Plasma无法解决数据扣留问题,也不利于把合约状态迁移到Layer1,必然被废弃。
撰文:Faust,极客 web3
关于 Plasma 为何被长期埋没,以及 Vitalik 会大力支持 Rollup,线索主要指向两点:在以太坊链下实现 DA 是不可靠的,很容易发生数据扣留,而数据扣留一旦发生,欺诈证明就难以展开;Plasma 的机制设计本身对智能合约极其不友好,尤其难以支持合约状态迁移到 Layer1。这两点使得 Plasma 基本只能采用 UTXO 或近似的模型。
为了理解上述两个核心观点,我们先从 DA 和数据扣留问题讲起。DA 的全称是 Data Avalibility,字面译作数据可用性,现在被很多人误用,以至于和「历史数据可查」严重混淆。但实际上,「历史数据可查」以及「存储证明」是 Filecoin 和 Arweave 等早已解决的问题。按照以太坊基金会和 Celestia 的说法,DA 问题单纯探讨数据扣留场景。
Merkle Tree 和 Merkle Root 及 Merkle Proof
为了说明数据扣留攻击与 DA 问题究竟指什么,我们需要先简单讲一下 Merkle Root 和 Merkle Tree。在以太坊或绝大多数公链中,用一种称作 Merkle Tree 的树状数据结构,充当全体账户状态的摘要 / 目录,或记录每个区块内打包的交易。
Merkle Tree 最底层的叶子节点,由交易或账户状态等原始数据的 hash 构成,这些 hash 两两一组求和,反复迭代,最终可以算出一个 Merkle Root.
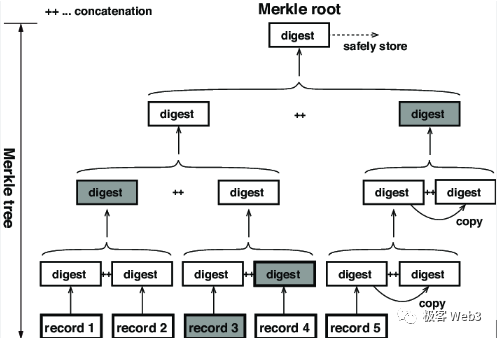
(图中最下面的 record 就是叶子节点对应的原始数据集)
Merkle Root 有一个性质:如果 Merkle Tree 底层某个叶子节点发生变化,计算得到的 Merkle Root 也会发生变化。所以,对应不同原始数据集的 Merkle Tree,会有不同的 Merkle Root,就好比不同的人有不同的指纹。而被称作 Merkle Proof 的证明验证技术,利用了 Merkle Tree 的这个性质。
以上图为例,假如李刚只知道图中 Merkle Root 的数值,不知道完整的 Merkle Tree 包含哪些数据。我们要向李刚证明,Record 3 的确和图中的 Root 有关联性,或者说,证明 Record 3 的哈希存在于 Root 对应的那棵 Merkle Tree 上。
我们只需要把 Record3,以及标记为灰色的那 3 个 digest 数据块,提交给李刚,而不必把整个 Merkle Tree 或其所有叶子节点都提交过去,这就是 Merkle Proof 的简洁性。当 Merkle Tree 底层记录的叶子特别多时,比如包含了 2 的 20 次幂个数据块(约 100 万),Merkle Proof 最少只需要包含 21 个数据块。
