我们正站在一场创新爆发的边缘。
作者:Teng Yan
编译:深潮TechFlow

早安!它终于来了。
我们整篇论文的内容相当丰富,为了让大家更容易理解(同时避免超过邮件服务商的大小限制),我决定将它分成几个部分,在接下来的一个月中逐步分享。现在,让我们开始吧!
我一直无法忘记的一个巨大错失。
这件事至今让我耿耿于怀,因为它是一个任何关注市场的人都能看出的明显机会,但我却错过了,没有投入一分钱。
不,这不是下一个 Solana 杀手,也不是一只戴搞笑帽子的狗的 memecoin。
它是……NVIDIA。
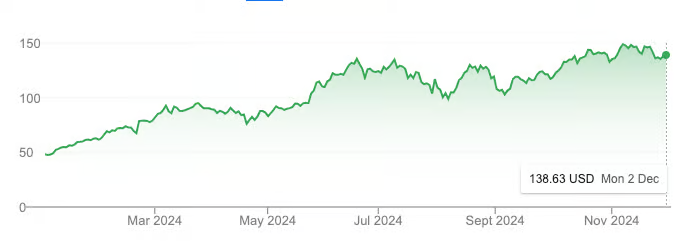
NVDA 年初至今的股价表现。来源:Google
仅在一年内,NVIDIA 的市值从 1 万亿美元飙升至 3 万亿美元,股价翻了三倍,甚至在同一时期的表现超过了比特币。
当然,其中有一部分是 AI 热潮的推动。但更重要的是,这种增长有着坚实的现实基础。NVIDIA 在 2024 财年的收入达到 600 亿美元,比 2023 年增长了 126%。这种惊人的增长背后,是全球大科技公司争相购买 GPU,以抢占通用人工智能(AGI)军备竞赛的先机。
为什么我会错过?
过去两年,我的注意力完全集中在加密货币领域,没有关注 AI 领域的动态。这是一个巨大的失误,至今让我懊悔。
但这次,我不会再犯同样的错误。
今天的 Crypto AI,给我一种似曾相识的感觉。
我们正站在一场创新爆发的边缘。它与 19 世纪中期的加州淘金热有着惊人的相似之处——行业和城市一夜之间崛起,基础设施迅速发展,而敢于冒险的人则赚得盆满钵满。
就像早期的 NVIDIA 一样,Crypto AI 在未来回顾时会显得如此显而易见。
Crypto AI:潜力无限的投资机会
在我论文的第一部分中,我解释了为什么 Crypto AI 是当今最令人兴奋的潜在机会,无论是对投资者还是开发者而言。以下是关键要点:
Crypto AI 的核心是将人工智能与加密基础设施结合。这使得它更有可能沿着 AI 的指数增长轨迹发展,而不是跟随更广泛的加密市场。因此,要保持领先,你需要关注 Arxiv 上的最新 AI 研究,并与那些相信自己正在构建下一个大事件的创始人交流。
Crypto AI 的四大核心领域
在我论文的第二部分中,我将重点分析 Crypto AI 中最有前景的四个子领域:
-
去中心化计算:模型训练、推理与 GPU 交易市场
-
数据网络
-
可验证 AI
-
在链上运行的 AI 智能体
这篇文章是几周深入研究以及与 Crypto AI 领域创始人和团队交流的成果。它并不是每个领域的详细分析,而是一个高层次的路线图,旨在激发你的好奇心、帮助你优化研究方向,并指导你的投资决策。
Crypto AI 的生态蓝图
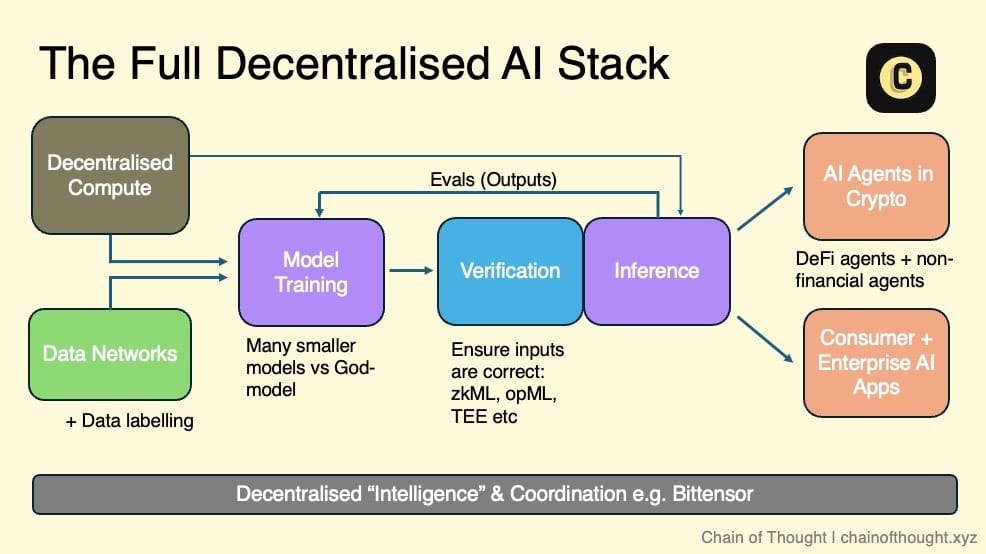
我将去中心化 AI 的生态系统想象为一个分层结构:从一端的去中心化计算和开放数据网络开始,这些为去中心化 AI 模型的训练提供基础。
所有推理(inference)的输入和输出都通过密码学、加密经济激励以及评估网络进行验证。这些经过验证的结果流向链上自主运行的 AI 智能体,以及用户可以信赖的消费级和企业级 AI 应用。
