世界是功利主义的,算法又是确实这个黑盒算法出来的,结果大力真的出了很大的奇迹。
撰文:Sunny,深潮 TechFlow
嘉宾:Jiahao Sun,FLock
“去中心化机器学习已经渐渐不只是一个说辞,更加是一个可行的工程方案。”
– Jiahao Sun, CEO of FLock.io
去中心化人工智能并不是一个新奇的概念,但由于加密货币的兴起,它正在经历一次复苏,为人工智能民主化提供了潜力。然而,对于那些不熟悉该领域的人来说,民主化人工智能的概念可能显得模糊不清。
区块链作为现代网络后端,促进了劳动力和资源的协调和众包。
人工智能广泛涵盖了训练和推理以进行预测,依赖于计算能力、模型和数据。目前,这些要素的控制往往掌握在少数几家主要科技公司手中。尽管人们普遍认为其使用不会作恶,但并没有可验证的保证,这需要一种新的方法来让更广泛的人群参与到人工智能的发展中来。
谷歌之前尝试过联邦学习,用户设备在本地贡献数据和计算能力,然后汇总到一个全球模型中。然而,这种模型仍然保持着中央控制。
区块链通过启用一个私有经济系统,使每个人都能通过代币经济学和加密货币参与提供数据、计算能力和模型,从而提供了一种解决方案。
FLock(基于区块链的联邦学习)通过智能合约和代币经济学引入了真正的联邦学习,确保了更广泛的参与。今天,我们欢迎 FLock 的首席执行官来讨论民主人工智能的概念,以及其在全球卫生等领域的相关性,即使在没有去中心化的论点之上,联邦学习仍旧充满意义。
传统金融 AI 总监到智能合约化联邦学习
TechFlow: 首先请你进行简单的自我介绍,并告诉我们FLock,或者说是去中心化联邦学习到底是什么?
Jiahao:
我在传统的 Web2 的 金融科技圈子干了十年,刚毕业的时候就进了 Entrerpreneur First 的孵化器,那个时候我在做 AI 加持下的 Credit Scoring,是我的第一次创业。那之后很快被猎头挖到了一家 Top Tier 的金融机构,做 Innovation Lead,八年时间一直到做到它们的全球 AI 总监。所以,我算是一直在 AI 研究与应用行业里深耕。
对于 Web3 这个行业产生兴趣,主要是因为2017年的 ICO 春天。看到很多团队似乎随便搞个 idea 都能行,我当时觉得很神奇。不过很明显那个时代的市场很不成熟,或者用现在的话说就是给人感觉土狗太多,感觉会比较没有格调,所以就没有想着说是真的要进场,只是看着说这个行业有点意思。
在疫情期间,时间仿佛有些拖沓,整个欧美都是 Work from Home 的状态,大家都真的突然多了很多时间。这些多出来的时间,可以选择天天打游戏,也可以选择做些有意义的事情。我了打了一年游戏以后,感觉确实有点太浪费人生了,于是选择了做些有意义的事情。回顾 2021 年末,尽管处于加密深熊,却看到了许多引人注目的项目。这些项目由具备丰富Web2经验的团队在Web3领域展现出色,让我深感启发,开始着迷于 Web3 的发展以及真正有意义的技术与叙事。
我最后决定进入 Web3 是因为我们几个人的一篇顶会获奖的研究论文,这是我们几个创始人及研究团队一起对于去中心化机器学习真正奥义的研讨与思考,也是 FLock 作为一个技术词汇(Federated Learning on the Blockchain) 第一次展现在市场上,并且获得了学术界最顶级同行评议的背书,这给了我们全力启动 FLock 这个项目很大的信心和支持。
