没有工作履历,DeepSeek是如何选人的?答案是,看潜力。
作者:Sam Gao,Author of ElizaOS
0. 写在前面
最近一段时间,接连出现的DeepSeek V3,R1让美国的AI研究员,创业者和投资人们开始Fomo。这一场盛宴,甚至可以和ChatGPT在2022年年底问世一样让人惊讶。

凭借DeepSeek R1的彻底开源(HuggingFace可免费下载模型进行本地推理)和极低的价格(是OpenAI o1的1/100的价格),DeepSeek在短短5天时间内,登上了美区Apple AppStore的冠军。
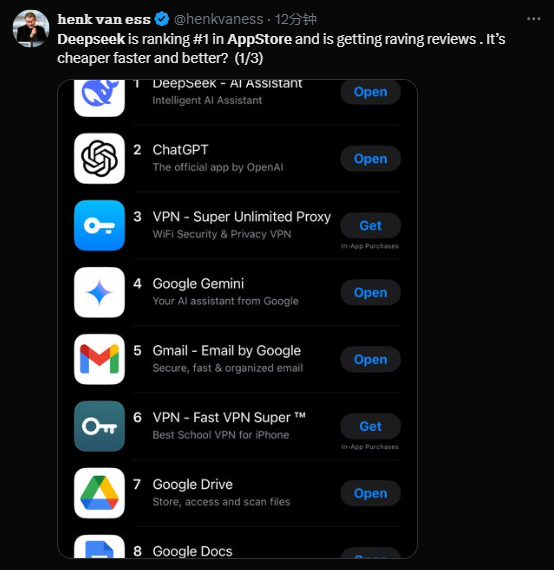
那么,这家神秘的,由一家中国量化公司所孵化出来的AI新势力,究竟源自何方?
1.DeepSeek的由来
我第一次听说DeepSeek,还是在2021年,当时,在达摩院工作时,隔壁组的天才少女,一年发表8篇ACL(自然语言处理顶会)的北大硕士罗福莉,离职加入了幻方量化(High-Flyer Quant)。当时大家都非常好奇,非常挣钱的量化公司,为何要招募AI领域的人才: 难道幻方也需要发paper么?
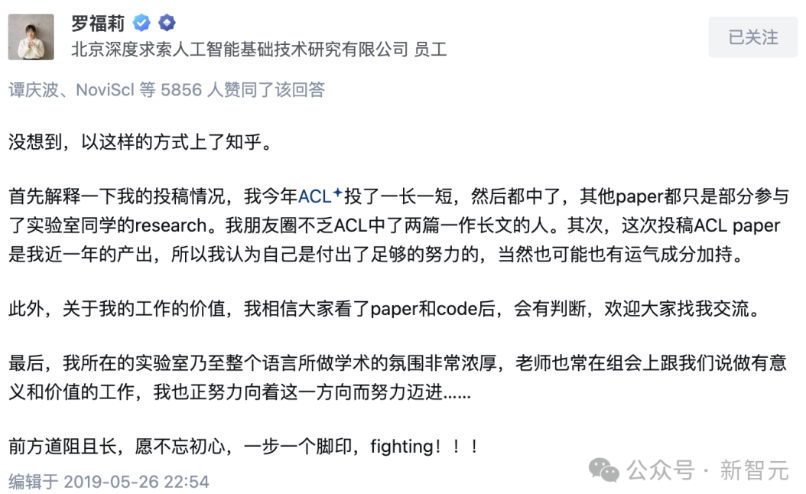
当时,据我所知,幻方招募的AI研究员大多是各自为战,找一些前沿的方向进行探索,其中最核心的方向当属大模型(LLM)以及文生图模型(当时的OpenAI Dall-e)相关。
时间转眼来到了2022年底,幻方逐渐开始吸纳越来越多的顶级AI人才(大部分是清华北大的在校生)。在ChatGPT的刺激下,让在AI领域积累多年的幻方CEO梁文锋下定决心要进军通用人工智能领域了:“我们建了一个新公司,从语言大模型开始,后边也会有视觉等。”
是的,这个公司就是DeepSeek,在2023年初,以智谱,月之暗面,百川智能等为代表的六小龙公司逐步走势舞台中央,在热闹繁华的中关村和五道口中间,DeepSeek的存在感很大程度上被这些热钱击中的公司夺走了"注意力"(Attention)。
因此,在2023年,作为一个纯研究机构,没有明星创始人的DeepSeek(如李开复的零一万物,杨植麟的月之暗面,王小川的百川智能等)很难独立从市场上融资。因此,幻方决定剥离DeepSeek,并全资资助DeepSeek的开发。在2023年这个烈火烹油的时代,没有风险投资公司愿意为DeepSeek提供资金,一是DeepSeek里面大多是刚毕业的PHD们,没有非常有知名度的顶级研究员坐镇,二是因为资本退出遥遥无期。
在充满噪音和浮躁的环境下,DeepSeek开始书写其在AI探索上的一个个故事:
-
2023 年 11 月,DeepSeek 推出了 DeepSeek LLM,其参数多达 670 亿个,其性能接近 GPT-4。
-
2024 年 5 月,DeepSeek-V2 正式上线。
-
2024 年 12 月,DeepSeek-V3 发布,基准测试表明,它的表现优于 Llama 3.1 和 Qwen 2.5,同时与 GPT-4o 和 Claude 3.5 Sonnet 相当,引爆了业内关注。
-
2025 年 1 月,第一代有推理能力的大模型模型DeepSeek-R1发布,以OpenAI o1 1/100不到的价格和卓越的性能,让全世界科技界为之战栗: 世界真正意识到,中国力量真的来了... 开源永远赢!
2.人才战略
我很早期的时候认识一些DeepSeek的研究员,主要是研究AIGC方向的,如2024年11月发布的Janus的作者以及DreamCraft3D的作者,其中还有一位帮助我优化过最新的论文 @xingchaoliu。

