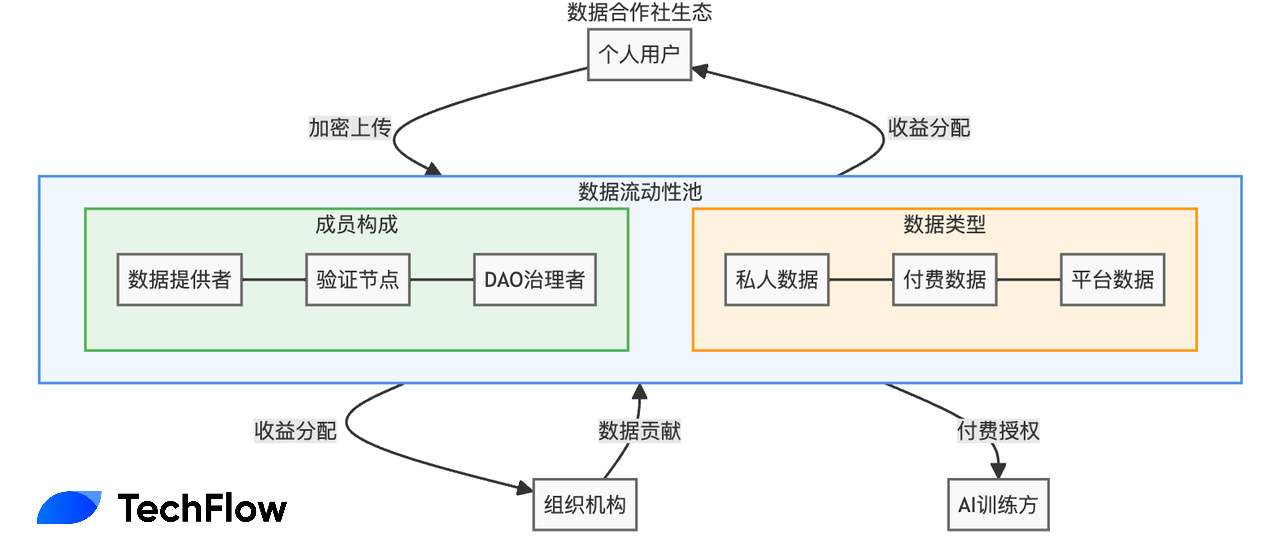
Based on Vana’s recently published whitepaper content, this “data cooperative” (DLP) has taken shape with four key rules:
-
Data Standards: Membership Guidelines
Similar to strict membership criteria, defining metadata standards—for example, social media data, health data, etc.—ensuring only high-quality data enters the pool.
-
Validation Mechanism: Quality Control for the Cooperative
Evaluating the quality and value of incoming data to ensure authenticity—essentially functioning as validator nodes in traditional blockchain terms.
-
Token Economics: Rewarding Contributor Behavior
Through a fair points system, high-quality data contributors are incentivized—the better and more data provided, the more token rewards earned.
-
Governance Rules: Cooperative Charter
Defining decision-making processes (e.g., launching a new data pool) and dispute resolution mechanisms—this is where familiar DAO characteristics shine through.
Overall, within the context of the crypto world, this data cooperative functions much like a DAO focused on data governance and incentives. The DAO manages the data pool and sets negotiation rules and profit distribution methods with data users.