协调网络将整个生态系统连接起来,实现无缝的沟通与协作。
在这个愿景中,任何从事 AI 开发的团队都可以根据自身需求,接入生态中的一个或多个层级。无论是利用去中心化计算进行模型训练,还是通过评估网络确保高质量输出,这个生态系统提供了多样化的选择。
得益于区块链的可组合性,我相信我们正在迈向一个模块化的未来。每一层都将被高度专业化,协议将针对特定功能进行优化,而非采用一体化的解决方案。
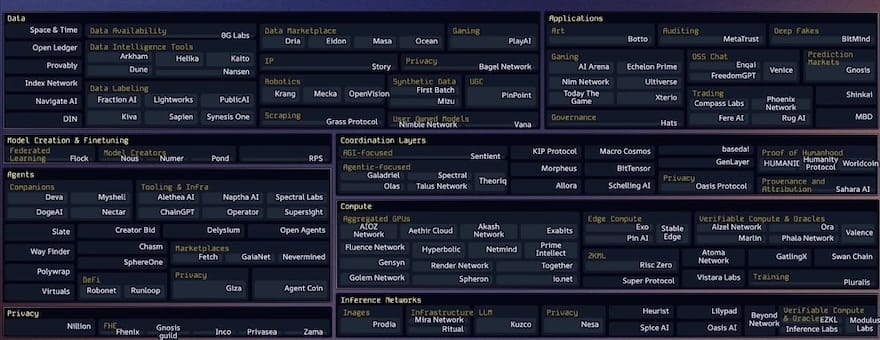
近年来,去中心化 AI 技术栈的每一层都涌现出了大量初创企业,呈现出“寒武纪式”的爆炸增长。其中大部分企业成立仅仅 1-3 年。这表明:我们依然处于这个行业的早期阶段。
在我见过的 Crypto AI 初创企业生态图中,最全面且最新的版本由 topology.vc 的 Casey 和她的团队维护。这是任何想要追踪这一领域发展的人不可或缺的一项资源。
当我深入研究 Crypto AI 的各个子领域时,我总是在思考:这里的机会到底有多大?我关注的不是小型市场,而是那些能够扩展到数千亿美元规模的巨大机会。
-
市场规模
评估市场规模时,我会问自己:这个子领域是创造了一个全新的市场,还是正在颠覆一个现有市场?
以去中心化计算为例,这是一个典型的颠覆性领域。我们可以通过现有的云计算市场来估算其潜力。当前,云计算市场的规模约为 6800 亿美元,预计到 2032 年将达到 2.5 万亿美元。
相比之下,像 AI 智能体这样的全新市场则更难量化。由于缺乏历史数据,我们只能通过对它解决问题能力的直觉判断和合理推测来进行估算。但需要警惕的是,有时候看似是一个全新市场的产品,实际上可能只是“为问题寻找解决方案”的产物。
-
时机
时机是成功的关键。虽然技术通常会随着时间的推移而不断改进并变得更便宜,但不同领域的进步速度却大不相同。
在某个子领域中,技术的成熟度如何?它是否已经足够成熟,可以大规模应用?还是仍然处于研究阶段,距离实际应用还有数年?时机决定了一个领域是否值得立即投入关注,还是应该暂时观望。
以完全同态加密 (Fully Homomorphic Encryption, FHE) 为例:它的潜力无可否认,但目前的技术性能仍然过于缓慢,难以实现大规模应用。我们可能还需要几年时间才能看到它进入主流市场。因此,我会优先关注那些技术已经接近大规模应用的领域,将我的时间和精力集中在那些正在积聚势头的机会点上。
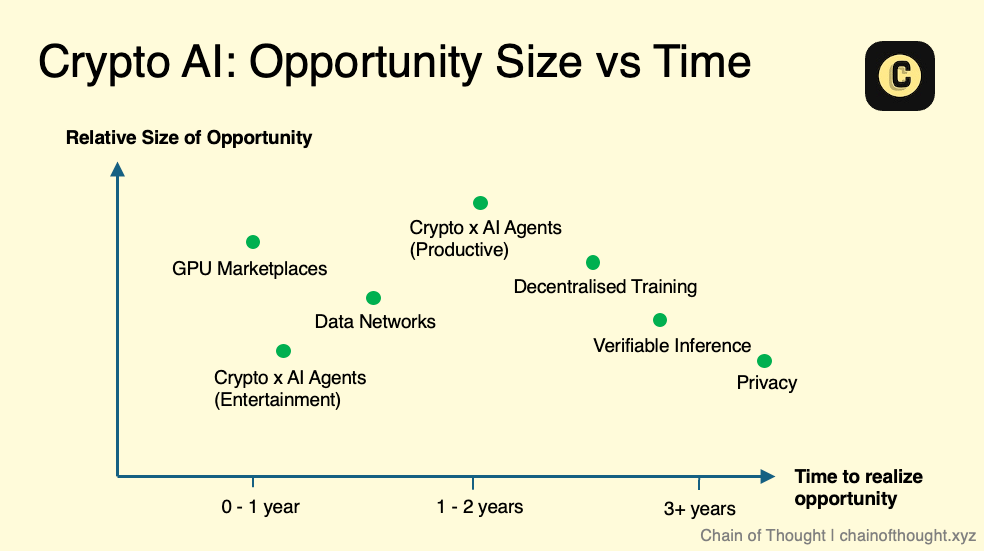
如果将这些子领域绘制在一个“市场规模 vs. 时机”的图表上,可能会是这样的布局。需要注意的是,这只是一个概念性的草图,而不是严格的指南。每个领域内部也存在复杂性——例如,在可验证推理 (verifiable inference) 中,不同的方法(如 zkML 和 opML)在技术成熟度上就处于不同阶段。
尽管如此,我坚信,AI 的未来规模将异常巨大。即使是今天看起来“小众”的领域,也有可能在未来演变成一个重要市场。
同时,我们也要认识到,技术进步并不总是线性发展的——它往往以跳跃式的方式前进。当新的技术突破出现时,我对市场时机和规模的看法也会随之调整。