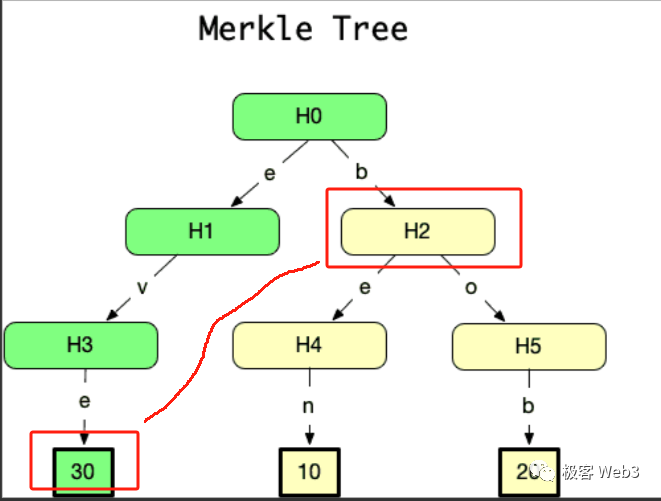
(图中的数据块 30 和 H2 就可以构成 Merkle Proof,证明数据块 30 存在于 H0 对应的 Merkle Tree 上)
在比特币、以太坊或跨链桥中,经常用到 Merkle Proof 的这种「简洁性」。我们所知的轻节点,其实就是上文提到的李刚,他只从全节点那里接收区块头 header,而不是完整的区块。这里需要强调,以太坊用称为 State Trie 的默克尔树,充当全体账户的摘要。只要 State Trie 关联着的某个账户状态发生变化,State Trie 的 Merkle Root——称为 StateRoot 就会变化。
以太坊的区块头中,会记录 StateRoot,同时也会记录交易树的 Merkle Root(简称 Txn Root),交易树和状态树的一个区别,在于底层叶子所代表的数据不同。假如第 100 号 block 内包含 300 笔交易,则交易树的叶子,代表的就是这 300 笔 Txn。
另一个区别在于,State Trie 整体的数据量特别大,它的底层叶子对应着以太坊链上所有地址(实际上还有很多过时的状态哈希),所以 State Trie 对应的原始数据集不会发布到区块中,只在区块头记录下 StateRoot。而交易树的原始数据集就是每个区块内的 Txn 数据,这棵树的 TxnRoot 会记录在区块头里。
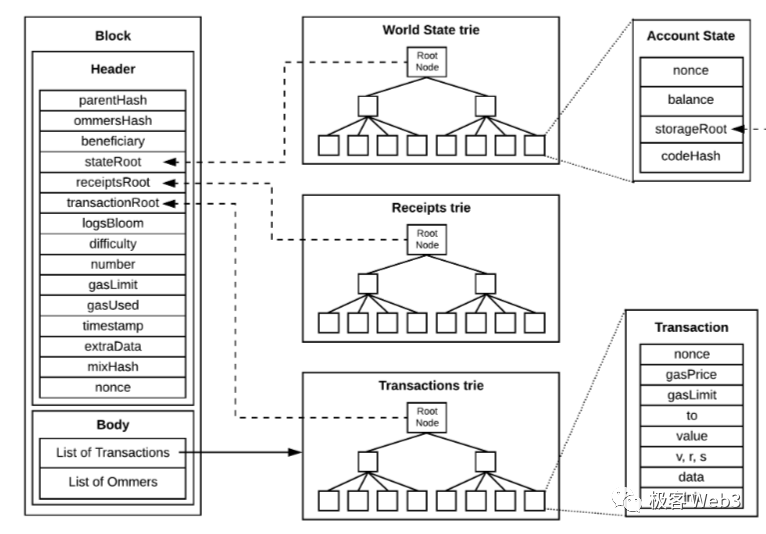
由于轻节点只接收区块头,只知道 StateRoot 和 TxnRoot,不能根据 Root 反推出完整的 Merkle Tree(这是由 Merkle Tree 和哈希函数的性质决定的),所以轻节点无法获知区块内包含的交易数据,也不知道 State Trie 对应的账户发生了哪些变化。
如果王强要向某个轻节点(前面提过的李刚)证明,第 100 号 block 中包含某笔交易,已知轻节点知道 100 号 block 的区块头,知道 TxnRoot,那么上述问题转化为:证明这笔 Txn 存在于 TxnRoot 对应的那棵 Merkle Tree 上。这个时候,王强只要提交对应的 Merkle Proof 即可。
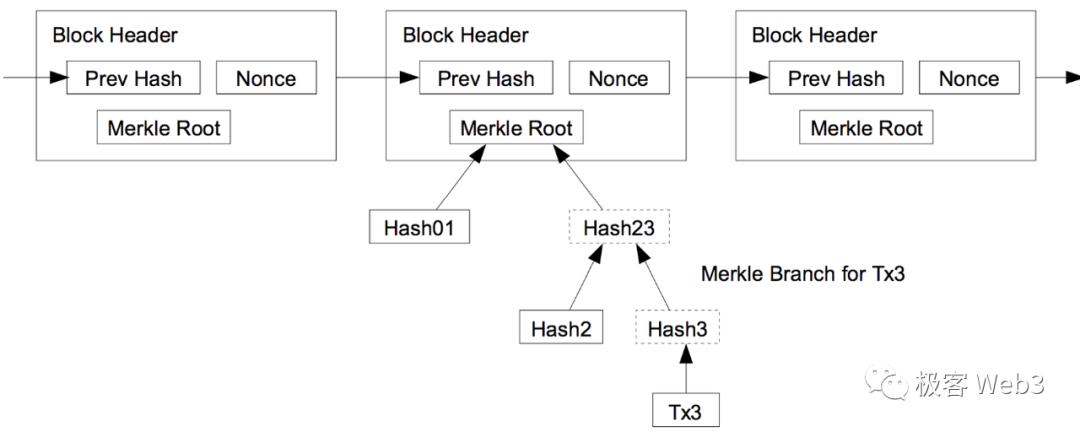
在很多基于轻客户端方案的跨链桥中,常常会用到上面讲到的,轻节点和 Merkle Proof 的轻量与简洁性。比如说,Map Protocol 等 ZK 桥,会在 ETH 链上设置一个合约,专门接收其他链的区块头(比如 Polygon)。当 Relayer 向 ETH 链上的合约,提交 Polygon 第 100 个区块的 header 后,合约会验证 header 的有效性(比如是否凑足了 Polygon 网络内 2/3 POS 节点的签名)。