If the above sounds too simplified, in Vana’s network design, this DAO model operates via rigorous technical implementation:
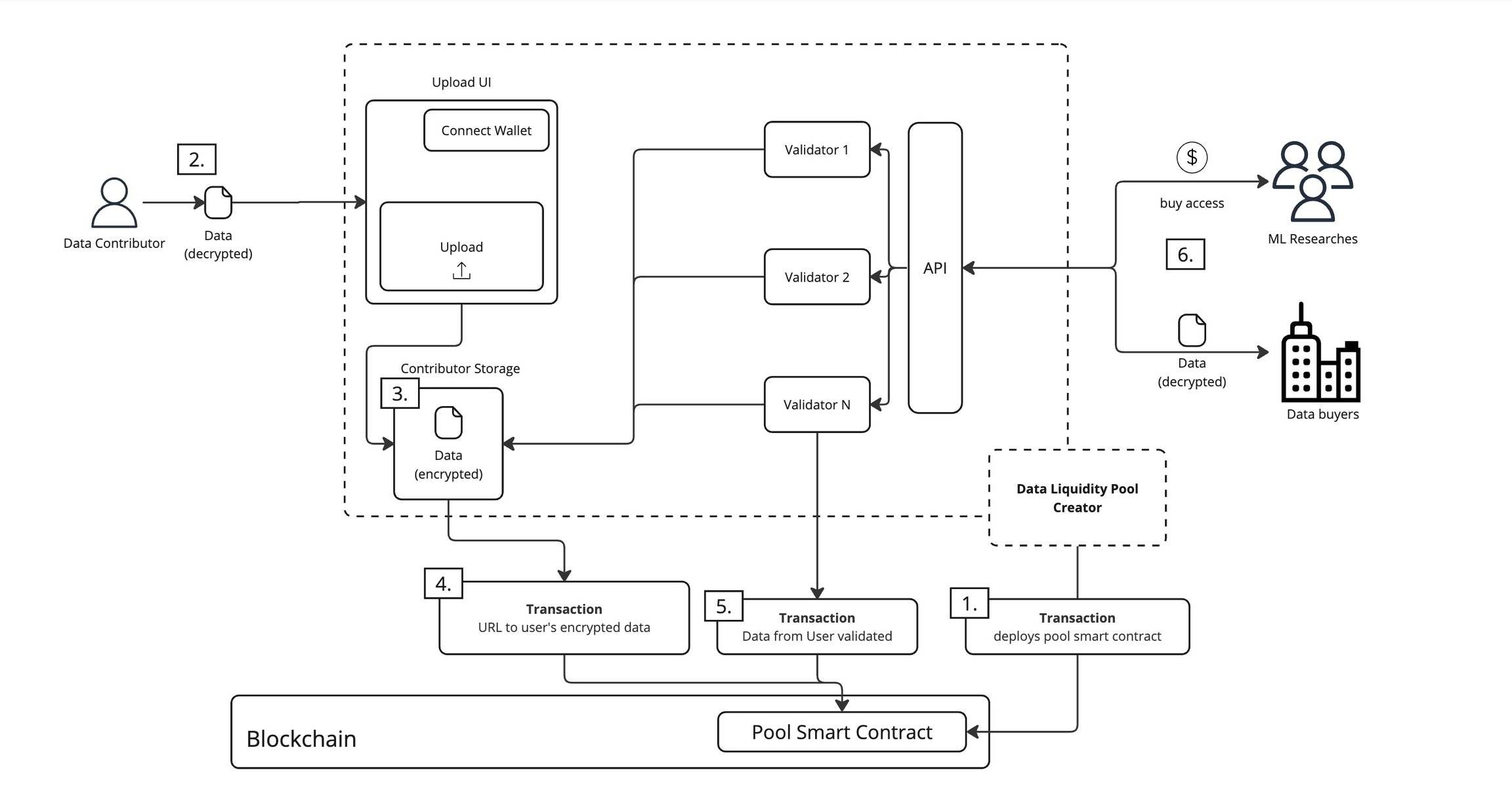
-
Smart Contract Deployment. The DAO creator deploys the pool’s smart contract onto the blockchain, clearly outlining rules for data management, usage, and revenue distribution.
-
Data Preparation. Data providers prepare the data they wish to contribute, encrypting it before submission.
-
Secure Storage. Providers connect their wallets to verify identity before uploading encrypted data, which is then stored in a dedicated storage space assigned to each contributor.
-
On-Chain Record. The system records the access address of the encrypted data on-chain, ensuring only authorized parties can retrieve it.
-
Multifactor Validation. Multiple validators audit the data for authenticity, quality, and value. These validation results are recorded in the smart contract to ensure credibility.
-
Controlled Usage. Verified data can be accessed by two types of users: machine learning researchers who pay to train models, and data buyers who access under specific conditions. All usage incurs fees and strictly adheres to conditions defined in the smart contract.
Due to length and technical complexity, we won’t dive deeply into privacy protections here.
If concerned about data leaks, just remember this core principle: all personal data in Vana remains encrypted—like being placed in a safe where only the user holds the key. Even when processing is required, it occurs only within secure environments (TEE), akin to a bank’s secure clearing room, with all operations strictly monitored and logged.