论文链接:https://scholar.google.com/citations?user=s0eOtD8AAAAJ&hl=en
因为联邦学习或者去中心化机器学习,它一直在行业内存在。
比如英伟达、AWS 也在投资很多类似的分布式计算、分布式机器学习的这些东西,但是这里面永远都有一个问题,假设 AWS 说“我所有这些云计算平台、云计算资源,它都是分散的,你拥有你的云计算平台”,但是你显然不会相信这个点的,因为你还是通过 AWS 来买的某一个云计算,其实 AWS 是有中间控制权,它是最终那个控制人。所以你并不拥有你手上这个 AWS ,你只是租用了它。同理就是用户没有数据所有权。
在解决隐私这个逻辑上,谷歌在 2017 年就提出了联邦学习(Federated Learning)这个概念。
所谓联邦学习还是一个 Machine Learning 那个框架,只不过把所有的计算分散到每个节点里面去,这样就可以不把数据拿出来,每个人都在每个节点里面做一个 Local Compute,简单来讲就是把结果综合起来,得到一个最后的综合大模型,这个大模型可以体现出所有数据被训练之后的结果,又能够防止我需要把数据放到任何第三方的服务器上这件事。
所以整个这样一套逻辑就称为联邦学习,最早谷歌他们提出来之后,他们就把这套逻辑用在了输入法预测上。所以当时很多 Pixel Phone 的用户很早就已经体会到什么是联邦学习了,你用谷歌的手机打字的时候,他会给你预判下一个字。其实这就是联邦学习最早在现实中的应用。
但就像我刚刚举的例子一样,同样的,谷歌控制了所有这个 Training 过程,它是可以作恶的,它可以看到所有的源代码,可以看到所有的原数据,没法证伪自己没看到。那个时候就出了一件非常有意思的大事,某中文输入法软件爆了雷,它也说自己搞联邦学习保护用户隐私,但后来被人挖到,它背后回传了所有的用户的输入法数据,全部直接回传到中心化服务器的,并没有搞什么联邦学习。
所以这几点就是最近在整个技术圈比较火的事件,大家开始质疑 “如果让一个人来控制所有这些资源的话,他是否能够保证他自己不作恶?” ,他如果保证的话,你又是否能够信他。显然其他厂家不信,不然苹果和谷歌早就一起加入,一起训练一个输入法预测模型了。
所以这是为什么我们把区块链智能合约的机制加入到整个传统的联邦学习框架里面,这样就不需要谷歌了,不需要中间有一个人做资源分配,我们每个人都是个独立的个体,我们自己有自己的节点,我只算我的那部分,然后通过智能合约来决定谁上传的 Gradient 是有用的,哪个需要综合起来,全部靠就这一套链上的 Consensus 去解决。这是 FLock 最早作为一个 Research Idea 的一个点。
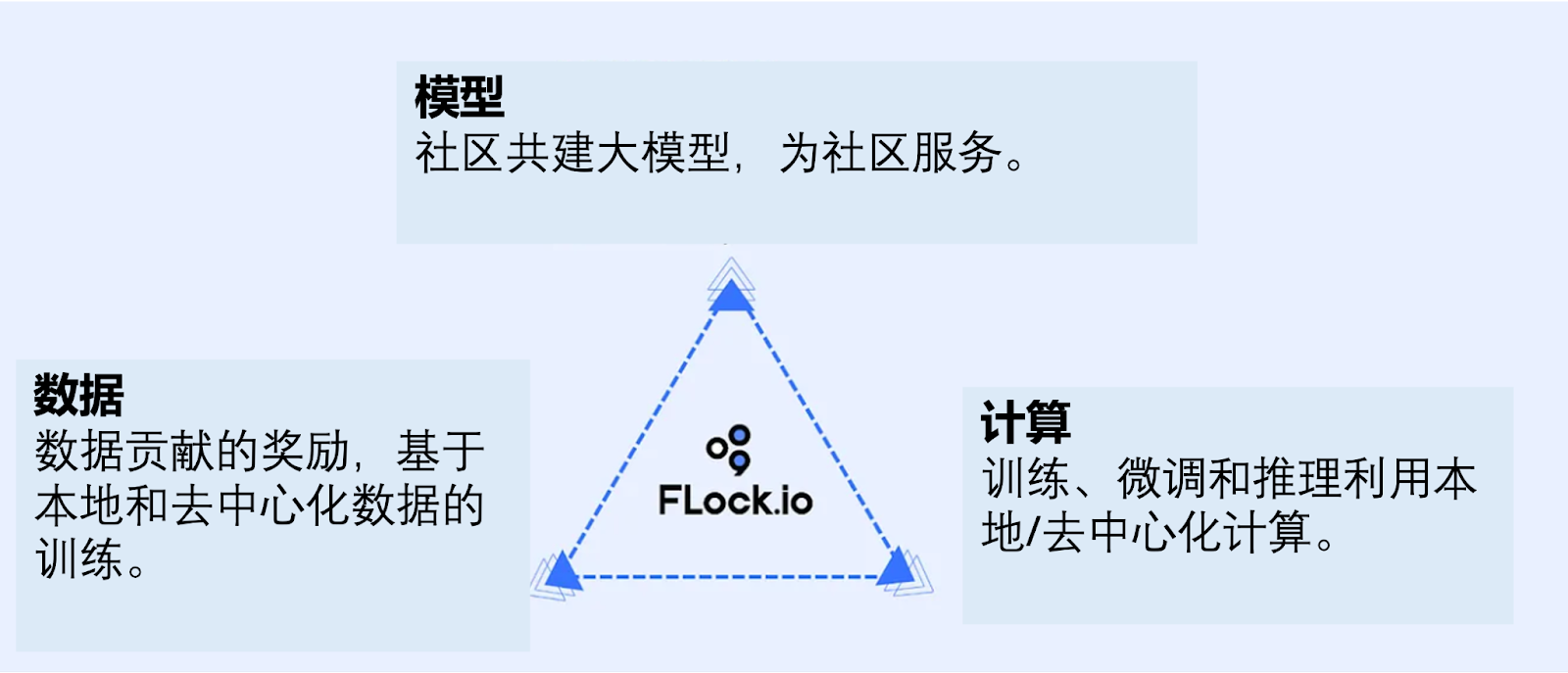
FLock 通过智能合约协调计算, 模型和数据的社区共建
先理解:被训练过的数据还是不是你的数据?
TechFlow:那么首先在个体节点上,本地个体数据是怎么被进行加密然后加入到综合大模型进行训练的,并且在得到一个训练结果的前提下仍旧保证起始数据隐私?
Jiahao:
我举一个例子,WorldCoin,拍一个自己的虹膜照片,然后通过神经网络绕一圈,把它变成一个Embedding,那这个 Embedding 就不是你的虹膜照片了,对不对?就看人们相不相信这个逻辑
–“那不是我的虹膜了,那是一个新的 Embedding”。
当然有些人不认这个逻辑,他认为这还是自己的数据的衍生品。
我们一步步讲,首先认这些逻辑的人,在这个联邦学习的逻辑里,个人数据从来没有从个体节点出来,出来的东西是你的数据把一个 Local 模型训练完之后这个模型的变化,这个变化值我们称之为梯度(Gradient)。
我们只传这个梯度到下一个节点,整个过程中没有任何跟你数据有关的任何东西被传到下一个节点,它是完全保密的。所以理论上不需要做任何的加密,因为这东西本来就不是你的数据。
如果你不认这个逻辑,你觉得我数据的衍生品也是我的数据,就算那个东西它不是我的虹膜了,被你的神经网络处理过了,它是一个嵌入(Embedding),但是这个 Embedding 还是能够对应到我的数据,那我们会在这个标留的信道上做一层加密。
把这个节点的传到下一个节点,我们对节点本身的传输也会做一层加密,有好多种方法,现在有一些特别有意思的方法叫 Deep Gradient Compression,我们可以做到节点数据的传输被压缩到 5% 以下。既加快了传输速度,又顺手解决了加密隐私问题,还不影响模型准确性,一举三得。
为什么呢?首先,本来在 Machine Learning 中,为了防止数据过拟合或者模型过拟合,每次计算的时候都会做一些 Dropout,或者说故意遗漏一些数据,从而达到更好的计算准确率。比如我算到了100%,我都要把它省略到百分之七八十,再进行传输,因为我们怕 100% 的话会让他一头劲的往里面冲,冲到最后冲到一个过拟合的点,那是个局部最优解,而不是个全局最优解。这个方法其实能够增加我们整个计算的准确度。
第二,我们发现在深度学习领域,当我们把 Gradient 压缩到极致(例如 5% 及以下)时,这些 Gradient 中的信息已经完全被压缩到任何人无法恢复你的数据的程度了——这就相当于你在任何一个图片上打上很厚的马赛克,哪怕最好的AI也不可能完全恢复原始图片的任何细节,它可能脑补,它可能乱猜,但是由于可被利用的信息太少了,能还原出的东西是极度有限的。根据信息论,没有人能够把它再回复成你的数据了,所以这是一层已经让人可以放心的加密。
当然,第三就是,数据的 Payload 小了,那自然传输效率就提升上来了,就算是几十b的大模型,在我们的优化下,多台普通家用机器的去中心化调优也可以在几个小时内完成。
去中心化机器学习已经渐渐不只是一个说辞,更加是一个可行的工程方案。
这本质上就不是涉及到区块链或者联邦学习本身这一套机制的问题,而是涉及到节点之间的加密传输,那只要能保证它是安全的就行。我上面说的只是一种解决思路,包括ZK,包括FHE,包括TEE,其实都可以作为解决加密的方案。这里面,FLock 跟所有的这些技术都可以很好的兼容,甚至我们自己还出了一篇 Paper 叫 zkFL。
联邦学习 + 智能合约 = FLock
TechFlow: 在联邦学习每个节点是在处理学习自己的数据,然后提交一个节点,然后会发生什么?对于一个不太懂 AI 的人怎么解释这个 Consensus?