如果 Header 有效,且某用户声明,自己发起了从 Polygon 到 ETH 的跨链 Txn,该 Txn 被打包进了 Polygon 第 100 个区块。他只要通过 Merkle Proof,证明自己发起的跨链 Txn,能对应上 100 号区块头的 TxnRoot(换句话说,就是证明自己发起的跨链 Txn 在 Polygon 的 100 号区块内有记录)。只不过 ZK 桥会通过零知识证明,压缩验证 Merkle Proof 所需的计算量,进一步降低跨链桥合约的验证成本。
DA 与数据扣留攻击问题
讲完了 Merkle Tree 和 Merkle Root、Merkle Proof,我们回到文章最开头说到的 DA 与数据扣留攻击问题,这一问题早在 2017 年以前就被人探讨过,Celestia 原始论文有对 DA 问题的来源进行考古。Vitalik 本人则在 2017~18 年的一个文档中,谈到出块者可能故意隐瞒 block 的某些数据片段,对外发布不完整的区块,这样一来,全节点就无法确认交易执行 / 状态转换的正确性。
此时,出块者可以盗取用户资产,比如把 A 账户中的币全部划转到别的地址,而全节点无法判断 A 本人是否有这么做,因为他们不知道最新区块包含的完整交易数据。
在比特币或以太坊等 Layer1 公链中,诚实全节点会直接拒收上述无效区块。但轻节点则不同,他们只从网络中接收区块头 Header,只知道 StateRoot 和 TxnRoot,不知道 Header 和两个 Root 对应的的原始区块是否有效。
在比特币白皮书中,其实有对这种情况作出脑洞,中本聪曾认为,大多数用户会倾向于运行配置要求较低的轻节点,而轻节点无法判断区块头对应的 block 是否有效,如果某个 block 无效,诚实全节点会向轻节点发出警报。
但中本聪没有对这个方案进行更细致的分析,后来 Vitalik 和 Celestia 创始人 Mustafa 在这个 idea 之上,结合其他前人的成果,引入了 DA 数据采样,确保诚实全节点能够还原出每个区块的完整数据,并在必要时刻发出警报。

Plasma 的欺诈证明
简单来说,Plasma 是一种只把 Layer2 的区块头发布到 Layer1 上的扩容方案,区块头之外的 DA 数据(完整的交易数据集 / 每个账户的状态变化)只在链下发布。换句话说,Plasma 就像基于轻客户端的跨链桥一样,在 ETH 链上用合约实现了 Layer2 的轻客户端,当用户声明要把资产从 L2 跨到 L1 时,要提交 Merkle Proof,证明自己的确拥有这些资产。
资产从 L2 跨到 L1 的验证逻辑,和前文中谈到的 ZK 桥比较类似,只不过 Plasma 的桥接模型基于欺诈证明,而不是 ZK 证明,更接近于所谓的「乐观桥」。Plasma 网络中从 L2 到 L1 的提款请求不会被立刻放行,而是有一个「挑战期」,至于挑战期的目的是什么,我们会在下面讲解。
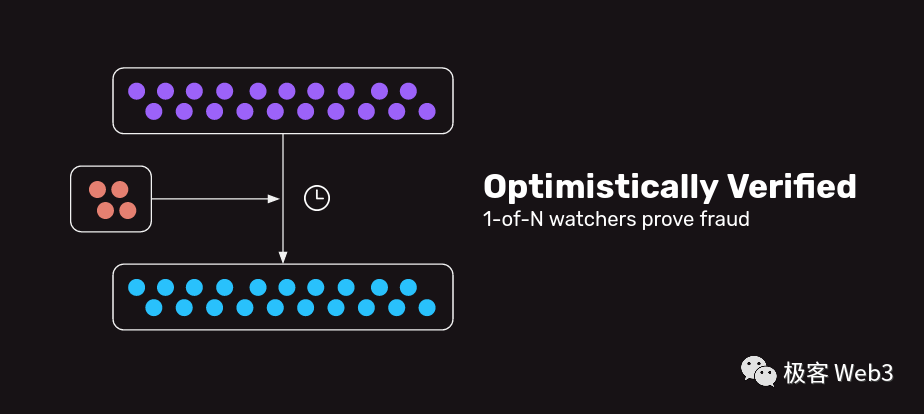