基于上述框架,我们接下来将逐一拆解 Crypto AI 的各个子领域,探索它们的发展潜力和投资机会。
领域 1:去中心化计算
总结
-
去中心化计算是整个去中心化 AI 的核心支柱。
-
GPU 市场、去中心化训练和去中心化推理彼此紧密关联,协同发展。
-
供应端主要来自中小型数据中心和普通消费者的 GPU 设备。
-
需求端目前规模较小,但正在逐步增长,主要包括对价格敏感、对延迟要求不高的用户,以及一些规模较小的 AI 初创公司。
-
当前 Web3 GPU 市场面临的最大挑战,是如何让这些网络真正高效运转起来。
-
在去中心化网络中协调 GPU 的使用,需要先进的工程技术和稳健的网络架构设计。
1.1 GPU 市场 / 计算网络
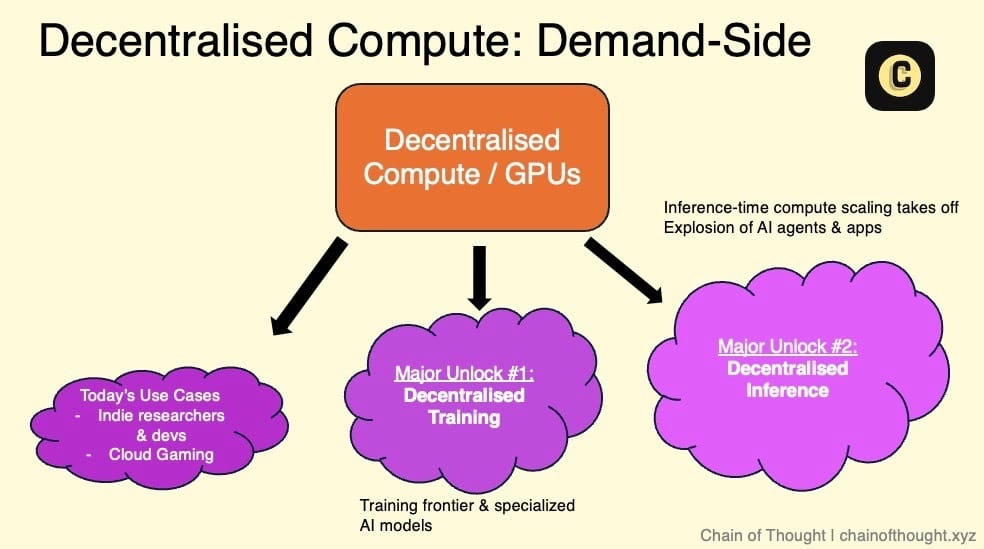
目前,一些 Crypto AI 团队正在建立去中心化的 GPU 网络,以利用全球未被充分利用的计算资源池,来应对 GPU 需求远超供应的现状。
这些 GPU 市场的核心价值可以归纳为以下三点:
-
计算成本可以比 AWS 低多达 90%。这种低成本来源于两方面:一是消除了中间商,二是开放了供应端。这些市场允许用户接触到全球最低边际成本的计算资源。
-
无需绑定长期合同、无需身份验证(KYC)、无需等待审批。
-
抗审查能力
为了解决市场的供应方问题,这些市场从以下来源获取计算资源:
-
企业级 GPU:例如 A100 和 H100 等高性能 GPU,这些设备通常来自中小型数据中心(它们独立运营时难以找到足够的客户),或者来自希望多元化收入来源的比特币矿工。此外,还有一些团队正在利用政府资助的大型基础设施项目,这些项目建设了大量数据中心作为技术发展的组成部分。这些供应商通常会受到激励,将 GPU 持续接入网络,以帮助抵消设备的折旧成本。
-
消费者级 GPU:数百万玩家和家庭用户将自己的电脑连接到网络,并通过 Token 奖励获得收益。
当前,去中心化计算的需求端主要包括以下几类用户:
-
对价格敏感、对延迟要求不高的用户:例如预算有限的研究人员、独立 AI 开发者等。他们更关注成本,而不是实时处理能力。由于预算的限制,他们往往难以负担传统云服务巨头(如 AWS 或 Azure)的高昂费用。针对这一群体的精准营销非常重要。
-
小型 AI 初创公司:这些公司需要灵活且可扩展的计算资源,但又不希望与大型云服务提供商签订长期合同。吸引这一群体需要加强业务合作,因为他们正在积极寻找传统云计算之外的替代方案。
-
Crypto AI 初创企业:这些企业正在开发去中心化 AI 产品,但如果没有自己的计算资源,就需要依赖这些去中心化网络。
-
云游戏:虽然与 AI 的直接联系不大,但云游戏对 GPU 资源的需求正在快速增长。
要记住的关键一点是:开发人员始终优先考虑成本和可靠性。
真正的挑战:需求,而非供应
许多初创公司会将 GPU 供应网络的规模视为成功的标志,但实际上,这仅仅是一个“虚荣指标”。
真正的瓶颈在于需求端,而非供应端。衡量成功的关键指标并不是网络中有多少 GPU,而是 GPU 的利用率以及实际被租用的 GPU 数量。
Token 激励机制在启动供应端方面非常有效,可以快速吸引资源加入网络。但它们并不能直接解决需求不足的问题。真正的考验在于,能否将产品打磨到足够好的状态,从而激发潜在的需求。