Jiahao:
这一堆节点相当于是个圈子,我们使用了 Ring-all Reduce 的方式,从一个节点推到下一个节点,再推到下一个,不用有中间人做管理,直到某一个节点收到第二次数据时,这堆节点就完成了一个圈,这个叫 Gradient 加成。这样加成完之后每个人都把它的 Local 模型都更新到一个新模型。
Consensus 是发生在一个没有人管理的系统,为什么谷歌需要管理这样一个中心化的联邦学习系统?
他是怕这个里面有节点会作恶,比如我算的数据不是我真的数据,或者我给的结果直接给一堆乱码数据,这些是为什么需要一个中间人管理的原因。这也是在传统 Web2 世界里做联邦学习大家都需要签个合约的原因,我只能跟可信的人一起来做联邦学习。
而 FLock 来做是通过去中心化的方案,涉及到怎么去防止这些作恶节点,我们用智能合约来替代中间那个管理人,我们相当于做 Validator,用智能合约做Validation。
机器学习是结果导向的,只要去验证这个数据跑完之后的模型出来的结果,是否往准确率高的方向跑的。
假如别人都在往一个数据高的方向跑,而你在往一个数据低的方向跑,你就会被Slash,当然不会一下子 Slash 掉,而会慢慢Slash,如果你一直还是跟别人不一样,才最终被 Slash out。
这是一个博弈机制,通过智能合约管理。
那会不会有一些极端情况的出现呢?这就是整个 Tokenomics 的意义。
我们在 Paper 里论证过很多极端情况,我这里举个简单的例子:
假设我这个数据里面都是右惯手用户,其中一个节点是左惯手用户,他的数据跟别人确实有点不一样,但他是真实的数据。这个时候再做出一次计算,别的所有的右惯手用户的的那个模型都会往右偏,然后左惯手用户的这个模型往左偏了,那么在第一轮的时候确实通过我们 FLock 的 Concensus,这个左惯手用户的节点会往下slash,因为他跟别人不一样,然后再到第二轮的时候,他又会往下 slash 一点点,但是在过了几轮之后,因为这个用户的数据是真实的,他对于模型的贡献也是真实的,于是模型训练的变化会在某个epoch(训练轮次)的时候开始慢慢的往左惯手用户这边偏。从而导致所有其他人也都会往左惯手这个模型结果的位置偏。
根据我们的 Tokenomics,在整个这样一个 FLock 的系统里面,最终模型往谁的方向偏(通俗地讲法),那么 Rewards 的分成就会往谁的那边偏移。于是,虽然左惯手的节点在早期可能会因为数据的独特性被 slash 一下下,但是最终会因为他对于终极模型的贡献,而得到更多的 Rewards 倾斜,反而得到更多的收益。
这是我们设计整个这一套 FLock 机制的一个原因,这也是为什么我们从论文入手,发顶级会议,然后开始搞这个FLock,因为这里面很多东西需要深思,于是我们团队早期其实完全没有做 Monetization 的事情,就是在那论文、写代码、做实验,然后做simulation,并且我们能得到 Peer Review 的肯定(NeurIPS,TAI,Science等),去确保我们这个东西的基础足够坚实,能够经得起实验的考验,之后我们才开始建设 SDK 和 testnet。
TechFlow: 能简单的讲述一下这个 Tokenomics 里面,或者说这个 Network 里面的 Player 都有谁吗?