Plasma 对数据发布 /DA 没有严格要求,排序器 /Operator 只是在链下广播每个 L2 区块,有意愿获取 L2 区块的节点去自行获取。之后,排序器会把 L2 区块的 Header 发布到 Layer1。比如说,排序器先在链下广播第 100 号区块,之后把区块的 header 发布到链上。如果 100 号区块中包含无效交易,任何 Plasma 节点都可以在「挑战期」结束前,向 ETH 上的合约提交 Merkle Proof,证明第 100 号区块头能关联到某笔无效交易,这就是欺诈证明涵盖的一个场景。
Plasma 的欺诈证明应用场景还包括以下几种:
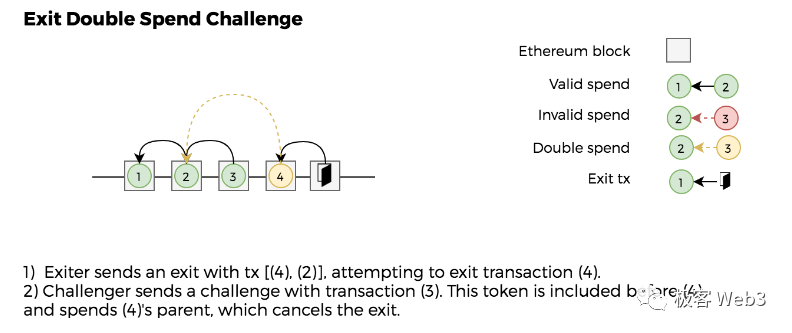
1.假设 Plasma 网络的进度到了 200 号区块,此时 A 用户发起提款声明,称自己在第 100 号区块时,有 10 枚 ETH。但实际上,A 用户在 100 号区块之后,曾把账上的 ETH 花掉。
所以,A 的行为实际上是:花掉 10 枚 ETH 后,声明自己在以前有 10 枚 ETH,并尝试把这些 ETH 提走。这就是典型的「双重提款」,双花。此时,任何人都可以提交 Merkle Proof,证明 A 用户最新的资产状况,不满足其提款声明,也就是证明 A 在 100 号区块后,没有提款声明的那些钱(不同的 Plasma 方案针对这种情况的证明方法不一致,账户地址模型远比 UTXO 的双花证明麻烦的多)。
2.如果是基于 UTXO 模型的 Plasma 方案(过去主要都是这种),区块头中是不包含 StateRoot 的,只有 TxnRoot(UTXO 不支持以太坊式的账户地址模型,也没有 State Trie 这种全局状态设计)。换言之,采用 UTXO 模型的链只有交易记录,没有状态记录。
此时,排序器自身可能发动双花攻击,比如把某个已经被花掉的 UTXO 再花一次,或者给某个用户凭空增发 UTXO。任何一个用户都可以提交 Merkle Proof,证明该 UTXO 的使用记录在过往区块中出现过(被花过),或者证明某个 UTXO 的历史来源有问题。
3.对于 EVM 兼容 / 支持 State Trie 的 Plasma 方案,排序器有可能提交无效的 StateRoot,比如说,在执行了第 100 个区块中包含的交易后,StateRoot 应该转换为 ST+,但排序器往 Layer1 提交的却是 ST-。
这种情况下的欺诈证明比较复杂,需要在以太坊链上重放第 100 号区块中的交易,计算量和需要的输入参数会消耗大量 gas。早期采用 Plasma 的团队难以实现如此复杂的欺诈证明,所以大多采用了 UTXO 模型,毕竟基于 UTXO 的欺诈证明很简洁,也好实现(首个上线欺诈证明的 Rollup 方案 Fuel,就是基于 UTXO 的)
数据扣留与 Exit Game
当然,上述欺诈证明能生效的场景,都是在 DA/ 数据发布有效时,才成立的。如果排序器搞数据扣留,不在链下发布完整的区块,Plasma 节点就无法确认 Layer1 上的区块头是否有效,当然也无法顺利发布欺诈证明。
