ZK 协处理器能让区块链委托进行这种数据密集型的繁琐计算,并以低成本迅速获得结果,而且不需要任何额外的信任假设。
ZK 协处理器是区块链领域一项激动人心的创新。它由 Brevis、Axiom、Lagrange 和 Herodotus 等项目率先推出,有望彻底革新我们在区块链上开发应用的方式。有了 ZK 协处理器,开发人员可以创建数据驱动的 dApps,可以利用 omnichain 数据的历史记录来执行复杂的计算,而不需要依赖任何额外的信任假设。更为重要的是,它引领了一种新的开发模式:异步应用架构,这为 Web 3.0 软件框架带来了前所未有的效率和可扩展性。
在本系列文章中,我们将揭示 ZK 协处理器的神秘面纱。无论您是对其理念、实际应用、基础机制、面临的挑战,还是市场策略感兴趣,或是想要比较不同的项目,我们希望这些文章都能给您带来新的启发。
DEX 上缺少 VIP 交易员计划的案例
要理解 ZK 协处理器的基本思想,我们需要从现实世界中的激励性实例开始。
中心化交易所(CEX)和去中心化交易所(DEX)之间的一个明显区别是存在基于交易量的收费标准,也就是通常所说的 "VIP 交易员忠诚度计划"。这些计划是留住交易者、提高流动性并最终增加交易所收入的有力工具。

有趣的是,虽然每个 CEX 都拥有至少一个这样的项目,但 DEX 却完全没有。为什么呢?
这是因为在 DEX 中实现这一功能要比在 CEX 中更具挑战性,成本也更高。
在 CEX 中,实施忠诚度项目需要:
然而,DEX 在尝试遵循相同步骤时面临着重大挑战:
你可能会说 "等等,你到底在说什么?在区块链上,每个用户的每笔交易都已自动存储(因为它是区块链!)。在区块链上土生土长的智能合约,应该可以随时访问所有这些数据,对吧?
很遗憾,不对!
区块链存储的数据和区块链虚拟机内智能合约可访问的数据完全是两码事。
对于区块链的完整/存档节点来说,它们存储了区块链历史上的大量数据。通过这些节点,您可以轻松访问:
-
历史上任何给定时间内整个区块链的状态(例如,谁是 Cryptopunk 的第一个所有者)。
-
历史上任何给定时间内的交易和因交易而产生的事件(例如,Charlie 将 $1,000 兑换成 0.5 ETH)。
事实上,流行的链外数据索引或分析工具(如 Nansen 和 Dune Analytics)可利用这一广泛的数据集进行深入分析。

