




 个人中心
个人中心 退出登录
退出登录
 ONDO0.39 -5.49%
ONDO0.39 -5.49%
 TRUMP5.15 -2.24%
TRUMP5.15 -2.24%
 SUI1.43 -5.31%
SUI1.43 -5.31%
 TON1.48 -4.46%
TON1.48 -4.46%
 TRX0.28 -0.42%
TRX0.28 -0.42%
 DOGE0.13 -3.64%
DOGE0.13 -3.64%
 XRP1.88 -2.59%
XRP1.88 -2.59%
 SOL123.18 -3.75%
SOL123.18 -3.75%
 BNB844.16 -3.10%
BNB844.16 -3.10%
 ETH2825.66 -4.26%
ETH2825.66 -4.26%
 BTC86094.32 -1.76%
BTC86094.32 -1.76%




 首页
首页 深潮精选
深潮精选 Research
Research 项目发现
项目发现 7x24h︎快讯
7x24h︎快讯 最新活动
最新活动
 分享至微信
分享至微信
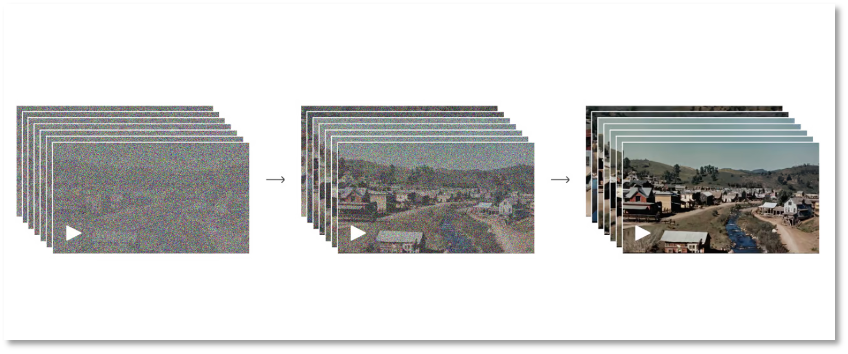 从全噪点到清晰图的过程
从全噪点到清晰图的过程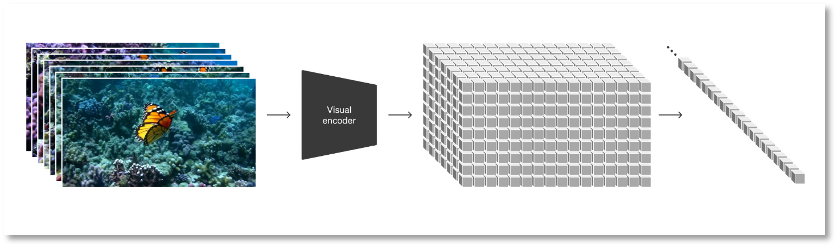 将视觉数据转化为 patches
将视觉数据转化为 patches 原文链接
原文链接 添加收藏
添加收藏 分享社交媒体
分享社交媒体 精选解读
精选解读

 原创
原创 River:S3 快照将于 12.19 进行,S4 将于 12.22 启动
River:S3 快照将于 12.19 进行,S4 将于 12.22 启动





 扫码关注公众号
扫码关注公众号