Jiahao:
这里面 Players 是 Planer, Trainer 和 Validator 三方:大家可以把它抽象成一个任务平台,就像传统 AI 圈的 HuggingFace 一样,所谓 Planer就是任务的发布方,来发布任务,并提供 Incentive 给到参与任务的人;Trainer 就是那些 AI 开发者,数据拥有方,我有模型或者我有数据,我来这里面做贡献,期待获得收益;Validator则通过提供算力以及 AI 模型的准确度验证,来确保系统一直是公平高效地运行。
Go-to-Market
TechFlow:FLock 智能合约在前端上是怎么呈现的呢?比如你刚才讲的图片识别,它的步骤是怎样的?
Jiahao:
每个用户打开网站或打开我们的客户端,定位自己的本地数据,然后点击 Training 就可以进入整个 Training 过程了。我们对于 Retail 用户而言,做到了Seamless的用户体验
TechFlow: 不同任务的 Matching 是怎么搞定的?
Jiahao:
我作为一个训练的人,我的数据可以 Match 不同的东西。比如说,一个医院搞的睡觉数据,有每天睡觉的数据集,我就选择去加入这个,有点像个 Marketplace,我作为数据拥有方,我有权利选择去加入这个或是加入那个。在这个 Marketplace 里的 Incentive 是由 Business 方提供的。比如说医院、银行、De-Fi,他们放个Bounty,比如放200K,去激励成员参加他们自己在 FLock 上构建的subnet(子网络)。
TechFlow: 所以你们做市场的时候是先去搞定这个 Business 那一方?
Jiahao:
对,我们现在已付费用户都是 Business 的 Contract。我们已经交付了几期,现在我们想上线 Marketplace,让更多的 Business 可以在上面就直接发布任务,更加的 2C 向,而不是需要去走 B2B 的模式来 onbaord。
TechFlow: 传统数据提供商户对于 Web3 的的接受程度是怎样的?
Jiahao:
这件事让他们的成本降低了,如果他们做 Off-Chain 的话整个过程可能要历时几个月,还要过很多审核。另外,如果他们想搞跨国之间的 Clinical Trial 的话,问题会更严重,因为几乎任何国家都不会让医疗数据出境,所以很多情况下就这事就做不了。
所以 FLock 的出现对他们而言是一个突破:
第一,本人的数据都在本地,不需要过那么多监管。
第二,可以做一些以前没想到的事情,比如说跨国之间,中日韩一起搞一个更好的、对于东亚人身体机制的一个联邦学习去算血糖原预测和监测。
除此之外的话还有一些更大的想象力,这些也是之前我们合作的医院方跟我们聊的,像是远程医疗,之前这件事不太有可能,主要就是因为数据不可能出境,那用联邦学习的方式的话,就可以做到我这边做监测,他那边出结论,那两边的东西其实都不看到,但是对患者而言的话我就少了很多麻烦--我不用飞到任何一个第三个国家去来做个体检之类的。至少我从我了解来看,就对于医疗行业而言,它们可能是我聊下来发现最懂联邦学习的一个行业,然后第二个最懂这个行业就是金融行业,因为他们已经被无数前赴后继的技术公司 Pitch 过很多遍了。
不过我们也没有做传统的 Finance 行业,我们直接去跟 DeFi 合作,因为他们是完全懂 Web3,相互的理解门槛最低。
我们 Marketplace 上线的时候应该会侧重一些更有贴近个人需求的AI初创公司,比如说做声音模拟的。之前某人工智能生成相机拍照的小程序突然不火了,就是因为他们那个隐私条款里面有一句非常可怕的话,“你的所有的照片的版权归****所有”,很多人都不想用了,毕竟你要上传 10 张你的脸的照片。但对做声音模拟这些 startup 而言,他们想用 FLock 的原因就是他们想要把 FLock 当成一个隐私保护的定心丸一样贴在他们的产品上,让用户去放心--我的声音就还是在我的本地,并且在链上可以查到我的声音从来没有被传到任何第三方,同时我又可以用我的声音去玩声音模拟,比如说去学赵本山说话或者怎么样。
所以终局形态的话,我还蛮希望 FLock 成为一个就是隐私行业的一个 CertiK 这种感觉。让它成为隐私保护和去中心化模型训练的标准化制定者。
TechFlow: 你研究了多久 P2P Network后觉得可行?