Notably, the system combines smart contracts and encryption to enable flexible yet secure access control. It determines exactly who can access what data and when, with all access logs securely preserved for auditing.
By using DAOs as data pools, this cooperative model protects individual data sovereignty and earnings, while allowing AI agents needing personalized data to make full use of it.
Blooming Diversity: Specialized Data DAOs for Specific Purposes
Currently, these Data Liquidity Pools on Vana are not just theoretical—they have evolved into real, sizable Data DAOs. Each DAO focuses on a vertical use case, serving different AI needs.
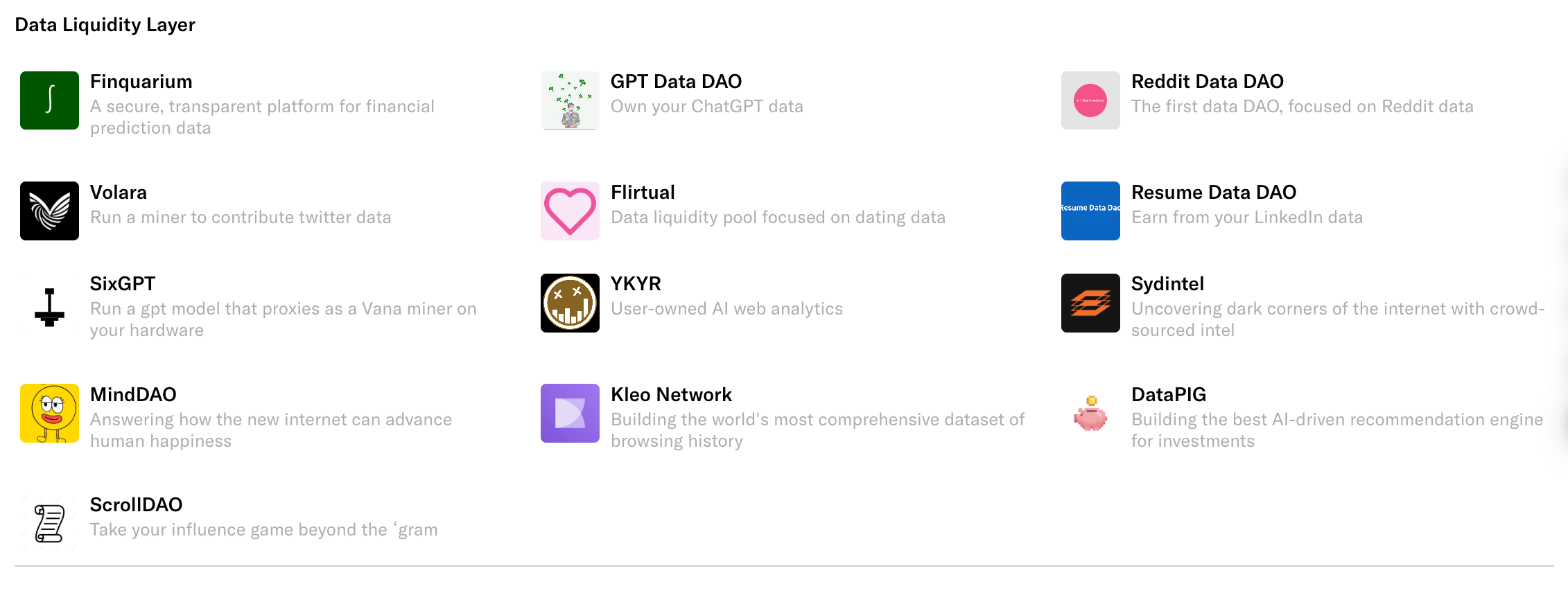
Take Volara DAO, focused on X (Twitter): you can link your Twitter account to the platform, upload your tweets and related social data, and receive corresponding rewards in the DAO’s native token, such as $VOL.
Note: Rewards are not given in VANA directly, but in the DAO’s own token, e.g., $VOL.
This resembles the current popularity of Virtuals, where beneath a parent token, various sub-tokens are created by different projects. Holding $VOL qualifies you for $VANA airdrops, and this nested asset structure opens up many strategic possibilities.