正如 Haseeb Qureshi(来自 Dragonfly)所言,这才是关键所在。
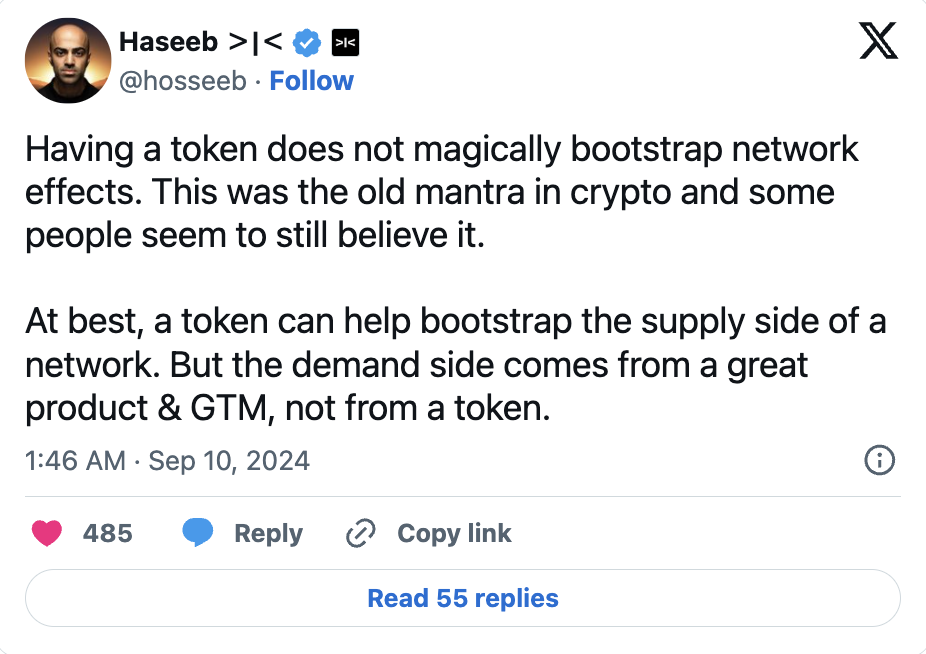
让计算网络真正运转起来
目前,Web3 分布式 GPU 市场面临的最大挑战,其实是如何让这些网络真正高效地运行起来。
这并不是一件简单的事情。
在分布式网络中协调 GPU 是一项极其复杂的任务,涉及多个技术难点,例如资源分配、动态工作负载扩展、节点和 GPU 的负载均衡、延迟管理、数据传输、容错能力,以及如何处理分布在全球各地的多样化硬件设备。这些问题层层叠加,构成了巨大的工程挑战。
要解决这些问题,需要非常扎实的工程技术能力,以及一个健壮且设计合理的网络架构。
为了更好地理解这一点,可以参考 Google 的 Kubernetes 系统。Kubernetes 被广泛认为是容器编排领域的黄金标准,它可以自动化处理分布式环境中的负载均衡和扩展等任务,而这些问题与分布式 GPU 网络所面临的挑战非常相似。值得注意的是,Kubernetes 是基于 Google 十多年的分布式计算经验开发的,即便如此,也花费了数年时间通过不断迭代才得以完善。
目前,一些已经上线的 GPU 计算市场可以处理小规模的工作负载,但一旦尝试扩展到更大规模,问题就会暴露出来。这可能是因为它们的架构设计存在根本性的缺陷。
可信性问题:挑战与机遇
另一个去中心化计算网络需要解决的重要问题是如何确保节点的可信性,即如何验证每个节点是否真正提供了它所声称的计算能力。目前,这一验证过程大多依赖网络的声誉系统,有时计算提供者会根据声誉评分进行排名。区块链技术在这一领域具有天然的优势,因为它能够实现无需信任的验证机制。一些初创公司,例如 Gensyn 和 Spheron,正在探索如何通过无需信任的方法解决这个问题。
目前,许多 Web3 团队仍在努力应对这些挑战,这也意味着这个领域的机会仍然非常广阔。
去中心化计算市场的规模
那么,去中心化计算网络的市场到底有多大?
目前,它可能仅占全球云计算市场(规模约为 6800 亿至 2.5 万亿美元)的一个极小部分。然而,只要去中心化计算的成本低于传统云服务提供商,就一定会存在需求,即使用户体验上存在一些额外的摩擦。
我认为,在短期到中期内,去中心化计算的成本仍会保持较低水平。这主要得益于两方面:一是 Token 补贴,二是来自非价格敏感用户的供应解锁。例如,如果我可以出租我的游戏笔记本电脑赚取额外收入,无论是每月 20 美元还是 50 美元,我都会感到满意。
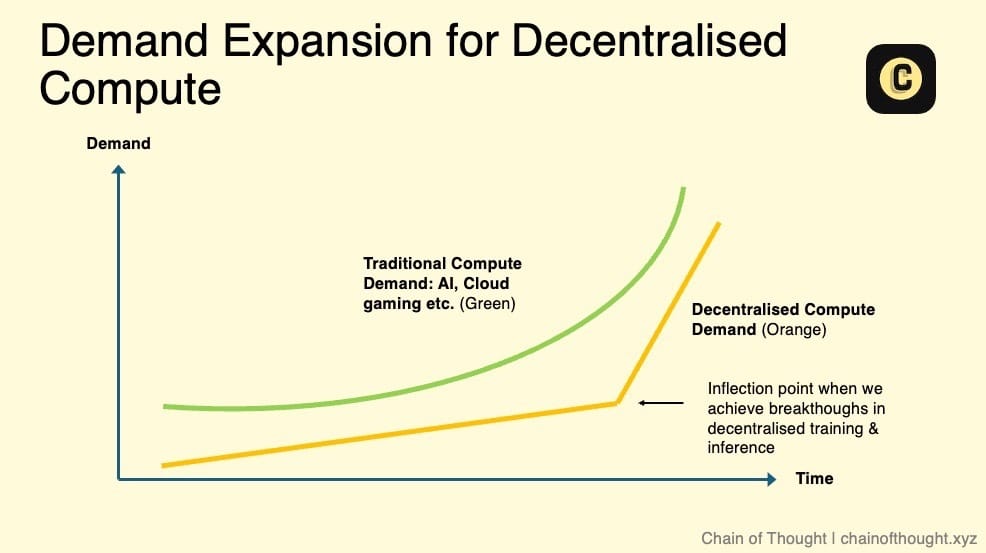
去中心化计算网络的真正增长潜力,以及其市场规模的显著扩展,将依赖以下几个关键因素:
-
去中心化 AI 模型训练的可行性:当去中心化网络能够支持 AI 模型的训练时,将会带来巨大的市场需求。
-
推理需求的爆发:随着 AI 推理需求激增,现有数据中心可能无法满足这一需求。事实上,这种趋势已经开始显现。NVIDIA 的 Jensen Huang 表示,推理需求将会增长“十亿倍”。
-