此时,排序器可以盗取用户资产,比如私自把 A 账户的币全部划转到 B 账户,再从 B 账户给 C 转账,最后用 C 的名义发起提款。B 和 C 账户是排序器自己拥有的,B->C 这笔转账就算对外公示,也无伤大雅;但排序器可以扣留 A->B 这笔无效转账的数据,人们无法证明 B 和 C 的资产来源有问题(要证明 B 的资产来源有猫腻,就要指出「给 B 转账的某笔 Txn」的数字签名有误)。
基于 UTXO 的 Plasma 方案有针对性的举措,比如任何人发起提款时,都要提交资产的全部历史来源,当然后来有更多的改良措施。但如果是 EVM 兼容的 Plasma 方案,会在这块显得软弱无力。因为如果涉及与合约相关的 Txn,在链上验证状态转换过程会产生巨量成本,所以支持账户地址模型和智能合约的 Plasma,不好实现针对提款有效性的验证方案。
此外,抛开上面的话题,无论是基于 UTXO 还是基于账户地址模型的 Plasma,一旦发生数据扣留,基本都会引发人们的恐慌,因为你不知道排序器都执行了哪些交易。Plasma 的节点会发现不对劲,但又无法针对性的发布欺诈证明,因为欺诈证明所需的数据,Plasma 排序器没发出来。
这个时候,人们只能看到对应的区块头,但不知道区块里面都有什么,不知道自己的账户资产变成了什么样,大家会集体发起提款声明,用对应着历史区块的 Merkle Proof 尝试提款,引发被称作「Exit Game」的极端场景,这种情况会导致「踩踏」,使得 Layer1 严重拥堵,并仍会导致一些人资产受损(没有接收到诚实节点通知或者不刷推特的人,根本不会知道排序器正在盗币)。

所以,Plasma 是一种不可靠的 Layer2 扩容方案,一旦发生数据扣留攻击,就会触发「Exit Game」,很容易让用户蒙受损失,这是其被废弃的一大原因。
Plasma 难以支持智能合约的原因
在讲过了 Exit Game 和数据扣留问题后,再来看 Plasma 为什么难以支持智能合约,主要是两个理由:
其一,如果是 Defi 合约的资产,该由谁来提取到 Layer1?因为这本质上就是把合约的状态从 Layer2 迁移到 Layer1,假设有人往 DEX 的 LP 池子充了 100 个 ETH,之后 Plasma 的排序器作恶了,人们要紧急提款,这时候用户的 100 个 ETH 都还为 DEX 合约所控制,请问这个时候这些资产该由谁提到 Layer1 上?
最好的办法,似乎是先让用户从 DEX 赎回资产,再由用户自己去把钱提到 L1 上,但问题是 Plasma 排序器已经作恶了,随时可能拒绝用户请求。
那么,如果我们事先给 DEX 合约设置 Owner,允许他在紧急情况下,把合约资产提到 L1 上呢?显然这会赋予合约 Owner 以公共资产的所有权,他可以随时把这些资产提到 L1 上并跑路,这岂不是太可怕了?