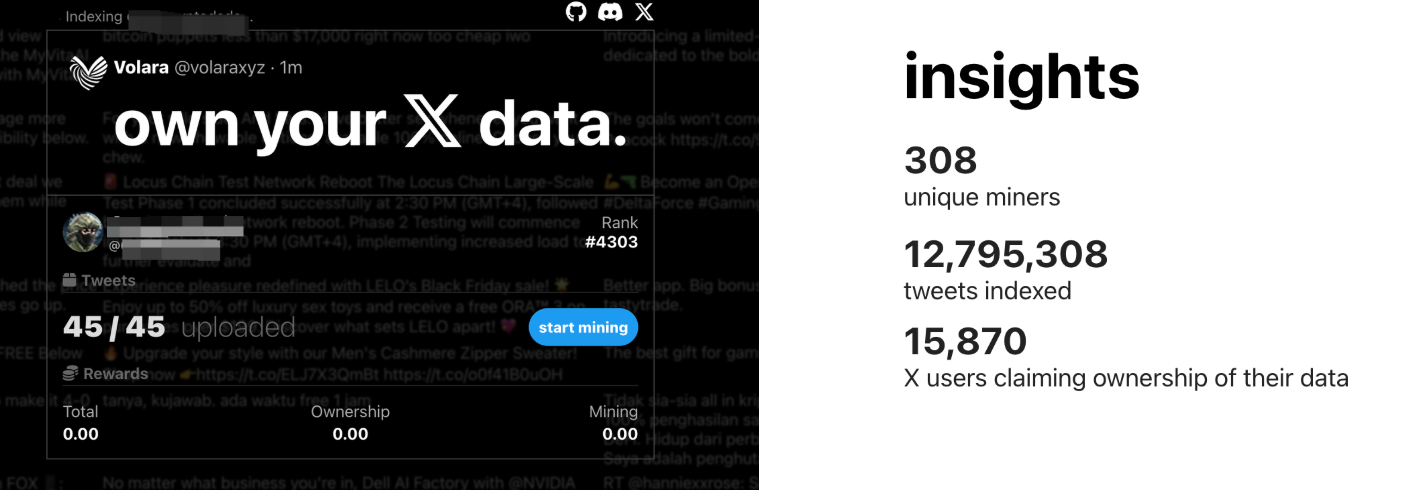
We’ve compiled a list of the 16 most popular Data DAOs on Vana and categorized them in detail.
For regular users, this is akin to “data mining”—if you believe in a particular DAO, follow its rules to contribute data and earn rewards and airdrops.
However, you may not possess all types of data, so refer to the following categories to identify which data you can contribute and optimize your earning strategy:
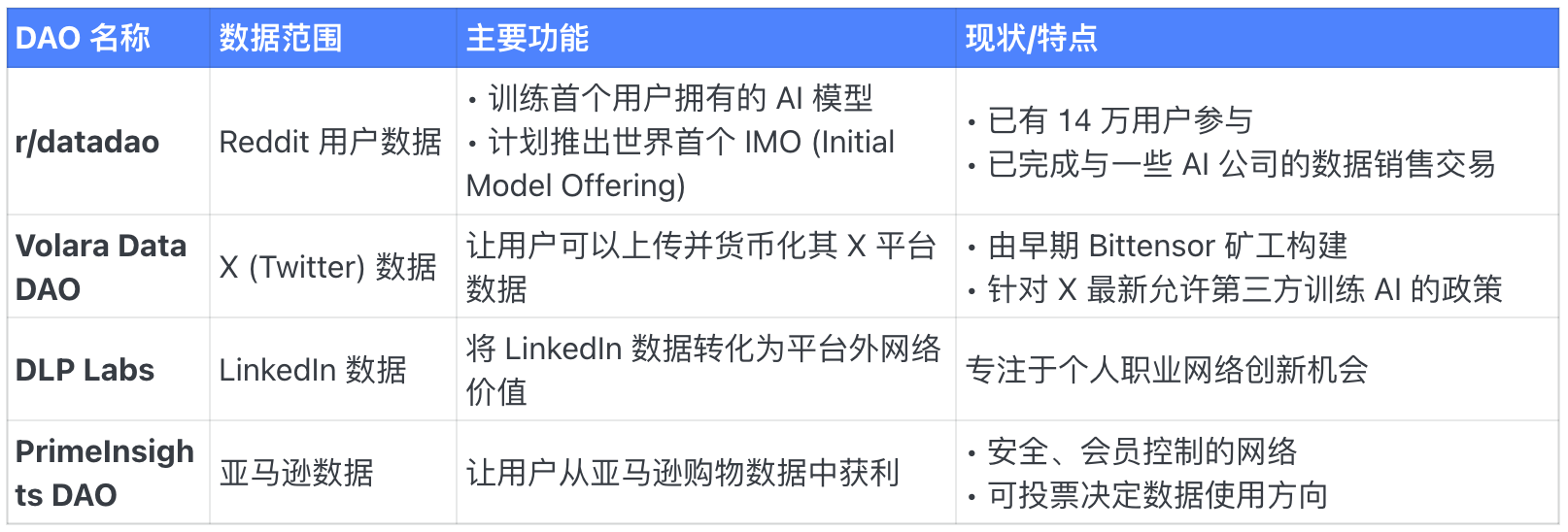
Platform-Based Data DAOs
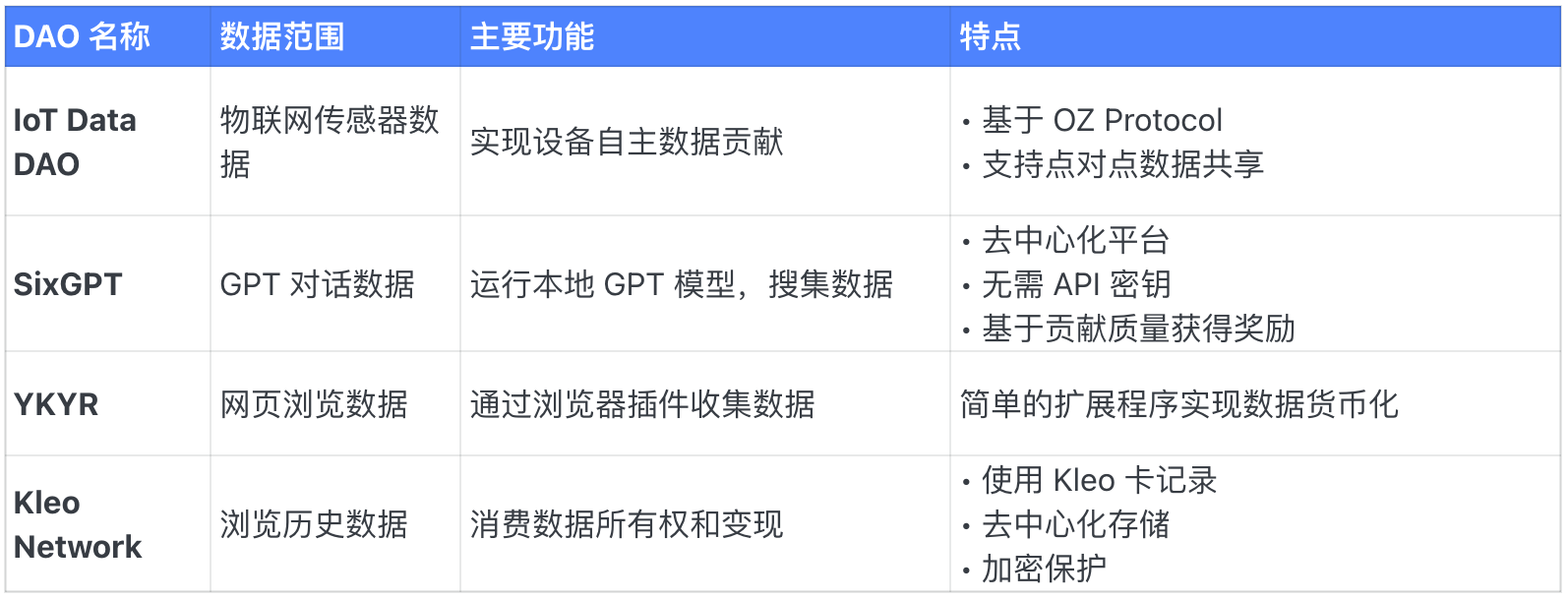
Device & Data Generation DAOs
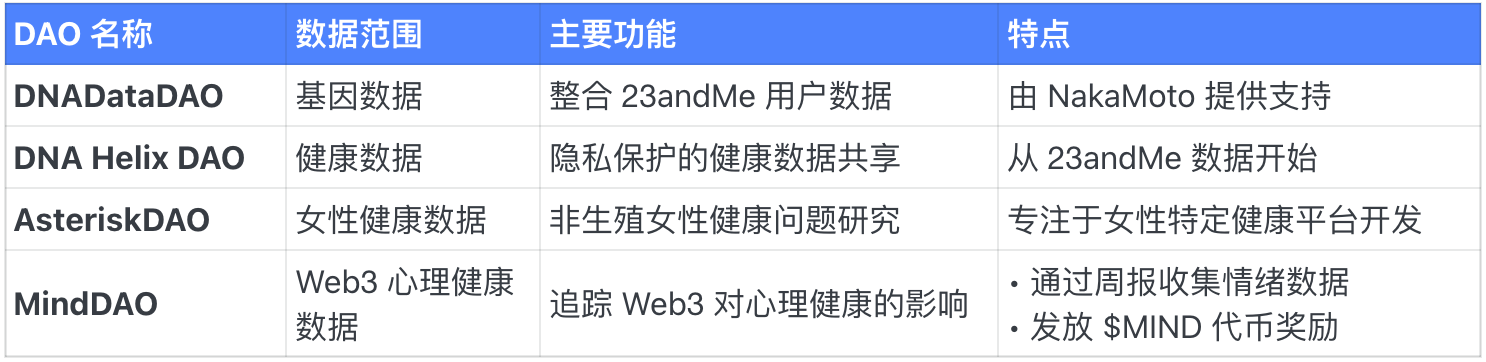
Human Insight & Financial DAOs

Health-Focused DAOs
Overall, since the developer testnet launched in June 2024, the Vana network has attracted 1.3 million users, over 300 Data DAOs, and reached 1.7 million daily transactions.