服务等级协议 (SLAs) 的引入:目前,去中心化计算主要以“尽力而为”的方式提供服务,用户可能会面临服务质量(如正常运行时间)的不确定性。有了 SLAs,这些网络可以提供标准化的可靠性和性能指标,从而打破企业采用的关键障碍,使去中心化计算成为传统云计算的可行替代方案。
去中心化、无需许可的计算是去中心化 AI 生态系统的基础层,也是其最重要的基础设施之一。
尽管 GPU 等硬件供应链正在不断扩展,但我相信,我们仍然处于“人类智能时代”的黎明阶段。未来,对计算能力的需求将是无止境的。
请关注可能触发 GPU 市场重新定价的关键拐点——这个拐点可能很快就会到来。
其他备注:
-
纯 GPU 市场竞争非常激烈,不仅有去中心化平台之间的较量,还面临 Web2 AI 新兴云平台(如 Vast.ai 和 Lambda)的强势崛起。
-
小型节点(例如 4 张 H100 GPU)由于用途有限,市场需求并不大。但如果你想找到出售大型集群的供应商,那几乎是不可能的,因为它们的需求依然非常旺盛。
-
去中心化协议的计算资源供应究竟会被某个主导者整合,还是会继续分散在多个市场中?我更倾向于前者,并认为最终结果会呈现幂律分布,因为整合往往能提升基础设施的效率。当然,这一过程需要时间,而在此期间,市场的分散和混乱还将持续。
-
开发者更希望专注于构建应用,而不是花时间应对部署和配置问题。因此,计算市场需要简化这些复杂性,尽可能减少用户在获取计算资源时的摩擦。
1.2 去中心化训练
总结
-
如果扩展法则 (Scaling Laws) 成立,那么未来在单一数据中心训练下一代前沿 AI 模型将会在物理上变得不可行。
-
训练 AI 模型需要大量的 GPU 间数据传输,而分布式 GPU 网络较低的互连速度通常是最大的技术障碍。
-
研究人员正在探索多种解决方案,并取得了一些突破性进展(如 Open DiLoCo 和 DisTrO)。这些技术创新将会叠加效应,加速去中心化训练的发展。
-
去中心化训练的未来可能更多地集中于为特定领域设计的小型、专用模型,而非面向 AGI 的前沿模型。
-
随着 OpenAI 的 o1 等模型的普及,推理需求将迎来爆发式增长,这也为去中心化推理网络创造了巨大的机会。
想象一下:一个巨大的、改变世界的 AI 模型,不是由秘密的顶尖实验室开发,而是由数百万普通人共同完成。游戏玩家们的 GPU 不再只是用来渲染《使命召唤》的炫酷画面,而是被用来支持更宏大的目标——一个开源、集体拥有的 AI 模型,没有任何中心化的把关者。
在这样的未来,基础规模的 AI 模型不再是顶尖实验室的专属领域,而是全民参与的成果。
但回到现实,目前大部分重量级 AI 训练仍然集中在中心化数据中心,这种趋势在未来一段时间内可能不会改变。
像 OpenAI 这样的公司正在不断扩大其庞大的 GPU 集群规模。Elon Musk 最近透露,xAI 即将完成一个数据中心,其 GPU 总量相当于 20 万张 H100。
但问题不只是 GPU 的数量。Google 在 2022 年的 PaLM 论文中提出了一个关键指标——模型 FLOPS 利用率 (Model FLOPS Utilization, MFU),用于衡量 GPU 最大计算能力的实际利用率。令人意外的是,这一利用率通常只有 35-40%。
为什么会这么低?尽管 GPU 性能随着摩尔定律的推进飞速提升,但网络、内存和存储设备的改进却远远落后,形成了显著的瓶颈。结果,GPU 经常处于闲置状态,等待数据传输完成。