显然,该怎么处置这些由 Defi 合约所支配的「公共财产」,是一个巨大的雷。这其实涉及到公权力分配的难题,此前响马曾在访谈《高性能公链难出新事,智能合约涉及权力分配》中谈到过这点。

其二,如果不允许合约迁移状态,会使其蒙受巨额损失;如果允许合约把自己的状态迁移到 Layer1,会出现 Plasma 欺诈证明难以解决的双重提款:
比如,我们假设 Plasma 采用以太坊的账户地址模型,支持智能合约,有一个混币器,目前存入了 100 枚 ETH,混币器的 Owner 由 Bob 控制;
假设 Bob 在第 100 个区块时,从混币器提走 50 枚 ETH。之后 Bob 发起提款声明,把这 50 枚 ETH 跨到了 Layer1 上;
之后,Bob 用过去的合约状态快照(比如第 70 个区块),把混币器过去的状态迁移到 Layer1 上,这会把混币器「曾经拥有」的 100 枚 ETH 也跨到 Layer1 上;
显然,这是典型的「双重提款」,也就是双花。有 150 枚 ETH 被 Bob 提到了 Layer1,但 Layer2 网络用户只向混币器 /Bob 付出 100 枚 ETH,有 50 枚 ETH 被凭空抽走。这很容易把 Plasma 的储备金抽干。理论上人们可以发起欺诈证明,证明混币器合约的状态在第 70 个区块之后有变化。
但假如在第 70 号区块之后,所有和混币器合约产生交互的 Txn,都没有改变合约状态,除了 Bob 抽走 50 枚 ETH 那笔交易;如果你要出示证据,指出混币器合约在第 70 号区块后有变化,就要在以太坊链上把上述提及的所有 Txn 跑一遍,最终才能让 Plasma 合约确定,混币器合约状态的确发生过变化(之所以这么复杂,是由 Plasma 本身的构造决定的)。如果这批 Txn 数量极大,欺诈证明根本无法在 Layer1 上发布(会超出以太坊单个区块的 gas 上限)。

理论上来说,上面的双花场景中,似乎只要提交混币器当前的状态快照(其实就是对应 StateRoot 的默克尔证明),但实际上,由于 Plasma 不在链上发布交易数据,合约无法确定你提交的状态快照是否有效。这是因为排序器自己可能发动数据扣留,提交无效的状态快照,恶意指证任何一名提款者。
比如说,当你声明自己账上有 50 枚 ETH 并发起提款时,排序器可能私自把你账户清 0,然后发动数据扣留,把一个无效的 StateRoot 发到链上,并提交对应的状态快照,诬告你账户里没钱了。这个时候大家没法证明排序器提交的 StateRoot 和状态快照无效,因为他发动了数据扣留,你得不到欺诈证明需要的足量数据。
为了防止这种情况,Plasma 节点在出示状态快照证明某人有双花行为时,还要重放这段时间内的交易记录,这可以防止排序器用数据扣留来阻止别人提款。而在 Rollup 中,如果遇到上述双重提款,理论上不需要重放历史交易,因为Rollup 不存在数据扣留问题,会「强制要求」排序器在链上发布 DA 数据。Rollup 排序器如果提交一个无效 StateRoot- 状态快照,要么无法通过合约验证(ZK Rollup),要么很快就会被挑战(OP Rollup)。
其实除了上面谈到的混币器的例子外,多签合约等场景一样可以导致 Plasma 网络发生双重提款。而欺诈证明对这种场景的处理效率很低。在 ETH Research 中有对这种情况作出分析。
综上所述,由于 Plasma 方案不利于智能合约,基本不支持合约状态迁移到 Layer1,主流的 Plasma 只好选用 UTXO 或类似的机制,因为 UTXO 不存在资产所有权冲突问题,并且能很好的支持欺诈证明(尺寸小很多),但代价是应用场景单一,基本只能支持转账或者订单簿交易所。
此外,因为欺诈证明本身对 DA 数据有较强的依赖,如果 DA 层不可靠,将难以实现高效率的欺诈证明系统。而 Plasma 对于 DA 问题的处理太简陋,无法解决数据扣留攻击问题,随着 Rollup 的崛起,Plasma 慢慢就淡出了历史舞台。





 个人中心
个人中心 退出登录
退出登录 ONDO0.39 -5.49%
ONDO0.39 -5.49%
 TRUMP5.15 -2.24%
TRUMP5.15 -2.24%
 SUI1.43 -5.31%
SUI1.43 -5.31%
 TON1.48 -4.46%
TON1.48 -4.46%
 TRX0.28 -0.42%
TRX0.28 -0.42%
 DOGE0.13 -3.64%
DOGE0.13 -3.64%
 XRP1.88 -2.59%
XRP1.88 -2.59%
 SOL123.18 -3.75%
SOL123.18 -3.75%
 BNB844.16 -3.10%
BNB844.16 -3.10%
 ETH2825.66 -4.26%
ETH2825.66 -4.26%
 BTC86094.32 -1.76%
BTC86094.32 -1.76%




 首页
首页 深潮精选
深潮精选 Research
Research 项目发现
项目发现 7x24h︎快讯
7x24h︎快讯 最新活动
最新活动
 分享至微信
分享至微信
 原文链接
原文链接 添加收藏
添加收藏 分享社交媒体
分享社交媒体
 @godrealmx
@godrealmx 精选解读
精选解读

 原创
原创 River:S3 快照将于 12.19 进行,S4 将于 12.22 启动
River:S3 快照将于 12.19 进行,S4 将于 12.22 启动





 扫码关注公众号
扫码关注公众号