With the mainnet launch and token rollout coming, bolstered by economic incentives, we may see even more Data DAOs emerge.
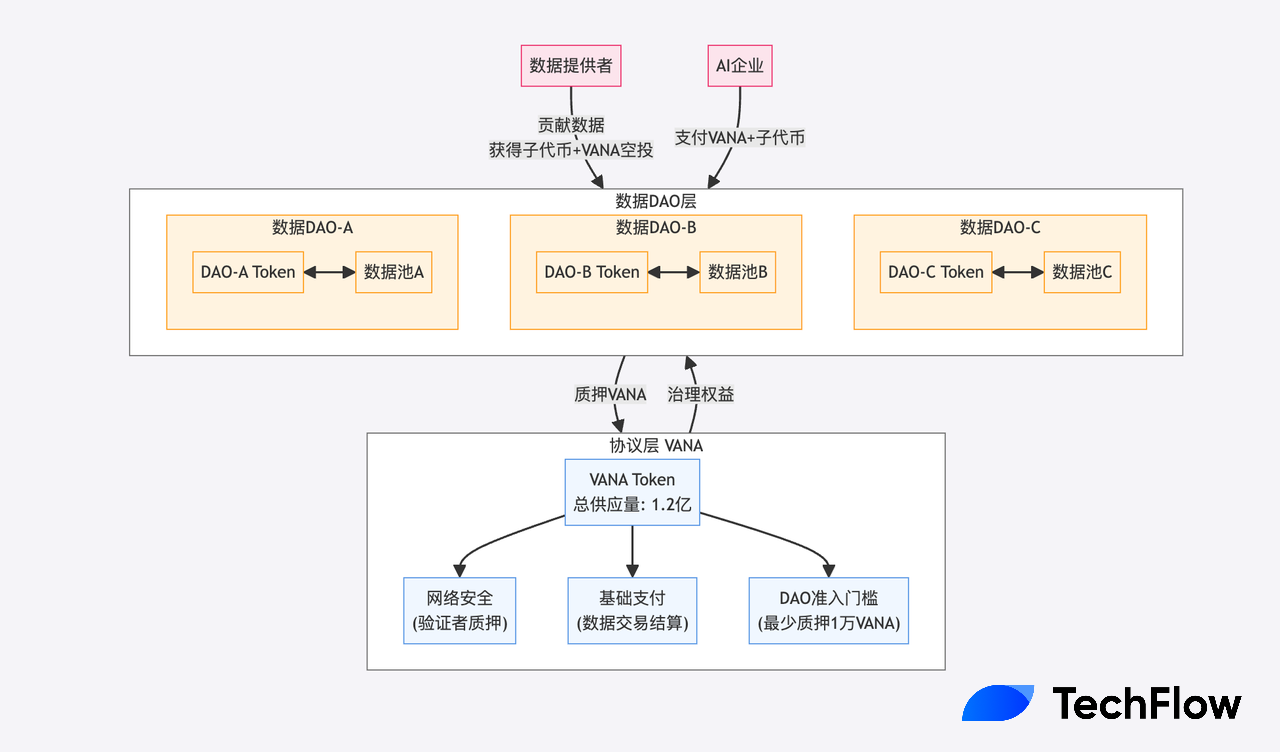
Two-Tier Token Economy: A Smarter Way to Play
You may have noticed that each of the above DAOs has its own sub-token, linked to the parent token VANA (e.g., through airdrops).