目前,AI 训练高度中心化的根本原因只有一个——效率。
训练大型模型依赖以下关键技术:
这些技术要求 GPU 之间频繁交换数据,因此互连速度(即网络中数据传输的速率)至关重要。
当前沿 AI 模型的训练成本可能高达 10 亿美元时,每一点效率的提升都至关重要。
中心化数据中心凭借其高速互连技术,可以在 GPU 之间实现快速数据传输,从而在训练时间内显著节省成本。这是去中心化网络目前难以匹敌的……至少现在还不行。
克服缓慢的互连速度
如果你与 AI 领域的从业者交流,许多人可能会直言,去中心化训练是行不通的。
在去中心化的架构中,GPU 集群并不位于同一物理位置,这导致它们之间的数据传输速度较慢,成为主要瓶颈。训练过程需要 GPU 在每一步都进行数据同步和交换。距离越远,延迟越高。而更高的延迟意味着训练速度变慢,成本增加。
一个在中心化数据中心只需几天完成的训练任务,在去中心化环境下可能需要两周时间,并且成本更高。这显然不具备可行性。
然而,这一情况正在发生改变。
令人振奋的是,分布式训练的研究热度正在迅速上升。研究人员正从多个方向同时展开探索,最近涌现的大量研究成果和论文便是明证。这些技术进展将产生叠加效应,加速去中心化训练的发展。
此外,实际生产环境中的测试也至关重要,它能帮助我们突破现有的技术边界。
目前,一些去中心化训练技术已经能够在低速互连环境中处理较小规模的模型。而前沿研究正在努力将这些方法扩展到更大规模的模型上。
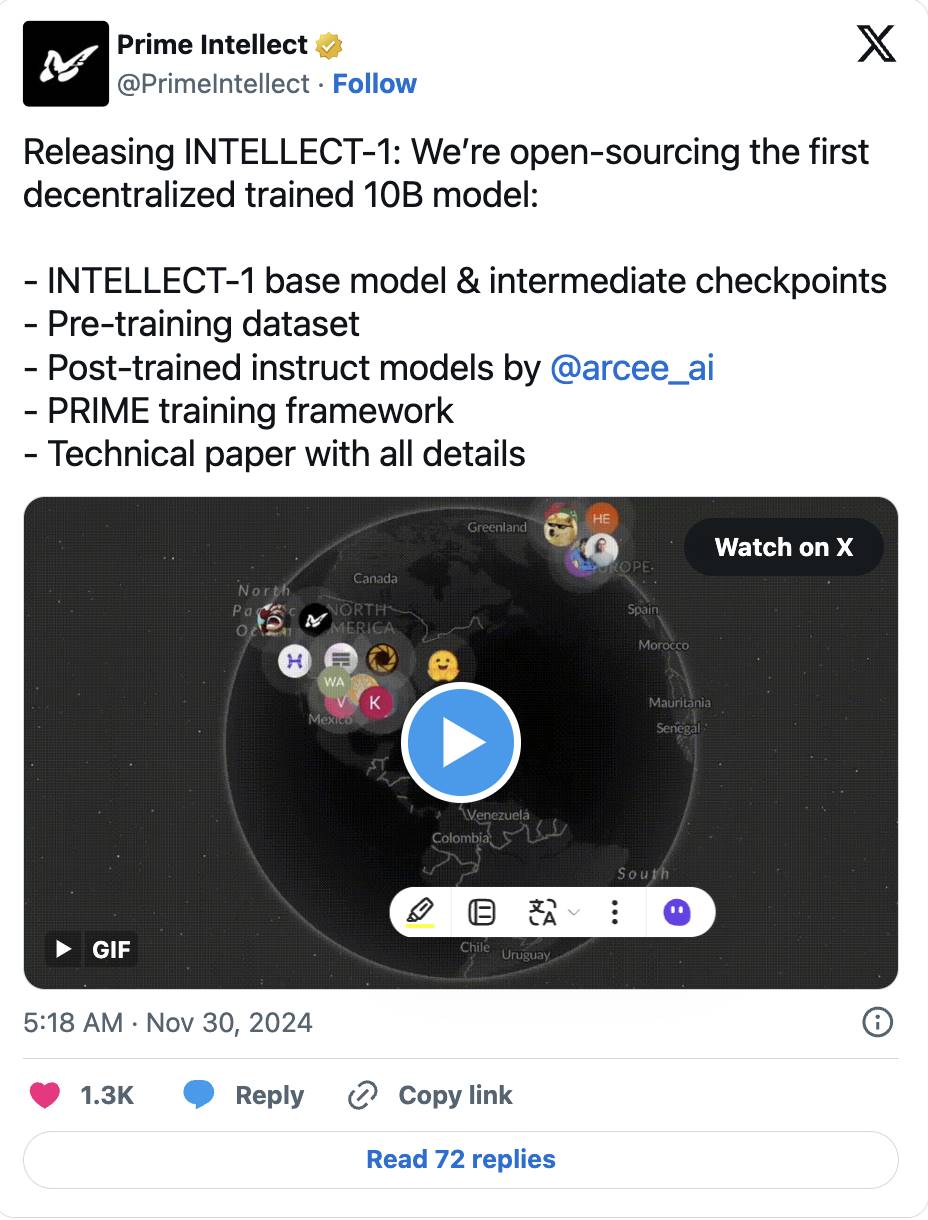
-
Nous Research 的 DisTrO 框架则进一步突破,通过优化器技术将 GPU 间的通信需求减少了高达 10,000 倍,同时成功训练了一个拥有 12 亿参数的模型。
-
这一势头还在持续。Nous 最近宣布,他们已完成一个 150 亿参数模型的预训练,其损失曲线和收敛速度甚至超越了传统中心化训练的表现。
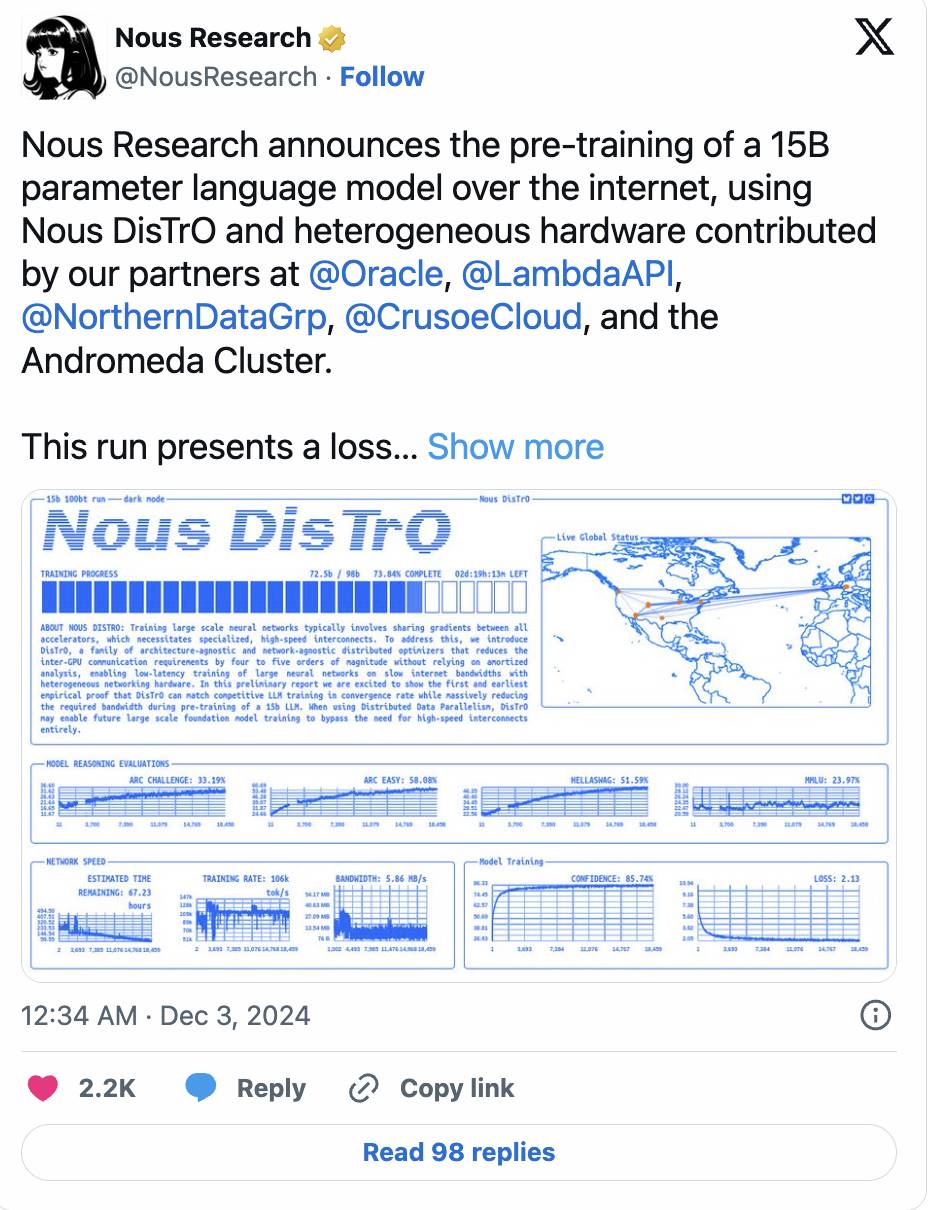
(推文详情)
另一个挑战是如何管理多样化的 GPU 硬件,尤其是去中心化网络中常见的消费级 GPU,这些设备通常内存有限。通过模型并行技术(将模型的不同层分布到多台设备上),这一问题正在逐步得到解决。
去中心化训练的未来
目前,去中心化训练方法的模型规模仍然远远落后于最前沿的模型(据报道 GPT-4 的参数量接近一万亿,是 Prime Intellect 的 100 亿参数模型的 100 倍)。要实现真正的规模化,我们需要在模型架构设计、网络基础设施以及任务分配策略上取得重大突破。
但我们可以大胆设想:未来,去中心化训练或许能够汇聚比最大中心化数据中心还要多的 GPU 计算能力。
Pluralis Research(一个在去中心化训练领域非常值得关注的团队)认为,这不仅是可能的,而且是必然的。中心化数据中心受限于物理条件,例如空间和电力供应,而去中心化网络则可以利用全球几乎无限的资源。
甚至 NVIDIA 的 Jensen Huang 也提到,异步去中心化训练可能是释放 AI 扩展潜力的关键。此外,分布式训练网络还具有更强的容错能力。