根据我的发现,我认识的研究员们大多是非常年轻,基本都是在读博士生或者毕业3年以内的。


其中,这些人大都是在北京地区读研究生或者博士的学生,在学术方面有着极强的造诣: 多为发表了3-5篇顶会论文的研究员。
我问过DeepSeek的朋友,为什么梁文峰只招募年轻人?
他们给我转了幻方CEO梁文峰的话,其原话如下:
DeepSeek团队的神秘面纱让人们好奇:它的秘密武器是什么?外媒说,这一秘密武器是“年轻天才”,他们足以与财力雄厚的美国巨头展开竞争。
在AI行业,聘请经验丰富的老将是常态,许多中国本土的AI初创公司更倾向于招聘资深研究人员或拥有海外博士学位的人才。然而,DeepSeek却反其道而行,偏爱没有工作履历的年轻人。
一名曾与DeepSeek合作的猎头透露,DeepSeek不招资深技术人员,“工作经验在3-5年已经是最多的了,工作超8年的基本就pass了。”梁文锋在2023年5月接受36氪采访时也表示,DeepSeek的大多数开发人员要么是应届毕业生,要么是刚开始从事人工智能职业的人。他强调:“我们的核心技术岗位大多由应届毕业生或具有一两年工作经验的人担任。”
没有工作履历,DeepSeek是如何选人的?答案是,看潜力。
梁文锋曾说,做一件长期的事,经验其实没那么重要,相比之下基础能力、创造性和热爱等更重要。他认为,或许目前世界排名前50的顶尖AI人才还不在中国,“但我们能自己打造这样的人。”
这个战略让我想起了OpenAI的早期策略,OpenAI在2015年底成立的时候,Sam Altman的核心思路就是找年轻有野心的研究员,因此,除了总裁Greg Brockman和首席科学家Ilya Sutskever以外,剩下四个核心创始技术团队成员(Andrew Karpathy,Durk Kingma,John Schulman,Wojciech Zaremba)都是应届的博士毕业生,分别毕业于斯坦福大学,荷兰阿姆斯特丹大学,加州伯克利分校以及纽约大学。