然而,对于嵌入区块链虚拟机的智能合约来说,数据访问的限制要大得多。它们不能使用链外索引解决方案生成的数据,因为这会给这些外部且通常是中心化的索引解决方案带来额外的信任问题。
事实上,智能合约只能轻松且无需信任地访问以下数据:
上述说法的一个关键细微差别在于 "轻松 "一词。
智能合约并非完全不知道区块链上的全部数据。在 EVM 中,智能合约可以访问最新 256 个区块的区块头哈希值。这些区块头囊括了区块链上截至当前区块的所有活动,并通过默克尔树和 Keccak 哈希值浓缩成 32 字节的哈希值。
压缩过的东西可以解压缩...只是并不容易 😂
试想一下,如果想利用最近的区块头,无需信任地访问上一个区块中的特定数据。这种方法包括从存档节点获取链外数据,然后构建默克尔树和区块有效性证明,以确定数据在区块链中的真实性。然后,EVM 对有效性证明进行处理,以进行验证和解释。这样的操作既繁琐又艰巨,仅仅为了检索过去的几个代币余额,就可能消耗数千万 Gas。
这一挑战的根源在于,区块链虚拟机本身不具备处理数据量大和密集型计算(如上述解压缩任务)的能力。
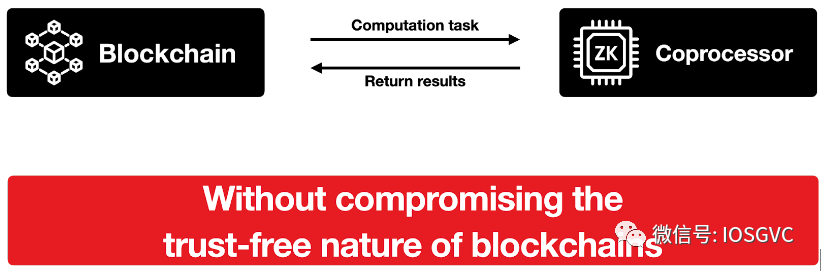
ZK 协处理器架构
(资料来源: Brevis 在 ETHSG 的演示幻灯片)
如果有一种魔法,能让区块链委托进行这种数据密集型的繁琐计算,并以低成本迅速获得结果,而且不需要任何额外的信任假设,那就再理想不过了。
朋友,这正是 ZK 协处理器的用途所在。
“协处理器”这一名称的灵感来源于计算机架构的发展史。例如,GPU 作为 CPU 的协处理器被引入,是因为 CPU 必须将某些昂贵且自身难以运行的重要计算任务(如图形计算或人工智能训练)下放给 "辅助处理器",即 GPU。
但是,ZK 协处理器中的 "ZK "又是什么意思呢?在深入探讨复杂的技术细节之前,让我们先来了解一下这项创新技术的广泛意义和潜力。
我们需在Web 3.0中数据驱动的 dApps
交易费返还就是一个很好的例子。按照这一思路,有了 ZK 协处理器,就可以在众多 DeFi 协议中无缝引入各种忠诚度计划。
然而,这远不止 DeFi 忠诚度计划。您现在也许可以看到,Web 3.0 的其他领域也存在同样的问题。仔细想想,所有现代 Web 2.0 应用程序都是数据驱动的,而 Web 3.0 应用程序却无一例外。要想打造 "杀手级应用",让用户体验与传统互联网应用相媲美,这种数据驱动方法是不可或缺的。
让我们看看 DeFi 领域的另一个例子:通过重新设计流动性挖矿奖励机制来提高流动性效率。
目前,AMM DEX 上的流动性激励机制采用 "现收现付 "模式。在这种模式下,当 LP 贡献流动性时,Farming 奖励即刻分配给 LP。然而,这种模式远非最佳。专业 Farmer 在感觉到市场波动时,可以迅速撤回流动资金,以避免无常损失。这样一来,他们为协议提供的价值微乎其微,但仍能获得可观的回报。
理想的 AMM 流动性激励机制会对 LP 的坚定性进行追溯评估,尤其是在市场大幅波动期间。那些在这种情况下始终支持资金池的人应该获得最高奖励。然而,获取对这一模型至关重要的 LP 历史行为数据,在今天仍然是不可行的。
要做到这一点,你需要 ZK 协处理器。
在 DeFi 领域,我们可以举出很多类似的例子,无论是使用预定算法和规则进行主动 LP 头寸管理,使用非代币流动性头寸建立信贷额度,还是根据过去的还款行为确定贷款的动态清算偏好。
然而,ZK 协处理器的潜力不仅限于 DeFi。
利用 ZK 协处理器打造具有出色用户体验的链上游戏
Web 2.0 游戏实时操作功能示例
当你进入一款新安装的 Web 2.0 游戏时,你的一举一动都会被详细记录下来。这些数据不会被闲置,而是会很大程度影响你的游戏之旅。它决定何时为你提供游戏内购买选项,何时推出奖励游戏,何时向你发送措辞经过精心设计的推送通知,以及与你匹配的对手等等。这些都是游戏行业所说的实时运营(LiveOps)的组成部分,是提高玩家参与度和收入流的基石。
要使完全链上游戏的用户体验与 Web 2.0 经典游戏相媲美,就需要这些 LiveOps 功能。这些功能应基于玩家与游戏智能合约的历史互动和交易。
遗憾的是,在区块链游戏中,这类功能要么完全缺失,要么仍由中心化解决方案驱动。原因与 DEX 的例子如出一辙:难以在区块链上挖掘和计算历史游戏数据。
是的,同样,你需要 ZK 协处理器来实现这一点。
Web 3.0 社交和身份识别应用是另一个没有 ZK 协处理器支持就无法运行的领域。

在区块链世界中,您的数字身份是由您过去的行为编织而成的一张网。
-
想证明自己是 NFT OG?你得证明你是 Cryptopunk 的原始矿工之一。
-
吹嘘自己是个大交易员?向我证明你在 DEX 上支付了超过 100 万美元的交易费。
-
和 Vitalik 关系密切?向我证明他的地址向你的地址发送过资金。
链下系统,无论是人类还是 Web 2.0 应用程序,都可以轻松生成这种证明,因为就像交易量的例子一样,它们可以访问包含所有这些数据的存档节点。
基于这种直接数据访问的身份证明需要强大的钱包地址关联,因此也需要承担其牺牲隐私的缺点,但它确是可行的。
然而,就像在交易量的例子中一样,如果你想让智能合约相信你的 OG 身份,并在不引入额外信任证明的情况下抢先体验一些新玩意,其实根本就没有什么好办法。
有了 ZK 协处理器,您就可以编织出一个可靠的身份证明,一个您过去行为的证明,一个任何智能合约都会毫无疑问地接受的证明。您在不同应用程序甚至不同区块链上的互动都可以巧妙地合并起来,形成这一证明。
更吸引人的是 ZK 固有的隐私性。您的钱包地址不必与您的身份公开关联。例如,你可以证明自己拥有 Cryptopunk NFT,而无需透露具体的钱包地址。或者,你可以证明在 Uniswap 上执行过 10,000 次交易,但不透露具体数字。
ZK 协处理器为数据驱动的 dApp 构建开辟了一个全新的领域,但它的意义远不止于此。
超越数据驱动范式:用 ZK 协处理器开创 Web 3.0 异步模式