因此,在未来的一种可能性中,世界上最强大的 AI 模型将以去中心化的方式进行训练。
这一愿景令人兴奋,但目前我仍持保留态度。我们需要更多有力的证据,证明去中心化训练超大规模模型在技术上和经济上是可行的。
我认为,去中心化训练的最佳应用场景可能在于较小的、专用的开源模型,这些模型针对特定的应用场景设计,而不是与超大型、以 AGI 为目标的前沿模型竞争。某些架构,尤其是非 Transformer 模型,已经证明它们非常适合去中心化的环境。
此外,Token 激励机制也将是未来的重要一环。一旦去中心化训练在规模上变得可行,Token 可以有效激励并奖励贡献者,从而推动这些网络的发展。
尽管前路漫长,但当前的进展令人鼓舞。去中心化训练的突破不仅将惠及去中心化网络,也将为大型科技公司和顶尖 AI 实验室带来新的可能性……
1.3 去中心化推理
目前,AI 的计算资源大部分都集中在训练大型模型上。顶尖 AI 实验室之间正在进行一场军备竞赛,目标是开发出最强的基础模型,并最终实现 AGI。
但我认为,这种对训练的计算资源集中投入将在未来几年逐渐向推理转移。随着 AI 技术越来越多地融入我们日常使用的应用程序——从医疗保健到娱乐行业——支持推理所需的计算资源将变得极为庞大。

这一趋势并非空穴来风。推理时的计算扩展 (Inference-time Compute Scaling) 已经成为 AI 领域的热门话题。OpenAI 最近发布了其最新模型 o1(代号:Strawberry)的预览版/迷你版,其显著特点是:它会“花时间思考”。具体来说,它会先分析自己需要采取哪些步骤来回答问题,然后逐步完成这些步骤。
这个模型专为更复杂、需要规划的任务设计,例如解决填字游戏,并能处理需要深度推理的问题。虽然它生成响应的速度较慢,但结果更加细致和深思熟虑。不过,这种设计也带来了高昂的运行成本,其推理费用是 GPT-4 的 25 倍。
从这一趋势可以看出,AI 性能的下一次飞跃,不仅仅依赖于训练更大的模型,还将依赖于推理阶段计算能力的扩展。
如果你想了解更多,有几项研究已经证明:
一旦强大的 AI 模型被训练完成,它们的推理任务(即实际应用阶段)可以被卸载到去中心化计算网络中。这种方式非常具有吸引力,原因如下:
-
推理的资源需求远低于训练。训练完成后,模型可以通过量化 (Quantization)、剪枝 (Pruning) 或蒸馏 (Distillation) 等技术进行压缩和优化。甚至可以通过张量并行 (Tensor Parallelism) 或流水线并行 (Pipeline Parallelism) 将模型拆分,从而在普通的消费级设备上运行。推理并不需要使用高端 GPU。
-
这一趋势已经初见端倪。例如,Exo Labs 已经找到了一种方法,可以在像 MacBook 和 Mac Mini 这样的消费级硬件上运行一个拥有 4500 亿参数的 Llama3 模型。通过将推理任务分布式运行在多个设备上,即使是大规模的计算需求也可以高效且低成本地完成。
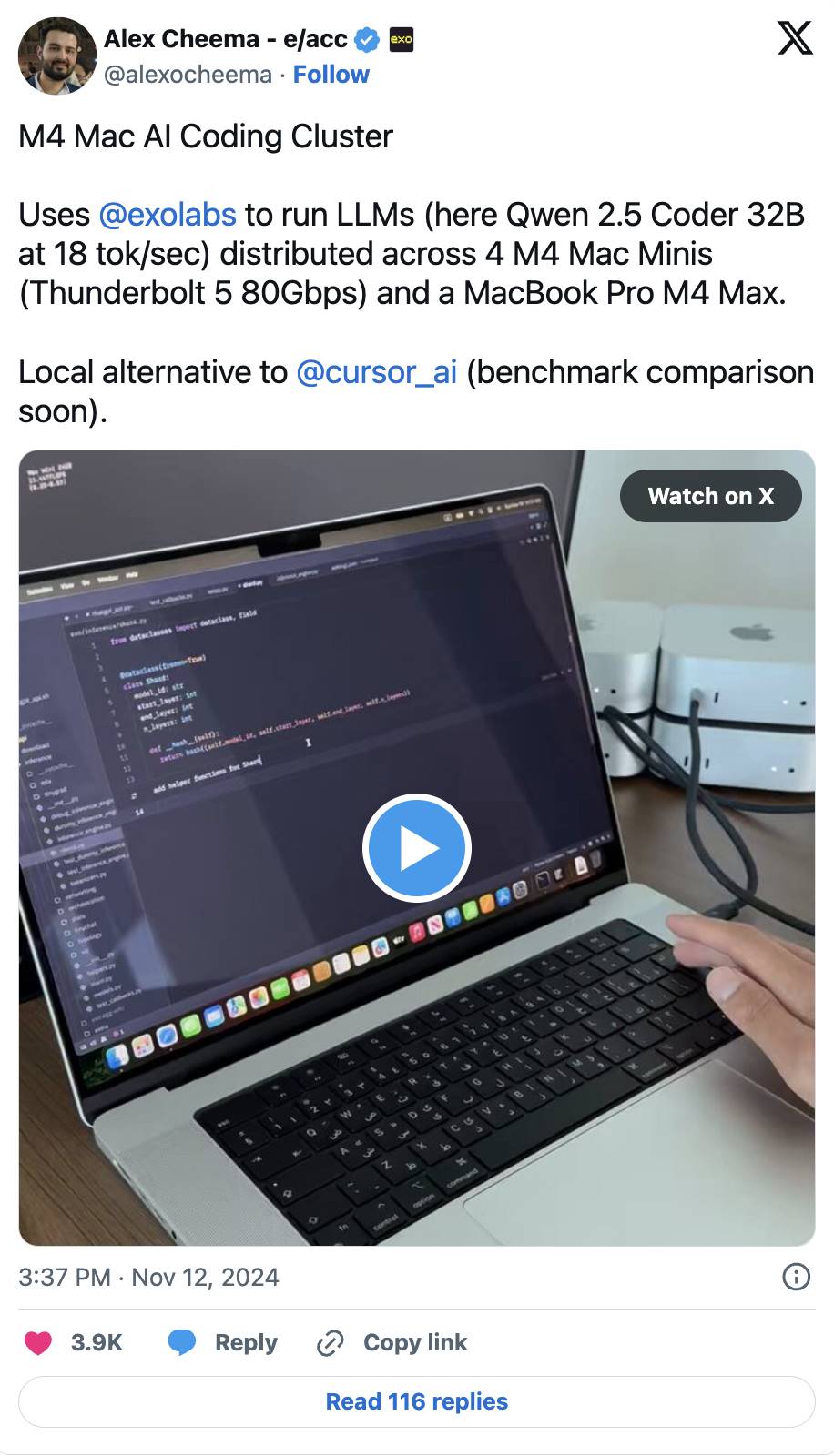
我们可以将去中心化推理比作 AI 的 CDN(内容分发网络)。传统的 CDN 是通过连接到邻近的服务器快速传输网站内容,而去中心化推理则是利用本地的计算资源,以极快的速度生成 AI 响应。通过这种方式,AI 应用程序能够变得更加高效、响应更快,同时也更加可靠。