Jiahao:
我们搞了一年不到吧。几篇 Paper 发出去很快就能就被发表,让我们觉得这东西有点意思。
我觉得评审对我们而言也是个风向标的,如果你发的东西别人都觉得无聊、不新颖,那这东西可能也没法 Monetized。但我们当时一发出去,各种反馈都很棒,这样的正反馈是很有帮助的。
但其实这都是从学术界的反馈,到 Monetization 的阶段还是有很多努力要去做的,就是如何让资本觉得这件事 Make Sense?如何让资本觉得就是这东西有前途?这就是另外一个挑战
第一阶段我们称之为 R&D 阶段,接下来就是我们推出测试版本和开源代码库之后的第二阶段。在2023年深熊的时候 Close了我们六百万美元的 Seed 轮,Lightspeed Faction(光速美国)领投,这也给了我们很大的信心,在市场最差的时候,有这么 Top Tier 并且是专注投 AI 的 Fund 投了我们,这也对我们长线的发展有了很大的预期。
现在是在我们第三个阶段--就是整个市场的肯定。我们会推出整个 FLock 的去中心化训练平台,它是一个 Marketplace,让所有的用户都可以构建模型构建属于自己社群的AI。我们的网络也早早就被全球市场上最大的 Validator 们预定支持了。
TechFlow: 现在大家看到了 Web3 的潜力,很多项目都是利用区块链技术应用在现实生活中,你们也是。你们怎么增加自己的市场曝光呢?
Jiahao:
我们有点想打爆款的逻辑,就是爆款的应用,或者刚需的应用的出现,比如说我们之所以要跟 DeFi 这个圈子走这么近,就是因为很多在这方面在 DeFi 这个圈子很多需求是刚需,但是又没有办法被满足。
比如说做个人信贷的时候,信贷数据跟线下银行卡肯定不能绑起来,FLock 就能在你的节点内部进行一个计算,出一个信用分,来给别人做信用凭证。当然可能到现在还不能做到 低 Collateral 的借贷,肯定都得超 Collateral,但可能别人是 150% 的 overcollateral,你可以做到 105% 的 Collateral,加强了个市场做借贷的效率。对于很多用户而言的话,这是个刚需。
第二就是爆款点,就像刚刚说的那个做声音模拟,又火一波,大家互相分享,大家喜欢那些网红也都在分享的话,那我可能也想去下载一下这个APP。
主要是这两个逻辑点,是我们想去获客的一个渠道。
TechFlow: FLock 也算是 DePin 的一个赛道,FLock 和现在的 Decentralized Compute 还有 Decentralized Storage 之间的关系是怎样的?
Jiahao:
那我觉得上下游之间就是互相合作挺好的。因为我们是 Training Layer,只是一层 Layer,在整个构建中的话,我们相当于像 TensorFlow、pyTorch 这样的一个地位,在传统行业里面对标的是训练中层,还是需要 AWS 去放你的模型,你还是需要用 AWS 的 s3 去存你的数据,我们只做串联工作的,算力从哪来? 以及存储方案的解决商也有很多。
我觉得数据去中化技术存储可能创新的机会没有那么大,大家都已经很大了。我们第一版的 Test Net 就是在 IPFS 上上下层合作蛮好的,用 Decentralized Compute 能够让普通用户可以无缝的、无难度的体验 FLock 的机制。
按照原教旨主义的讲法,比特币要怎么用?应该是用家里的电脑打开之后下载全世界的Ledger,再转一笔账到另一个电脑。那 FLock 原教旨主义用法也应该是这样,你应该是打开你自己家的电脑,把你数据都放在你自己家,你不可能把它放在任何第三方,因为它才这才是最安全的,然后再连入 FLock 网络。但你没有办法去要求,很多人都有一台很好电脑,并且永远把它连着网。所以我们跟 Decentralized Compute 和 Data 的合作最重要点就是用户可以登陆 FLock 放到一个Decentralized Storage 上,再用去中心化的算力,FLock 是作为一个中间协调商进行协调数据,跟别人的算力进行协调,去算出一个结果,并且还能分配到公平透明的 Rewards。这样你作为一个用户,就像一个 Metamask 一样,直接登录,然后点击完事,然后你就走了。你也不需要去真的有一个电脑跑去 Host 自己的数据。
对我们而言,上下游的合作就是为了让用户体验更好。
关于AI的题外话:GPT, GNN, 和其他大模型
TechFlow: 你之前在银行的时候是不是也做了联邦学习?