This leads to a carefully designed two-tier token economy model.
Imagine a traditional data marketplace: medical, financial, and social data vary greatly in value and use cases. Using a single token to measure and incentivize such diverse contributions is like using one ruler to measure everything—from planets to atoms. Clearly, it’s neither precise nor flexible.
VANA adopts a more elegant solution: establishing a unified base token (VANA) at the protocol level, while allowing each Data DAO to issue its own dedicated token.
Each tier has distinct roles:
-
VANA:
Total supply: 120 million. First, it secures network safety by requiring validators to stake VANA;
Second, it serves as the universal payment currency—for example, AI firms needing data from a DAO must pay in VANA;
Most importantly, each Data DAO must stake at least 10,000 VANA to operate—an “earnest deposit” ensuring long-term commitment to the ecosystem.
-
Tokens of Data DAOs:
Each Data DAO can design a token economy tailored to its domain. For instance, a medical data DAO may prioritize data completeness and accuracy, designing special rewards for high-quality medical records; a social data DAO may focus more on user engagement and influence.
These exclusive tokens are more than simple points—they form a complete value capture system. When data is used, both VANA and the DAO’s token must be paid—similar to paying both a “venue fee” (VANA) and a “special service fee” (DAO token).
Does this remind you of Virtuals?
The brilliance of this two-tier system lies in creating a self-sustaining economic cycle: data usage burns tokens, creating deflationary pressure; high-quality contributions earn new tokens, introducing moderate inflation. This balance maintains token value stability and encourages continuous data contribution.
As the parent token, VANA provides gas and staking functionality. Each sub-DAO issues its own token, pairs them with VANA, and the parent token captures value from overall ecosystem growth.
From the perspective of asset creation and efficiency, VANA’s approach clearly aligns with the current AI Agent trend.
For individuals, this system turns data into a truly sustainable asset. Data providers no longer sell data once and for all—they instead hold tokens and continuously share in usage-generated revenue. It’s a shift from “one-time sale” to “royalty-based sharing,” dramatically improving creators’ incentives.
With Vana’s mainnet launch approaching (tokenomics already published, mainnet hype building), after understanding this dual-token mechanism, there are at least two things you can do now:
First, contribute data across different Data DAOs to earn sub-DAO tokens and qualify for $VANA airdrops; here’s the aggregated link.
Second, as the mainnet launches, we’ve noticed Vana’s official site has been updated, adding a new datahub page to manage your participation in various Data DAOs and associated tokens.
Currently, there’s a pre-registration campaign on this page to link your identity early and prepare for rewards—players interested are advised to get ahead.
Completing registration earns you the status of “Early Explorer.”

Conclusion
In today’s AI Agent frenzy, AI Agents are growing in influence, eventually flooding your information feeds and investment lists.
Yet Vana’s narrative suggests something powerful: Your own influence is actually greater than you think.
By contributing various forms of data, you become part of the AI boom; by tokenizing data assets, you gain new ways to participate in asset creation.
It’s undeniable that in the crypto world, asset creation is a clear path forward. Those closer to assets gain more narrative space and profits.
And when your data can be tokenized, we believe this represents a hidden but aligned trajectory—one that empowers individuals to embrace, leverage, and actively participate in the AI agent revolution.
The narrative layer for data infrastructure remains underdeveloped. Whether Vana will be recognized for its value—only the market can decide.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News