这一趋势已经初现端倪。苹果最新推出的 M4 Pro 芯片,其性能已经接近 NVIDIA 的 RTX 3070 Ti——这是一款曾经专属于硬核游戏玩家的高性能 GPU。而如今,我们日常使用的硬件正变得越来越能够处理复杂的 AI 工作负载。
加密货币的价值赋能
要让去中心化推理网络真正成功,就必须为参与者提供足够有吸引力的经济激励。网络中的计算节点需要因其贡献的计算能力获得合理的报酬,同时系统还需确保奖励分配的公平性和高效性。此外,地理上的多样性也非常关键。它不仅能减少推理任务的延迟,还能提升网络的容错能力,从而增强整体的稳定性。
那么,构建去中心化网络的最佳方式是什么?答案是加密货币。
Token 是一种强大的工具,可以将所有参与者的利益统一起来,确保每个人都在为同一个目标努力:扩大网络规模并提升 Token 的价值。
此外,Token 还能够极大地加速网络的成长。它们帮助解决了许多网络在早期发展中面临的经典“先有鸡还是先有蛋”的难题。通过奖励早期采用者,Token 能够从一开始就推动更多人参与网络建设。
比特币和以太坊的成功已经证明了这种机制的有效性——它们已经聚集了地球上最大的计算能力池。
去中心化推理网络将是下一个接棒者。通过地理多样性的特性,这些网络能够减少延迟、提升容错能力,并将 AI 服务更贴近用户。而借助加密货币驱动的激励机制,去中心化网络的扩展速度和效率将远远超过传统网络。
致敬
Teng Yan
在接下来的系列文章中,我们将深入探讨数据网络,并研究它们如何帮助突破 AI 面临的数据瓶颈。
免责声明
本文仅供教育用途,不构成任何财务建议。这并不是对资产买卖或财务决策的背书。在进行投资选择时,请务必自行研究并保持谨慎。




 个人中心
个人中心 退出登录
退出登录 PEPE0.00 0.89%
PEPE0.00 0.89%
 SUI3.62 4.85%
SUI3.62 4.85%
 TON3.88 0.90%
TON3.88 0.90%
 TRX0.23 1.74%
TRX0.23 1.74%
 DOGE0.27 -1.07%
DOGE0.27 -1.07%
 XRP2.55 -2.40%
XRP2.55 -2.40%
 SOL206.38 -1.36%
SOL206.38 -1.36%
 BNB574.73 -1.92%
BNB574.73 -1.92%
 ETH2803.84 1.27%
ETH2803.84 1.27%
 BTC98195.78 -1.01%
BTC98195.78 -1.01%




 首页
首页 深潮精选
深潮精选 Research
Research 项目发现
项目发现 7x24h︎快讯
7x24h︎快讯 最新活动
最新活动
 分享至微信
分享至微信
 原文链接
原文链接 添加收藏
添加收藏 分享社交媒体
分享社交媒体
 @0xPrismatic
@0xPrismatic 精选解读
精选解读

 DWF Labs 于 5 天前收到 2000 万枚 KAPPA 用于做市
DWF Labs 于 5 天前收到 2000 万枚 KAPPA 用于做市





 扫码关注公众号
扫码关注公众号