Jiahao:
其实没有,在银行更多是 NLP,主要就是 Graph Neural Network、Knowledge Graph这些,所以我是对这个行业略懂的。当时 GPT 火了之后突然发现这个知识图谱和神经网络行业完全冷掉了。我还在帝国理工带两个博士生,我这两个学生的毕业论文都要重写,需要换,不然别人会很容易就 Challenge 你的:那为什么不直接用GPT?
TechFlow: GPT是 Semantic Gata,Graph 更多是 non-Semantic Data?
Jiahao:
可以这么说,但是大力出奇迹,如果 GPT 能够解决问题的话,那你为什么还要去 Propose 一个 Graph Behind GPT 呢?2022 年在 NeurIPS 上,当时我也是论坛的嘉宾之一,跟华为 Research 的 Boxing Chen 老师,微软的 Yu Cheng 老师,以及 Meta 的 Marjan 老师等在聊 NLP 的未来的时候,当时我想强行再给我的 Knowledge Graph 再增加一点这个流量。
但主流的反馈也是说,假设我们有最高的算力、最厉害的算法、最厉害的数据,我都已经能够直接 End to End 达到结果了,为什么还要去深度分析里面的每一个关系网络是长什么样子的。世界是功利主义的,算法又是确实这个黑盒算法出来的,结果大力真的出了很大的奇迹。
你如果要做这个判断分析的话需要的成本太高,并且效果会很慢。我可以举个非常直观的例子:神经网络在刚开始出来的时候,大家也很反对,老学究们也很反对他,他说我们要用统计学的方法,我要知道因果关系:a 为什么能够得到 b,要把公式都算出来,这才叫机器学习。
但是那群搞神经网络人说何必呢? a 就是能得到b,我给你做个神经网络,它能把 a 转成 b 就可以了,不行的话我再把这个神经网变大一点,不行的话再大一点,再放出更好的,就是能够变成 b。你看现在,还有人质疑神经网络不够透明么?反而是曾经强烈需要因果分析的那些行业(比如高频交易基金),改变了自己的内部审计方案,直接用端到端测试来解释自己的策略,而摒弃了所有的因果分析报告。
站在消费主义市场观察的角度,我觉得 Graph 的未来可能也是这样,当大模型走到这一步之后,再到下一个周期,可能人们就快忘了为什么还需要一个 Graph 的存在。可能会被下一代的人认为这是上一代老学究在研究统计学算法。
不过,我还是要申明,基础科学的研究永远是必要的,我也永远会力所能及的支持。Graph 在研究领域依旧还有很长很 Promising 的道路。这毕竟也是我奉献了 10 年的研究背景。哈哈。
更多阅读
- https://www.youtube.com/watch?v=4zrU54VIK6k
- https://flock-io.medium.com/what-is-flock-71ac590c4e2d
- https://flock.io/





 个人中心
个人中心 退出登录
退出登录 ONDO0.43 -4.04%
ONDO0.43 -4.04%
 TRUMP5.40 -1.43%
TRUMP5.40 -1.43%
 SUI1.52 -4.60%
SUI1.52 -4.60%
 TON1.53 -4.34%
TON1.53 -4.34%
 TRX0.28 1.82%
TRX0.28 1.82%
 DOGE0.13 -1.65%
DOGE0.13 -1.65%
 XRP1.94 -2.89%
XRP1.94 -2.89%
 SOL129.68 -0.84%
SOL129.68 -0.84%
 BNB866.11 -2.20%
BNB866.11 -2.20%
 ETH3037.75 -1.18%
ETH3037.75 -1.18%
 BTC87627.03 -1.55%
BTC87627.03 -1.55%




 首页
首页 深潮精选
深潮精选 Research
Research 项目发现
项目发现 7x24h︎快讯
7x24h︎快讯 最新活动
最新活动
 分享至微信
分享至微信
 添加收藏
添加收藏 分享社交媒体
分享社交媒体
 深潮TechFlow
深潮TechFlow 精选解读
精选解读

 原创
原创 今日 10 只美国比特币 ETF 净流入 104 枚 BTC,9 只以太坊 ETF 净流出 7,225 枚 ETH
今日 10 只美国比特币 ETF 净流入 104 枚 BTC,9 只以太坊 ETF 净流出 7,225 枚 ETH





 扫码关注公众号
扫码关注公众号