从左到右: Ilya Sutskever(前首席科学家),Greg Brockman(前总裁),Andrej Karpathy(前技术负责人),Durk Kingma(前研究员),John Schulman(前强化学习团队负责人)以及Wojciech Zaremba(现任技术负责人)
这种"幼狼战略",已经让OpenAI尝到了甜头,孵化出了如GPT之父Alec Radford(相当于民办三本毕业),文生图模型DALL-E之父Aditya Ramesh(NYU本科生),以及GPT-4o的多模态负责人,三届奥赛金牌得主Prafulla Dhariwal等。让成立初期,拯救世界计划并不明确的OpenAI,在年轻人的横冲直撞中,生生的撞开了一条生路,将OpenAI从DeepMind身边的无名小卒,成长为巨擘。
梁文峰正是看到了Sam Altman这个成功的战略,才坚定的选择了这条路,不过,不同于OpenAI等待了7年时间才见到了ChatGPT。梁文峰的投入,用了2年多就见到了成效,可谓是中国速度。
3.为DeepSeek发声
在DeepSeek R1的文章中,其各项指标惊人的优异。但也引发了大家的怀疑: 有两个疑点,
由于算力的限制和MoE的复杂性,这让只用500万美元就一次成功的DeepSeek R1看着有些可疑,但是,无论你对R1的态度是顶礼膜拜其“低成本奇迹”,还是质疑其“华而不实”,都无法忽视其功能性创新的炫目。
BitMEX联合创始人Arthur Hayes发文表示: DeepSeek崛起是否会导致全球投资者质疑美国超卓主义?美国的资产价值是否被严重高估?
斯坦福大学教授吴恩达在今年的达沃斯论坛公开表示: "我对 DeepSeek 的进展印象深刻。我认为他们能够以非常经济的方式训练模型。他们最新发布的推理模型,非常出色……‘加油’!"
A16z的创始人,Marc Andreessen表示,"Deepseek R1 是我见过的最令人惊叹、最令人印象深刻的突破之一——而且作为开源,它是给世界的一份深刻的礼物。"
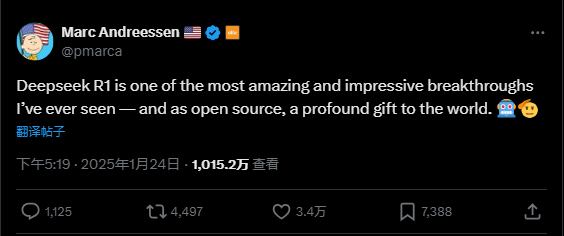
2023年站在舞台角落的DeepSeek,终于在2025年,农历春节前,站上了世界AI之巅.
4.Argo和DeepSeek
作为Argo的技术开发者和AIGC研究者,我将Argo里面的重要功能进行了DeepSeek化: 作为一个工作流(workflow)系统,粗糙的原始工作流生成工作,Argo是用DeepSeek R1进行的。此外,Argo将LLM内置为标准的DeepSeek R1,并选择抛弃闭源昂贵的OpenAI模型,原因是Workflow系统通常包含大量的Token消耗和上下文信息(平均>=10k token),这就导致了如果使用高价的OpenAI或Claude 3.5,Workflow的执行成本非常昂贵,在web3用户没有得到真正的价值捕获之前,这种提前透支的花销,是一种对产品的伤害。
随着DeepSeek越来越好,Argo会和DeepSeek为代表的中国力量进行更密切的合作: 包括不限于Text2Image/Video接口的中国化,LLM的中国化。
在合作方面,Argo将会在未来邀请DeepSeek的研究员分享技术成果,并为顶级AI研究员提供grants,为web3投资人和用户了解AI进展,提供助力。





 个人中心
个人中心 退出登录
退出登录 ONDO0.39 -5.49%
ONDO0.39 -5.49%
 TRUMP5.15 -2.24%
TRUMP5.15 -2.24%
 SUI1.43 -5.31%
SUI1.43 -5.31%
 TON1.48 -4.46%
TON1.48 -4.46%
 TRX0.28 -0.42%
TRX0.28 -0.42%
 DOGE0.13 -3.64%
DOGE0.13 -3.64%
 XRP1.88 -2.59%
XRP1.88 -2.59%
 SOL123.18 -3.75%
SOL123.18 -3.75%
 BNB844.16 -3.10%
BNB844.16 -3.10%
 ETH2825.66 -4.26%
ETH2825.66 -4.26%
 BTC86094.32 -1.76%
BTC86094.32 -1.76%




 首页
首页 深潮精选
深潮精选 Research
Research 项目发现
项目发现 7x24h︎快讯
7x24h︎快讯 最新活动
最新活动
 分享至微信
分享至微信
 添加收藏
添加收藏 分享社交媒体
分享社交媒体
 @samuel_ys92
@samuel_ys92 精选解读
精选解读

 River:S3 快照将于 12.19 进行,S4 将于 12.22 启动
River:S3 快照将于 12.19 进行,S4 将于 12.22 启动





 扫码关注公众号
扫码关注公众号