数据驱动的 dApp 模式虽然很吸引人,但只是冰山一角。
ZK 协处理器的出现将彻底改变我们对区块链计算的看法,开创一个异步处理成为 Web 3.0 标准的时代。这种转变重新定义了任务的处理方式,专门的处理器可以独立运行,从而提高效率。
让我们先来了解一下什么是异步处理。
想象一下,在一家同步餐厅里,一个人同时扮演厨师和服务员的角色。你点了菜,他就开始准备,让你等着。他只能在为您上完菜后,再去招呼另一位客人。虽然这种设置可能会满足你的需求,但对其他人来说却很难提高效率。
相比之下,在异步餐厅中,不同的厨师和不同的服务员协同工作。服务员在接受您的订单后,会迅速将订单转交给厨师,同时为其他顾客提供服务。菜肴完成后,厨师向服务员发出信号,服务员随即为您上菜。
在计算机系统中:
同步架构就像第一家餐厅一样,一个人等待每项任务完成后再继续。这种架构简单明了,但速度可能较慢,因为它一次只处理一项任务。而且,这个人可能是个好服务员,但不是个好厨师。
异步架构就像第二家餐厅,其中有一些解耦和专门的系统组件,它们相互发送信息和任务,作为一种协调方式。这允许每个组件同时管理自己的任务线。虽然可能需要更复杂的管理方法,但这种架构速度更快,效率更高。
每一个现代互联网应用程序都是基于异步架构构建的,以提高效率和可扩展性,我们认为 Web 3.0 也应如此。
ZK 协处理器将成为这一变革的先驱。对于 dApp 开发者来说,区块链就像我们异步餐厅里的服务员。它主要处理直接改变区块链状态的计算,如或有资产所有权变更。所有其他计算都应交由稳健的 ZK 协处理器处理,它们就像精通厨艺的厨师一样,通过异步处理的强大功能,高效地烹饪出结果并发送给服务员。
具体来说,如果区块链应用中的计算符合以下两个 "可行条件 "之一,就应考虑使用 ZK 协处理器。
ZK 协处理器可执行条件:
即使它们只符合其中之一,也值得考虑!
现在你就可以看到,它不仅仅是数据驱动的 dApps!它是一种将 ML 等高水准通用计算引入区块链的全新方式,但更重要的是,它引入了改变模式的异步架构来构建 dApp,这在以前是根本不可能实现的。





 个人中心
个人中心 退出登录
退出登录 ONDO0.41 0.78%
ONDO0.41 0.78%
 TRUMP5.27 -0.37%
TRUMP5.27 -0.37%
 SUI1.51 4.00%
SUI1.51 4.00%
 TON1.54 4.26%
TON1.54 4.26%
 TRX0.28 0.77%
TRX0.28 0.77%
 DOGE0.13 2.62%
DOGE0.13 2.62%
 XRP1.93 1.84%
XRP1.93 1.84%
 SOL128.57 2.25%
SOL128.57 2.25%
 BNB872.43 2.30%
BNB872.43 2.30%
 ETH2954.33 0.38%
ETH2954.33 0.38%
 BTC87822.66 1.87%
BTC87822.66 1.87%




 首页
首页 深潮精选
深潮精选 Research
Research 项目发现
项目发现 7x24h︎快讯
7x24h︎快讯 最新活动
最新活动
 分享至微信
分享至微信
 原文链接
原文链接 添加收藏
添加收藏 分享社交媒体
分享社交媒体
 IOSG Ventures
IOSG Ventures 精选解读
精选解读

 加密交易所Paxful:拟于明年2月出庭接受量刑并将返还用户剩余资金
加密交易所Paxful:拟于明年2月出庭接受量刑并将返还用户剩余资金





 扫码关注公众号
扫码关注公众号





